This report looks in depth at some of the clusters of Decred addresses that my clustering code is producing - specifically at Politeia votes by tickets belonging to these clusters, where the cluster seems to have voted both for and against the proposal.
From a common sense perspective, people either like the proposal or they don’t - or they simply don’t care and don’t vote. Voting for and against the same proposal is harder to explain, unless the voter changed their mind while they were “trickling” votes.
From a technical perspective, Decrediton doesn’t offer the possibility of voting for and against a proposal with different tickets controlled by the same wallet. However, the politeiavoter command line interface (CLI) tool offers much more flexibility with regard to voting, most notably the feature which allows for “trickling” of votes. This feature allows the user to specify an interval over which tickets will vote at random intervals - it is designed to protect users’ privacy, specifically against the analysis of vote timing being used to link tickets controlled by the same wallet (which would be trivial if they all voted at the same time).
When I explained this finding about clusters with tickets voting both ways in the #research channel, it was suggested that the most likely explanation was dodgy clusters that have associated tickets which are actually controlled by different wallets. This seemed like quite a plausible explanation to me, so I embarked upon what turned into a deep rabbit hole of testing my clustering code.
There are two objectives of this investigation:
- Establish whether the same wallet ever votes for and against a proposal with different tickets that it controls.
- Establish whether and where this pattern indicates a problem with the clusters produced by my code.
The report is mostly notes on how I improved my clustering code, but there are reliable Politeia voting plots for clusters at the end which are of more general interest. Writing this report about the process has also helped me to take some of the last steps to understanding what was going wrong.
“Enhanced” clusters have an obvious problem
I found this problem when I was making some functions to plot the Politeia votes of clusters of tickets. At the time I was working with “enhanced” clustering code, and it is within a few of the larger clusters here where the problem became apparent. The clustering I used for previous reports was limited to linking addresses which were common inputs to a transaction, and linking ticket and vote addresses. The “enhanced” code sought to also include the addresses from which a cluster’s ticket-buying DCR originated, as the step of preparing the inputs for ticket purchases is, I reckoned, always completed by the same wallet that buys and controls the tickets. The enhanced code also collected addresses associated with the outputs of votes, filtering out VSP fee payments.
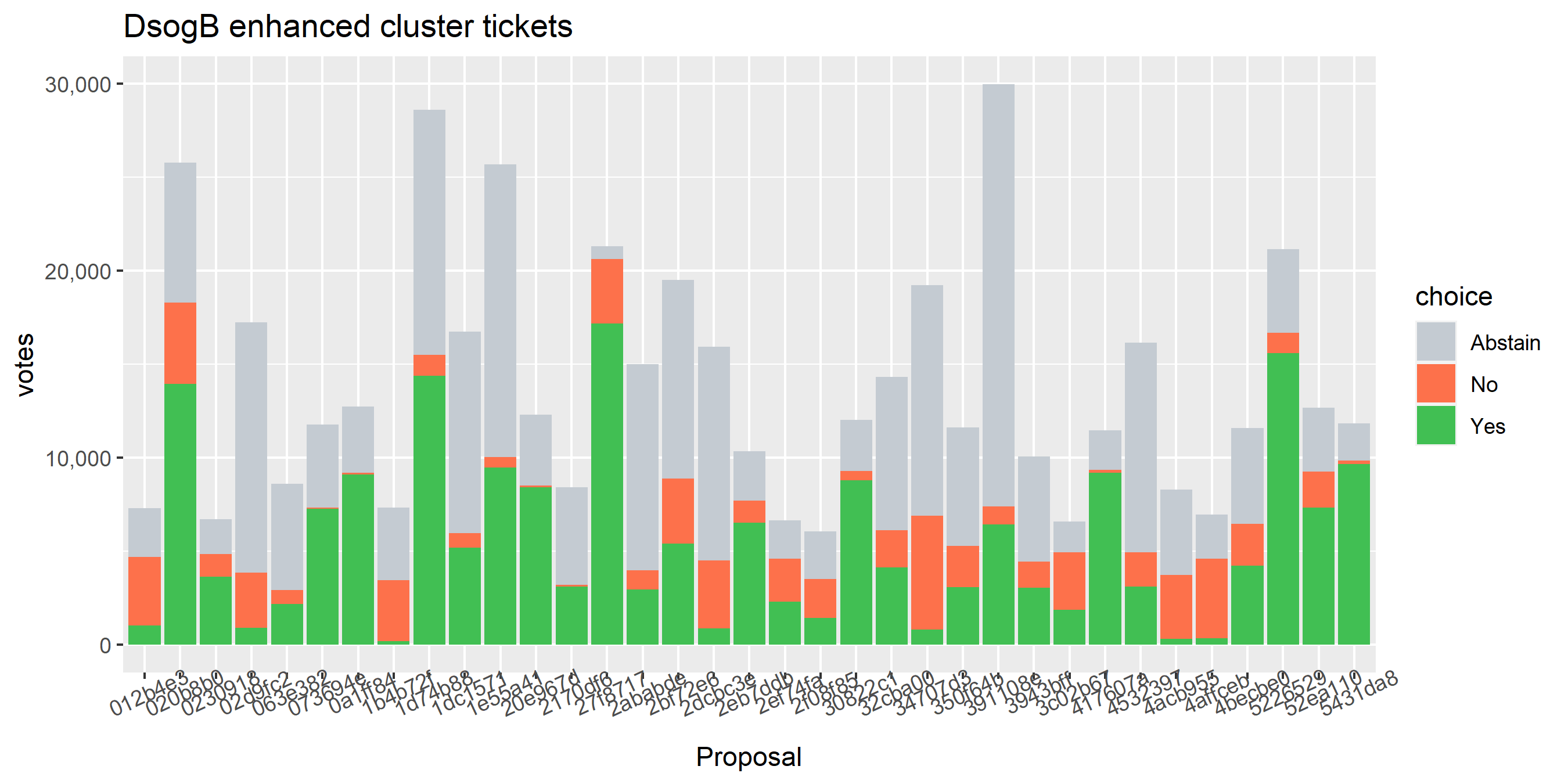
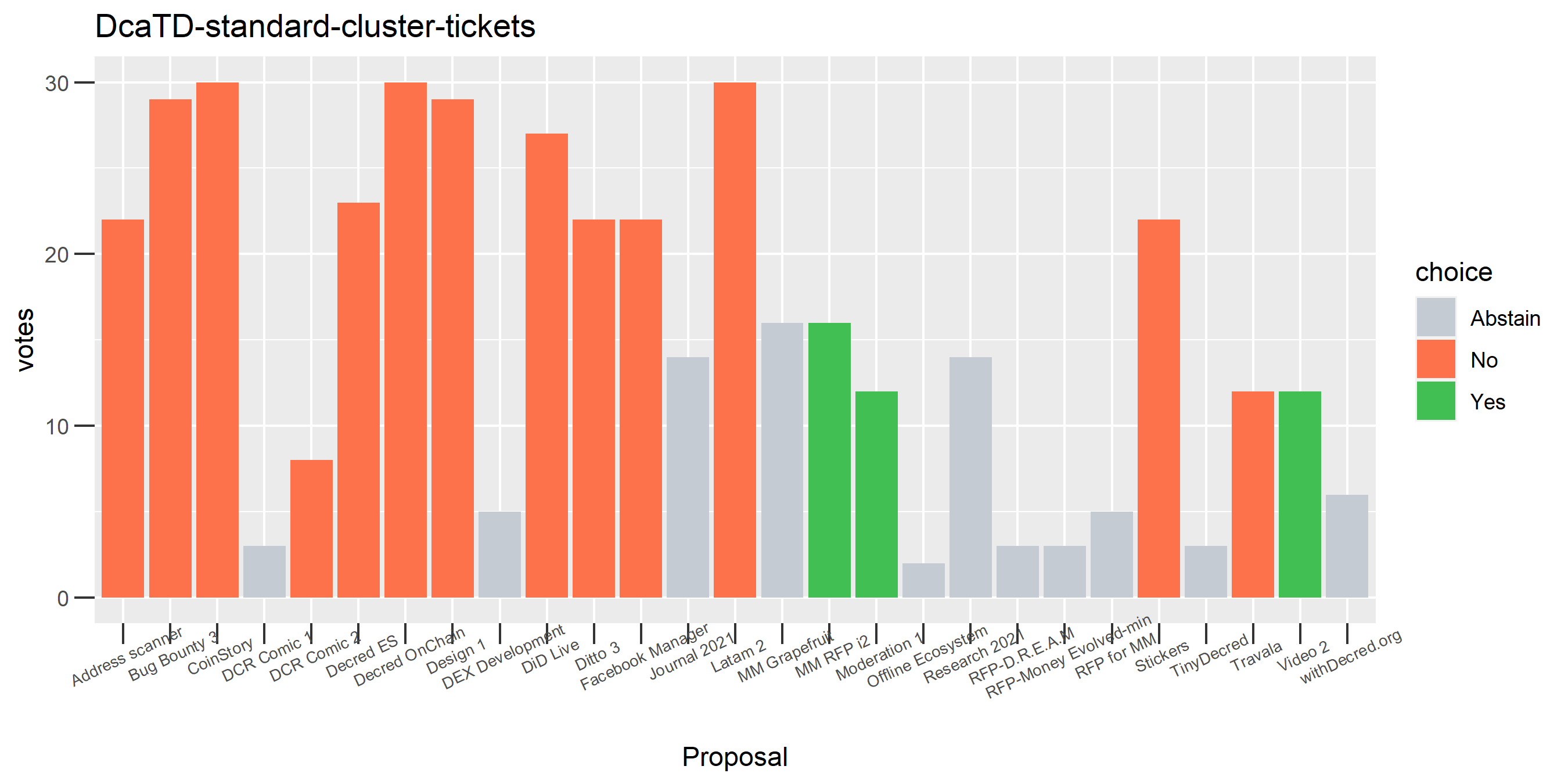
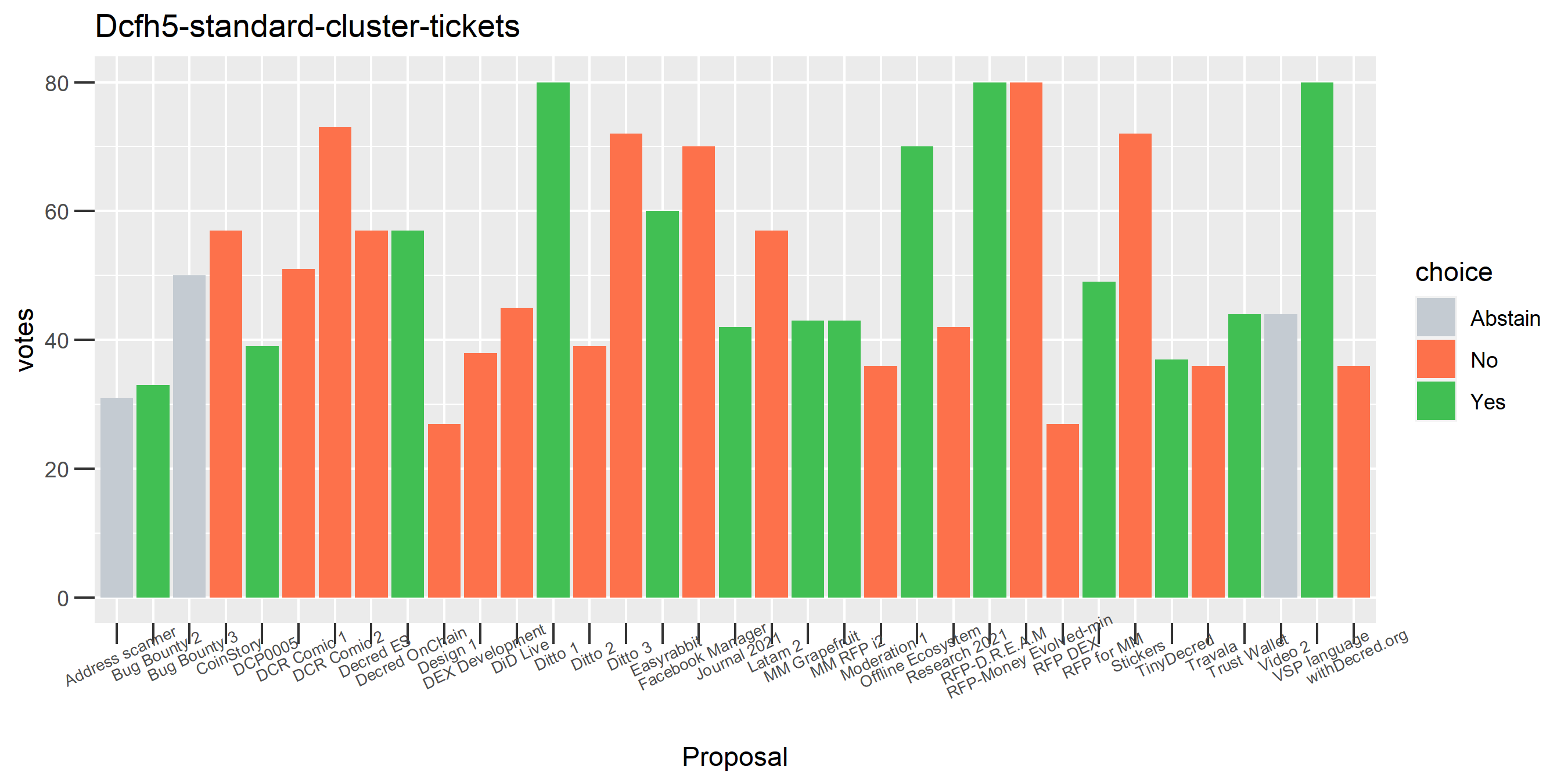
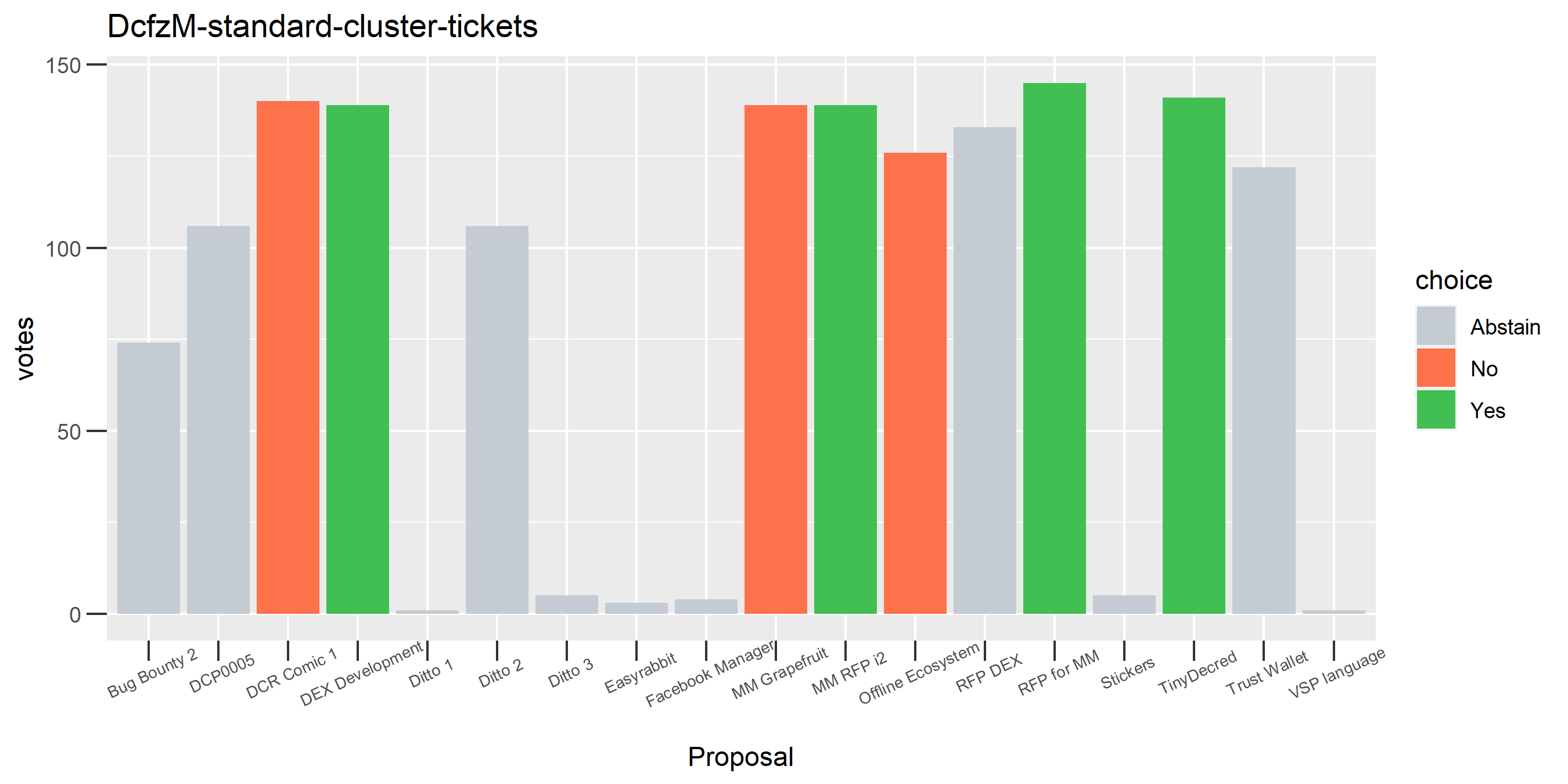
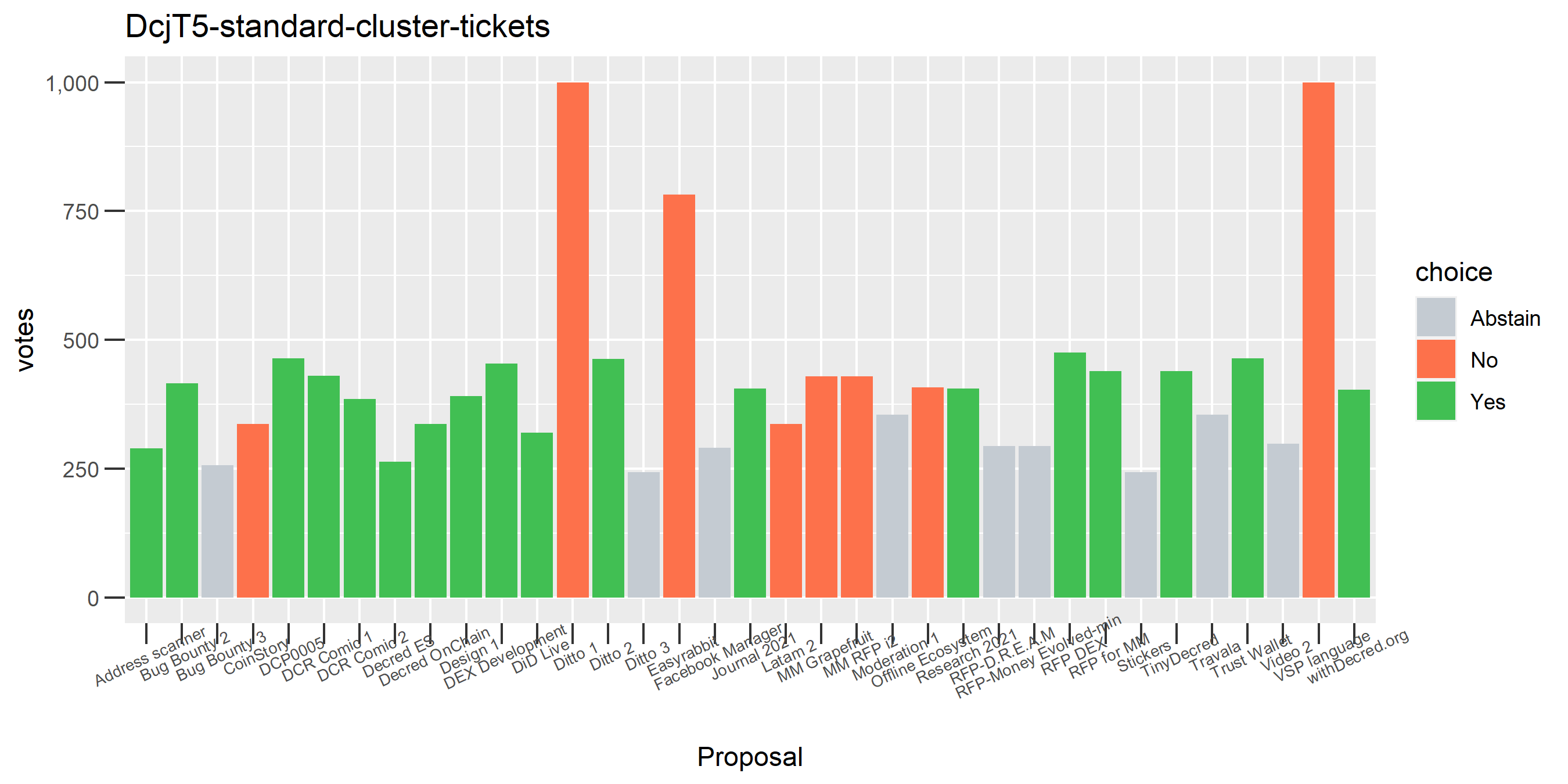
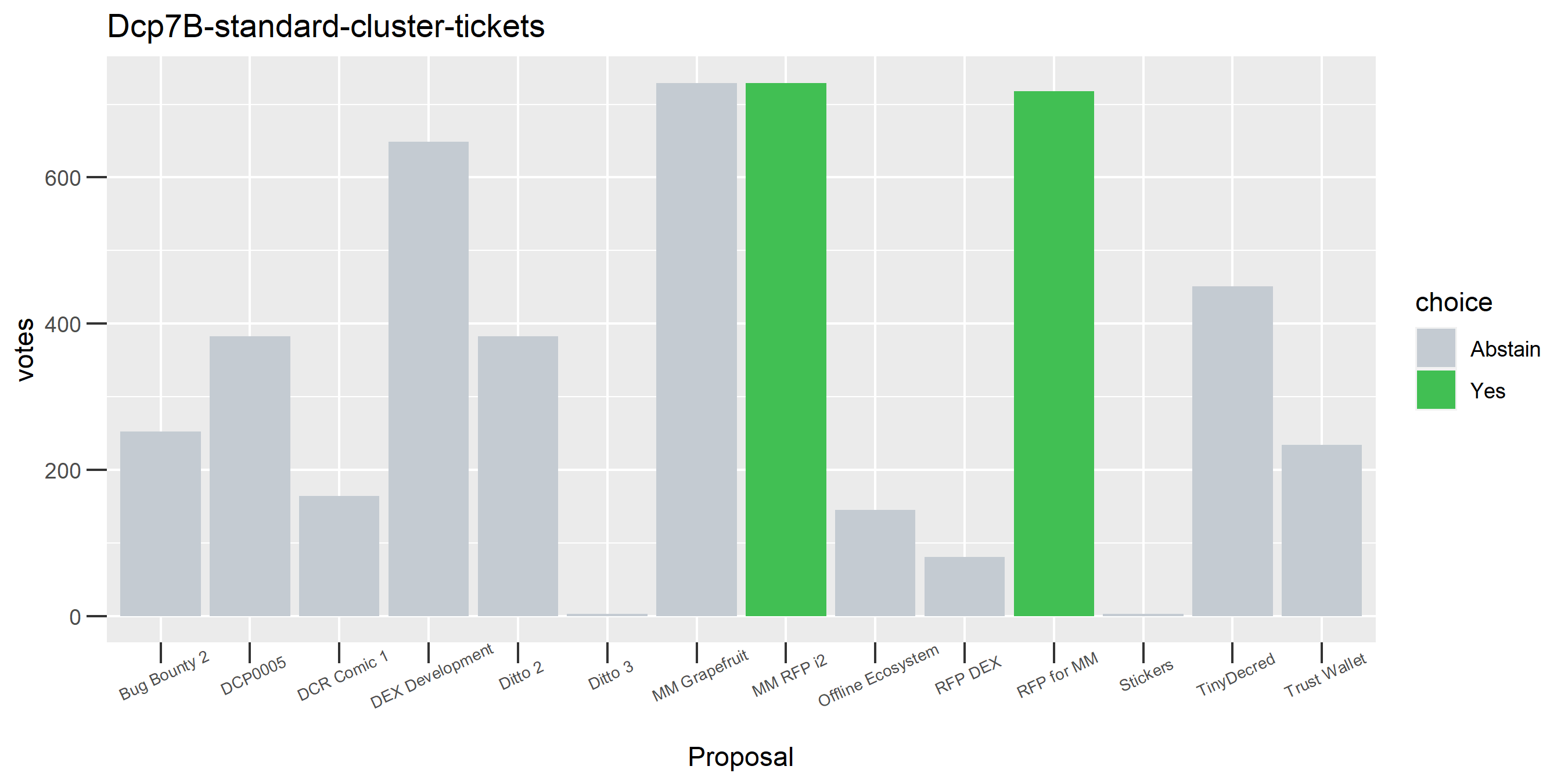
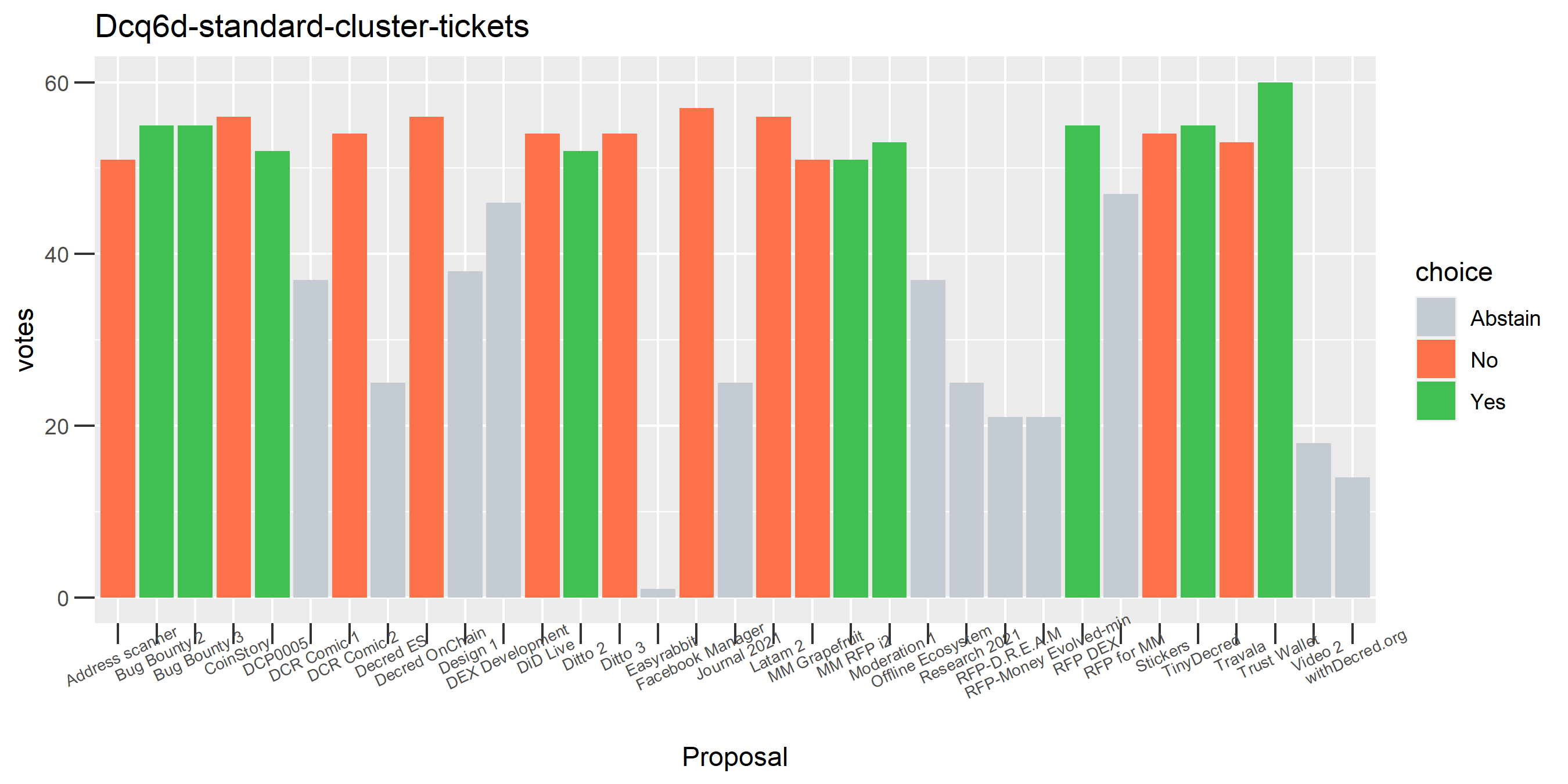
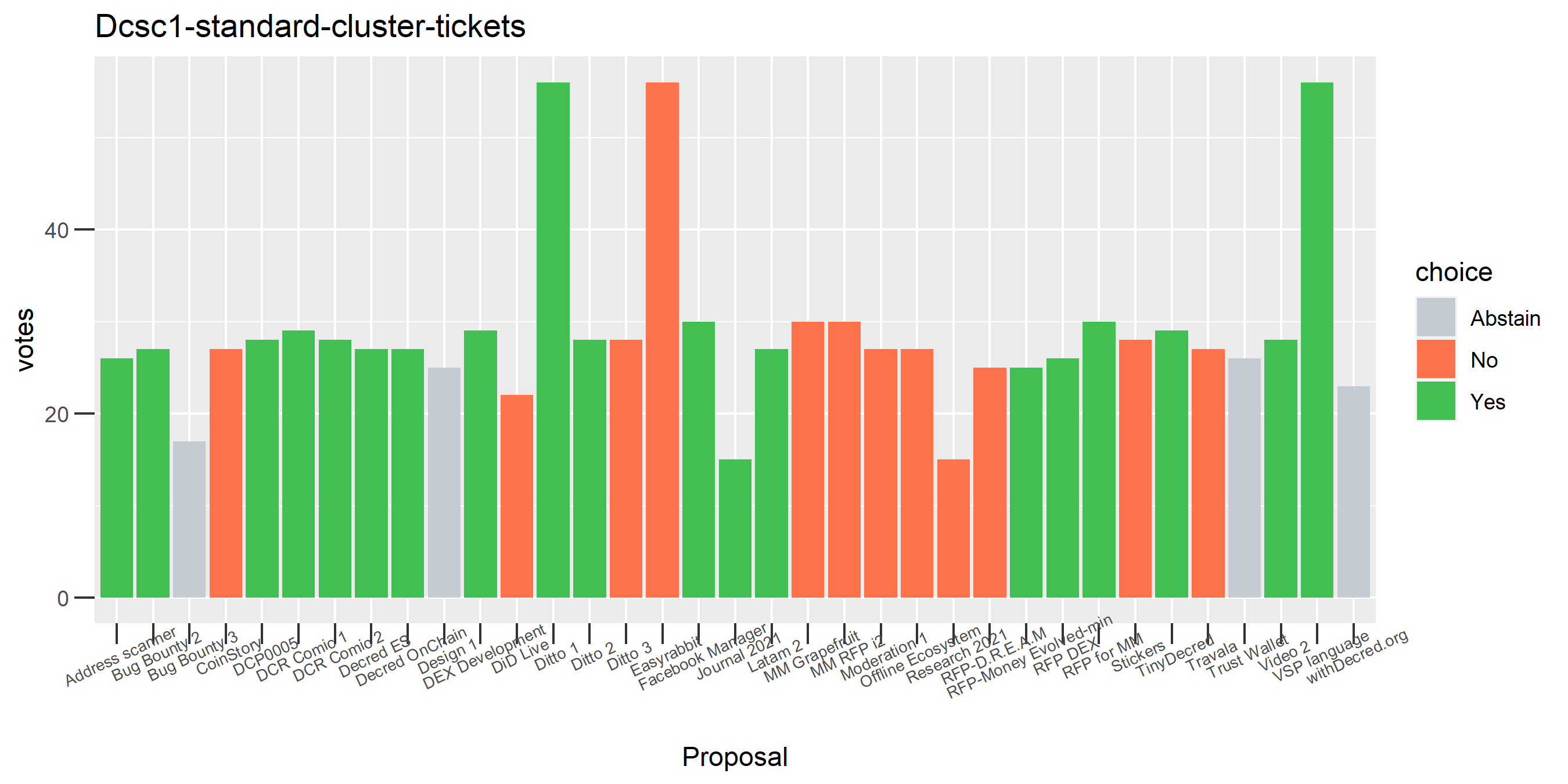
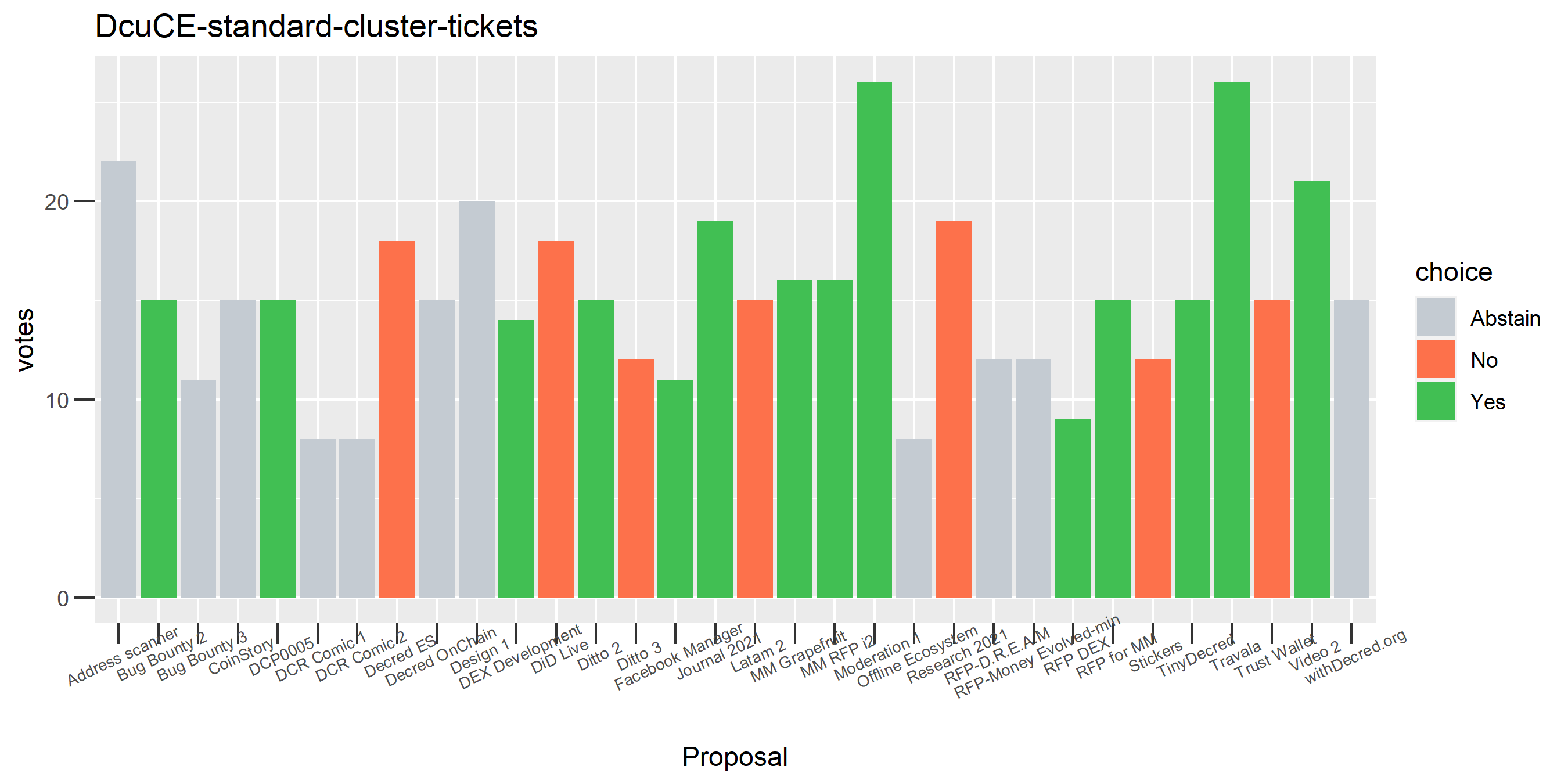
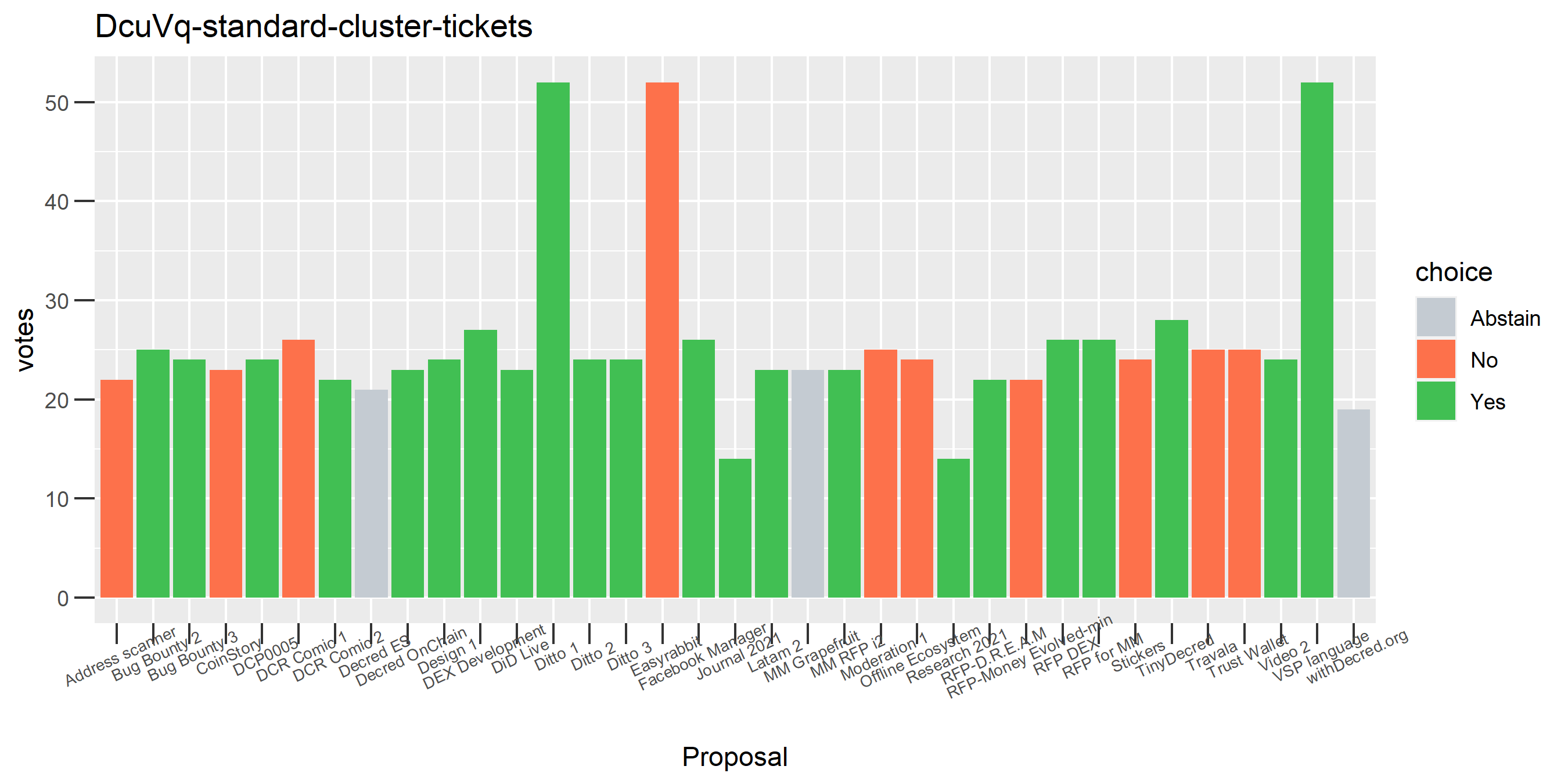
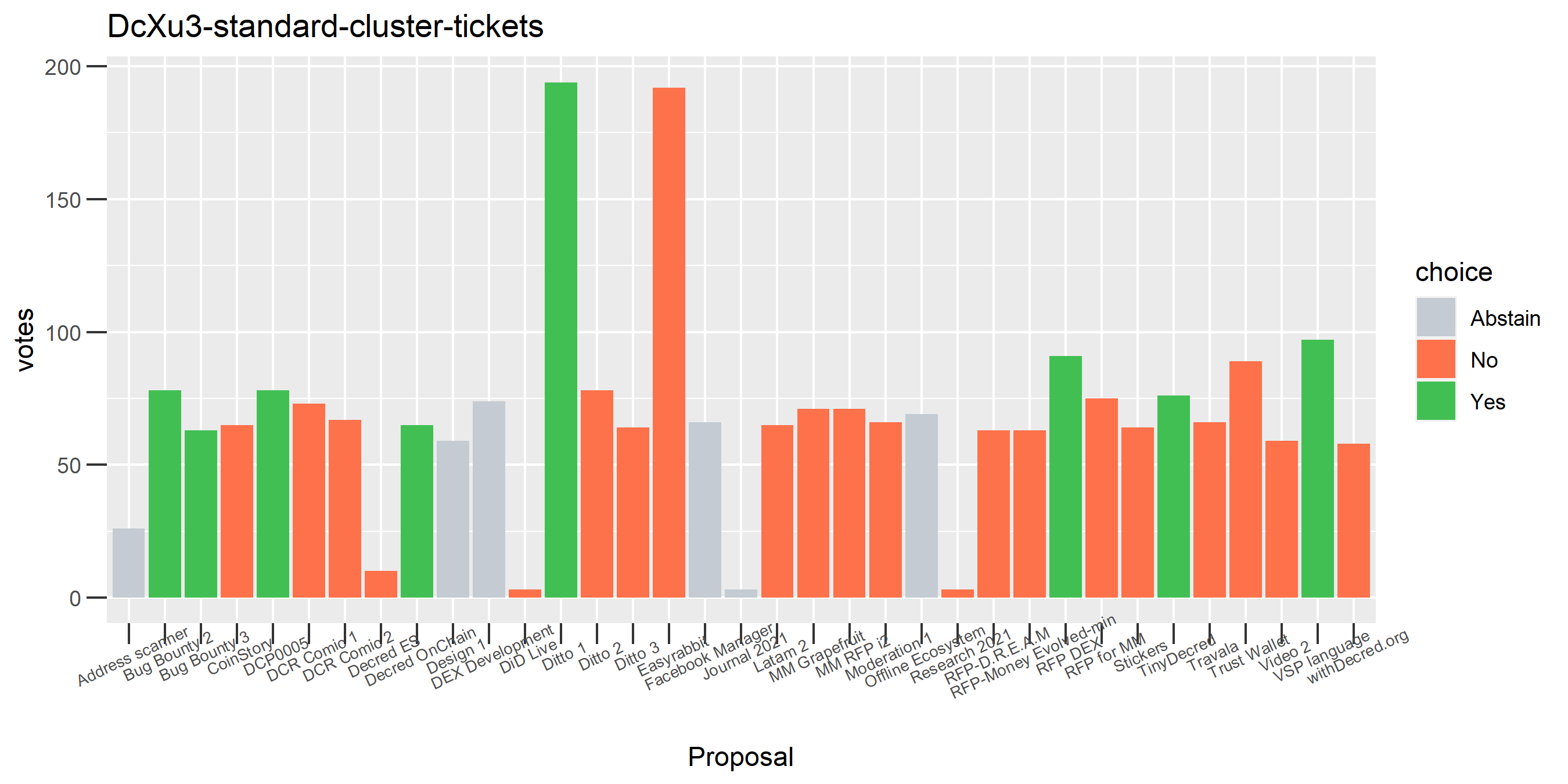
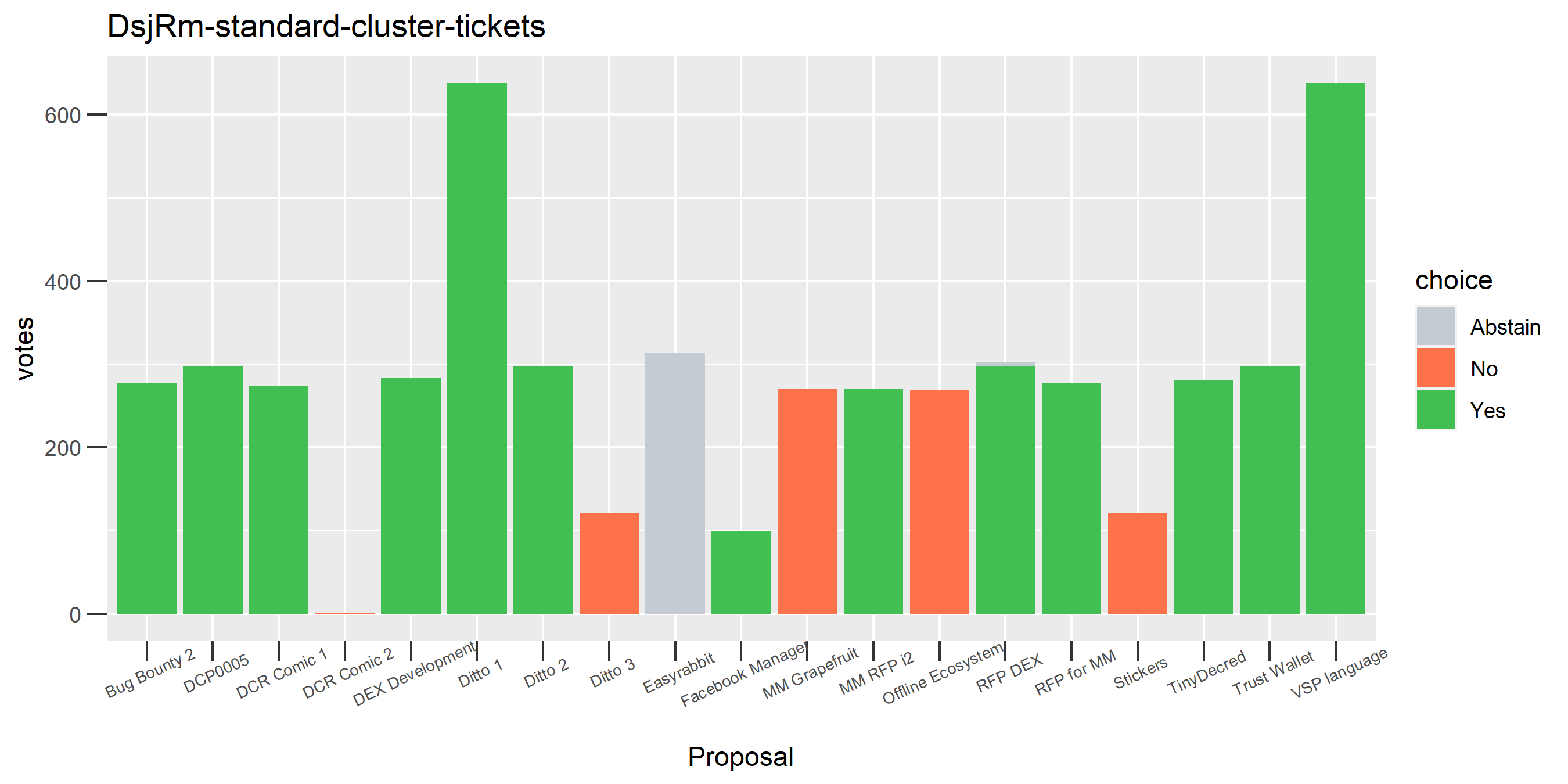
This plot shows the Politeia voting (and eligible tickets) of one of the enhanced clusters which had the most of these conflicting votes - on almost every proposal it voted on, there are votes in both directions. While it is conceivable that someone might change their vote on a proposal or deliberately vote both ways some of the time, it seems highly unlikely that a stakeholder would vote in both directions every time they voted. The scale of the voting activity in this plot is also a clear indication that something was going very wrong - it is attributing a big chunk of the unmixed staked DCR to a single actor.
So, I wrote some code which would check all of the “enhanced” clusters to see which of them manifested this sort of problem (voting for and against the same proposal).
I was doing this against the backdrop of analysis of two ticket pool snapshots, and as part of this had identified 41,508 “enhanced clusters” from both pools combined. After running all of these through a function which checked them for contradictory voting, there were just 108 clusters which exhibited this behavior at any point in their voting history (the selection of clusters was based on two block heights, but for all the selected clusters their entire voting history was considered).
So, at this point I’m thinking there’s a problem with a few of the larger enhanced clusters, and I wrote some new code that does the clustering following the same steps as before but checking after every time the cluster grows whether adding those new addresses resulted in any contradictory votes being identified among the address cluster’s tickets. It was when I saw this warning being triggered for basic steps in my clustering process that I realized …
Tickets held by the same voting address can vote in contradictory ways
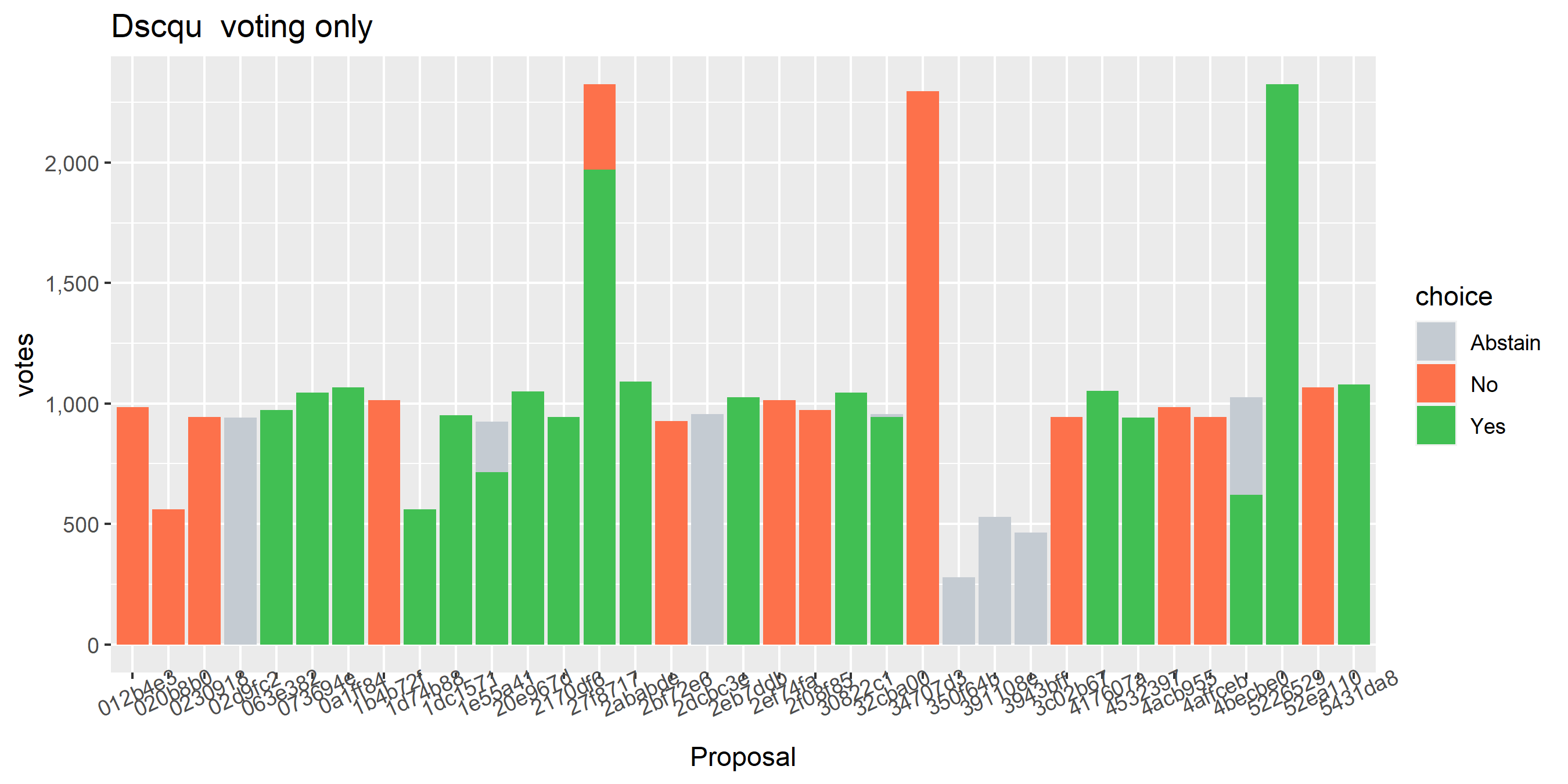
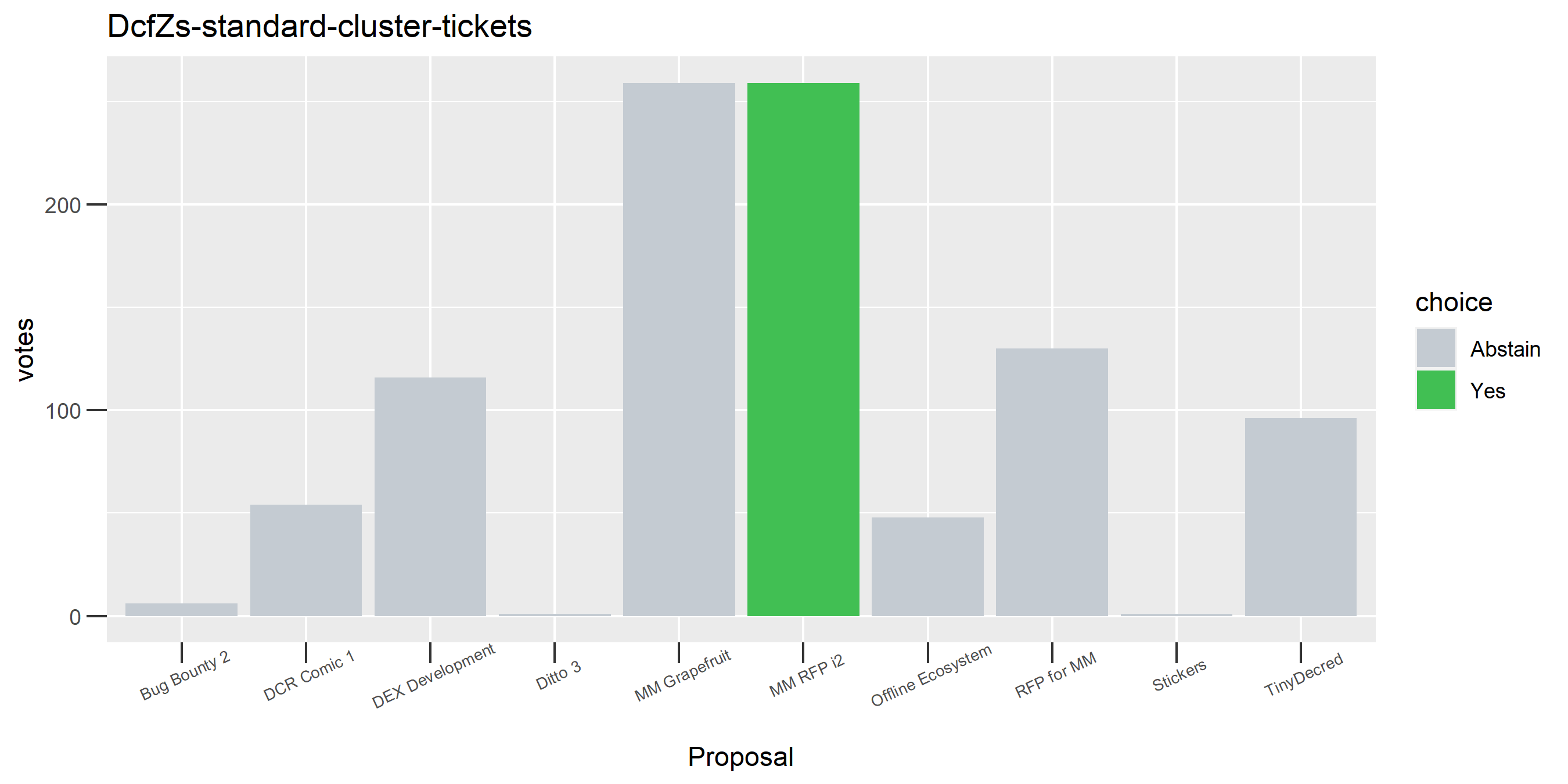
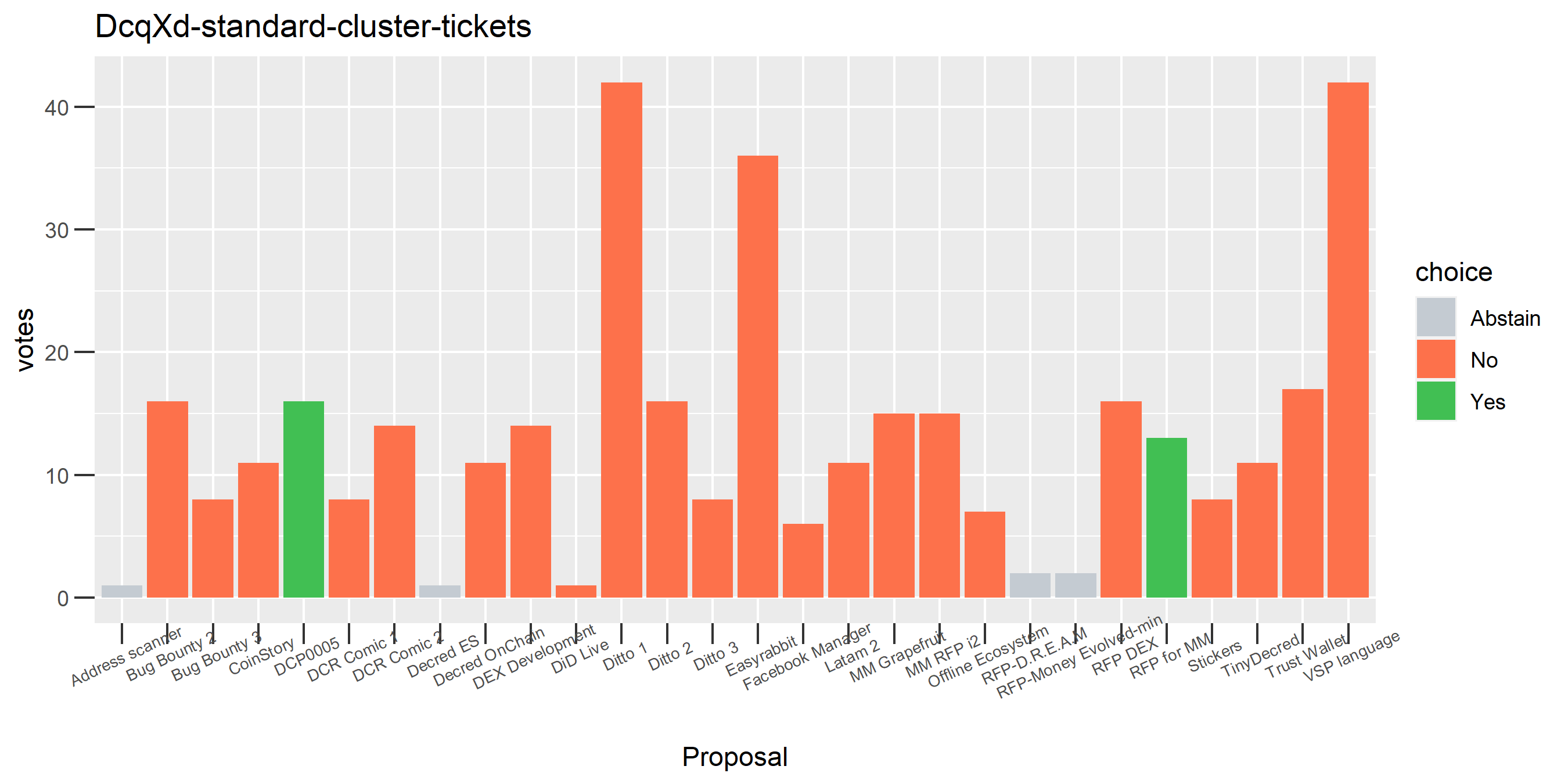
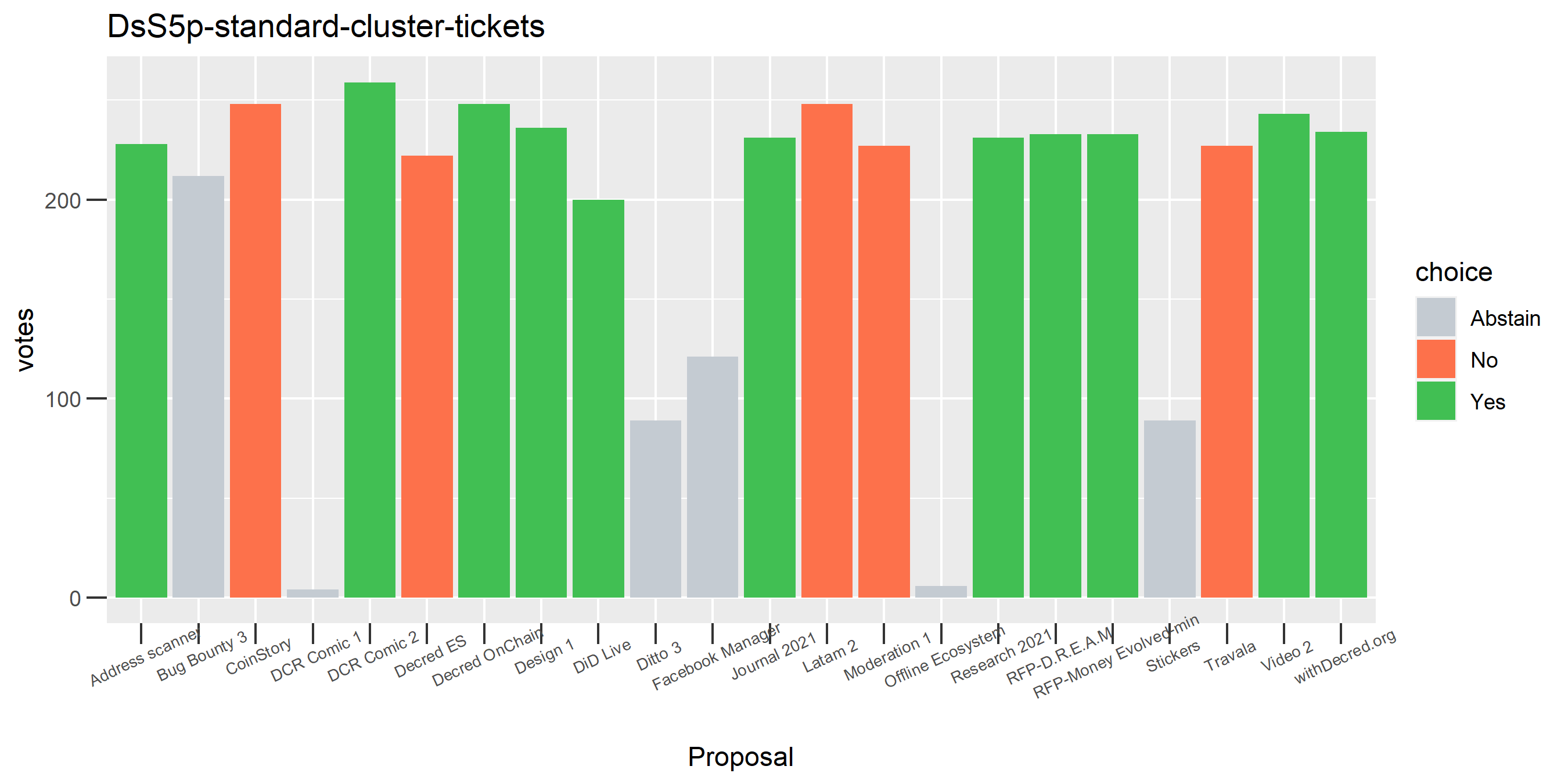
Above are the Politeia votes of the tickets associated with a specific voting address. In most cases the bar is solid green (voted yes), orange (voted no) or grey (didn’t vote eligible tickets). There are a few bars which have a grey section, indicating that the wallet had additional tickets at this address which could have voted but did not. There is also one bar with both green and orange sections, indicating that some of this stakeholder’s tickets voted No on the proposal (it’s the first Ditto PR proposal) while the majority of their tickets voted Yes. Decrediton votes all the wallet’s tickets at once, so I can only assume this is a CLI user who is trickling their votes with politeiavoter - sometimes their votes don’t all register before the close, and one time they changed their mind after they had already started voting.
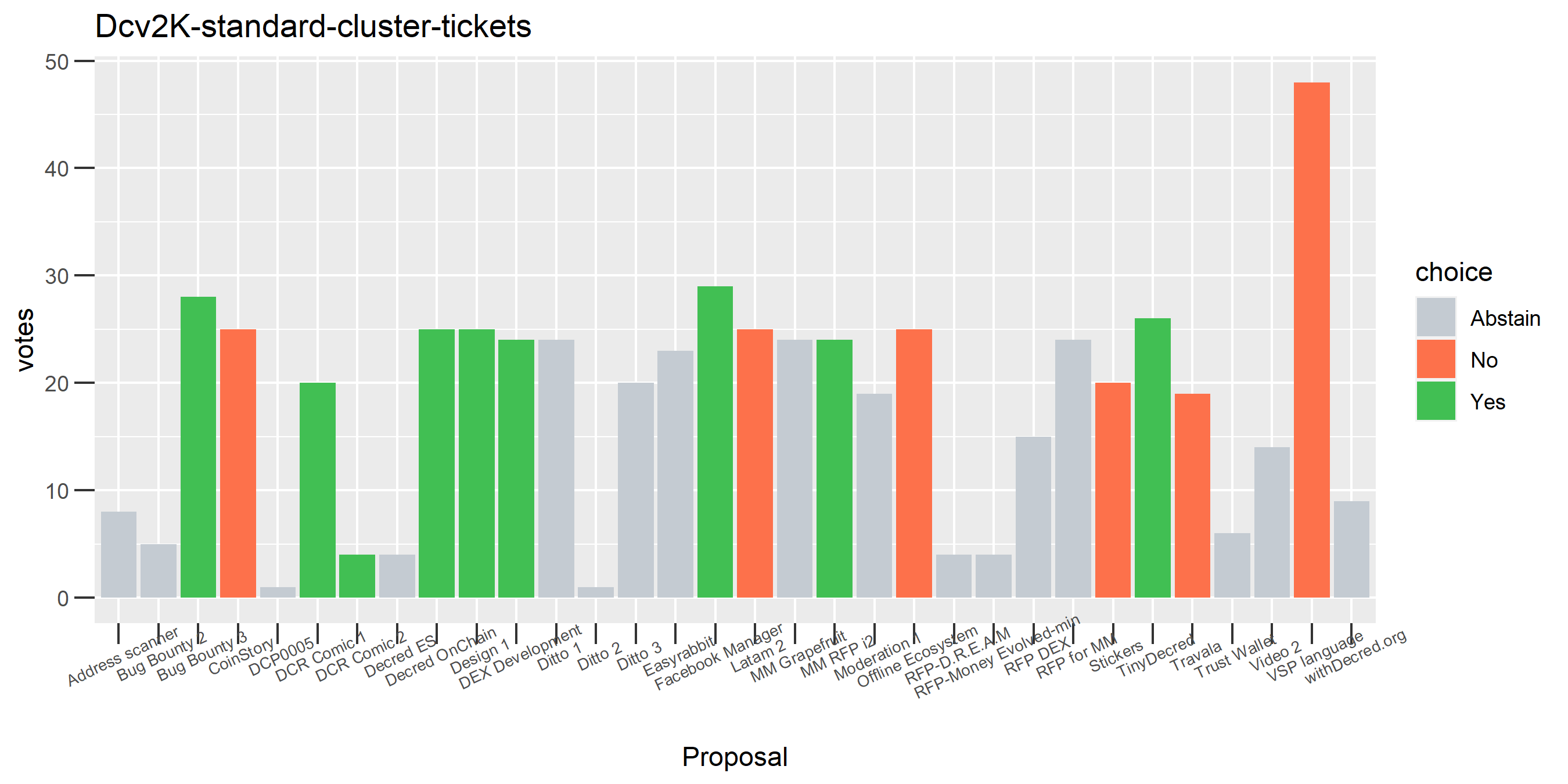
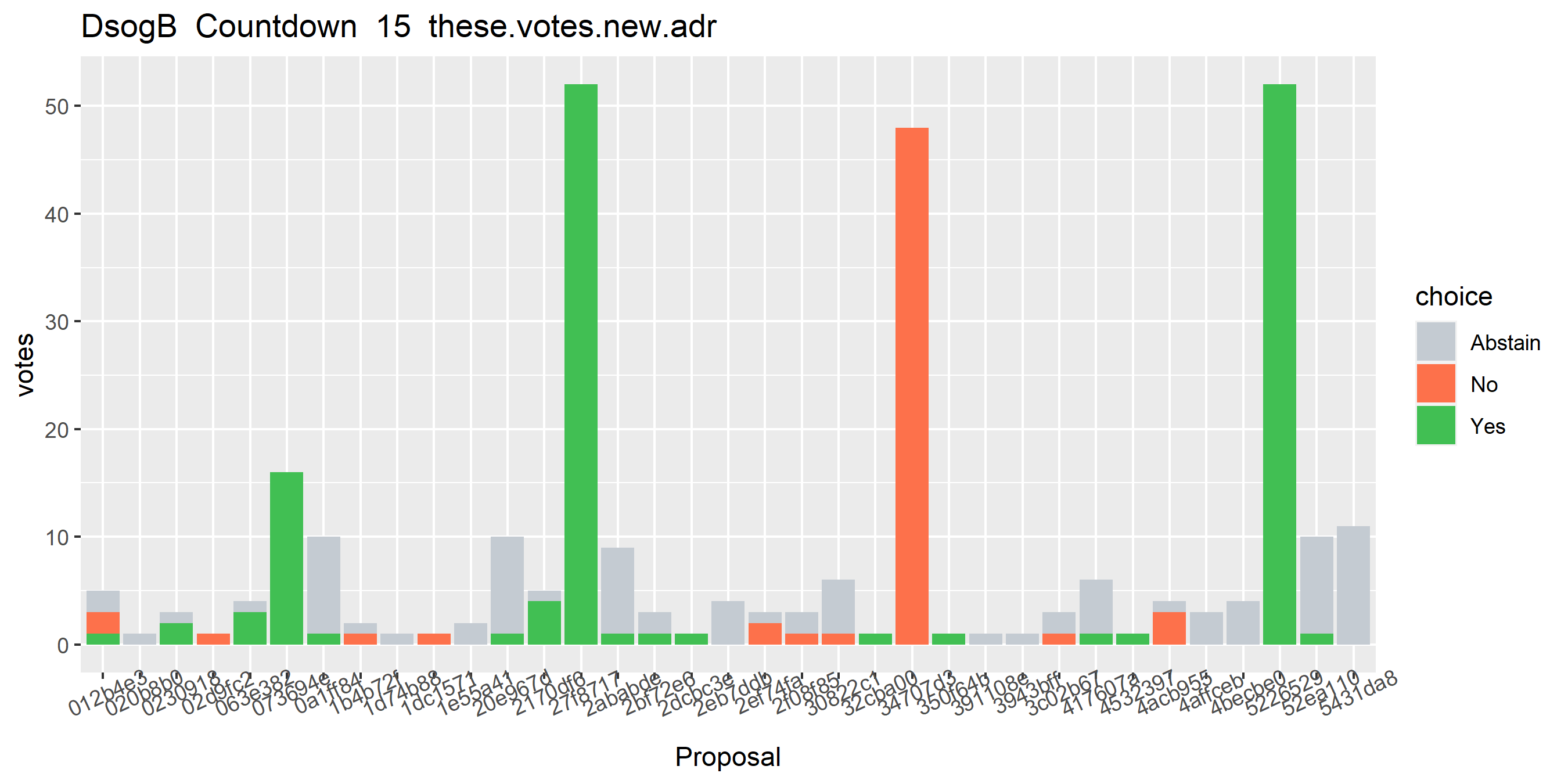
If I run my enhanced clustering on this voting address as a starting point, it turns into the graph above (Dsogb), which indicates to me that this cluster is being merged with several others due to some edge cases with the clustering heuristics.
To find out exactly where or how this is happening, I set up a script which would graph out the votes after every step of the clustering which added new ticket-holding addresses to the cluster. Running it on the Dsogb address, which featured in all the dodgy looking clusters, starting with the multiple input heuristic identified 1,101 addresses likely controlled by the same wallet as Dsogb. For these addresses 1,420 associated tickets were identified, but these tickets had no associated Politeia votes as they were all pre-Politeia (2016).
The next step of my clustering is to identify any tickets associated with the cluster’s addresses (the outputs from ticket-purchasing transactions which match known cluster addresses), and to identify the addresses from which the inputs to those transactions came. The ticket purchases are conducted in wallet by stakeholders and should only be drawing from funds the stakeholder controls. In this case, looking at the inputs to the ticket-purchasing transactions yielded 91 new addresses - it pushes the number of tickets up to 1,426 (+6) but these are still all old tickets.
The next step is to get all the outputs associated with these ticket input transactions - most of these outputs are the ticket-buying transactions we already discovered above, but at this point we add change addresses for those transactions, 27 in this case. Checking the tickets associated with the address set now shows 1,481 (+55), but these are all still old tickets with no politeia voting.
At this stage the clustering script moves to look at all the votes associated with the cluster’s addresses/tickets, and adds all of the output addresses for votes to the cluster - 39 new addresses here. With these new addresses the cluster now has 1,955 tickets (+474), and these include newer tickets which have Politeia votes associated with them.
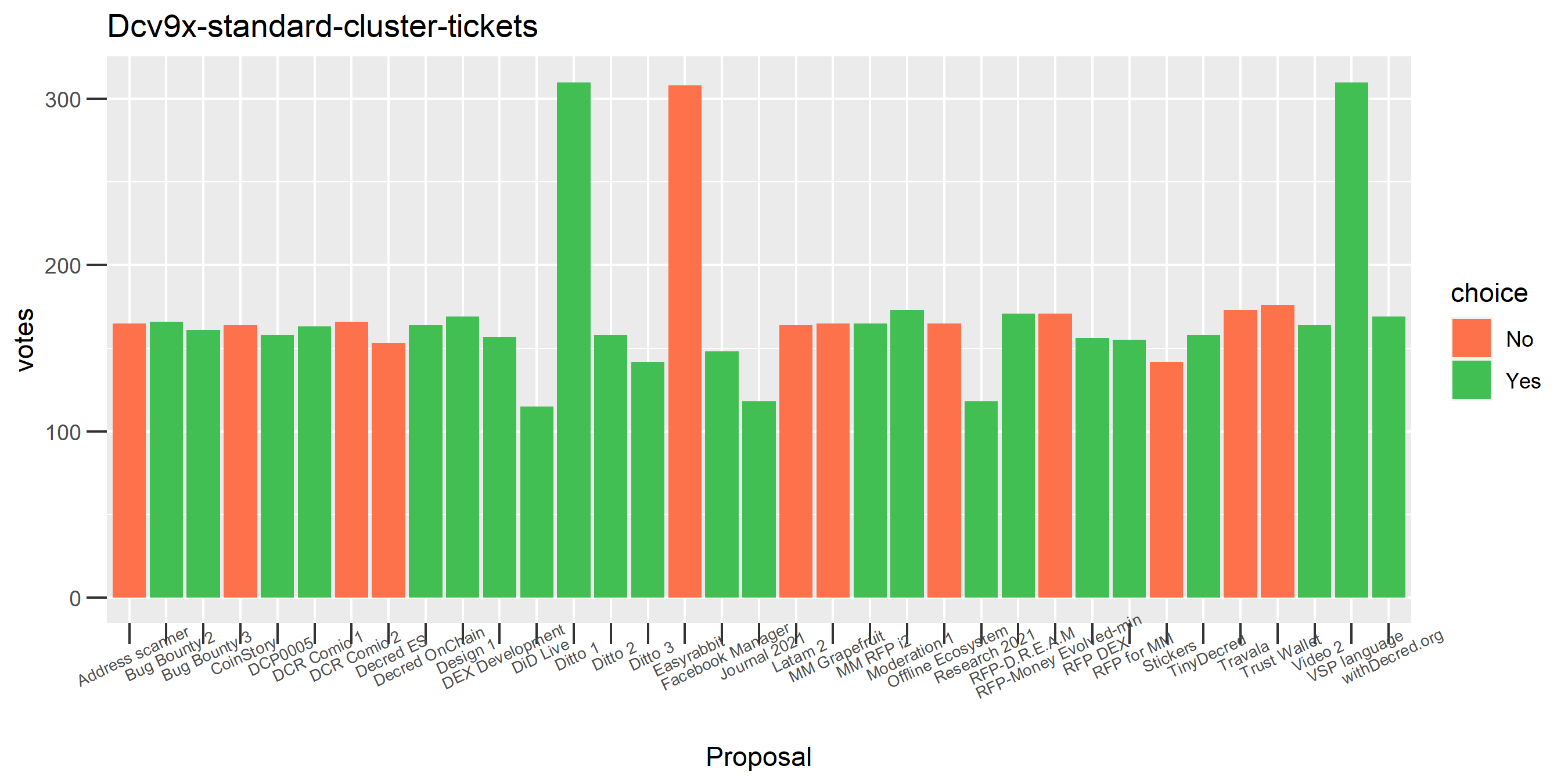
Looking at all the Politeia votes associated with this cluster, there are a number of proposals where not all eligible votes were used, but only one where the stakeholder voted for and against the same proposal. The next step in the enhanced clustering is to look at all the votes associated with these addresses and make sure the addresses associated with buying the tickets are in the cluster set. This step brought the number of tickets in the cluster up to 3,438, adding 27 new addresses - and it’s clear from the graph that this cluster is a mess.
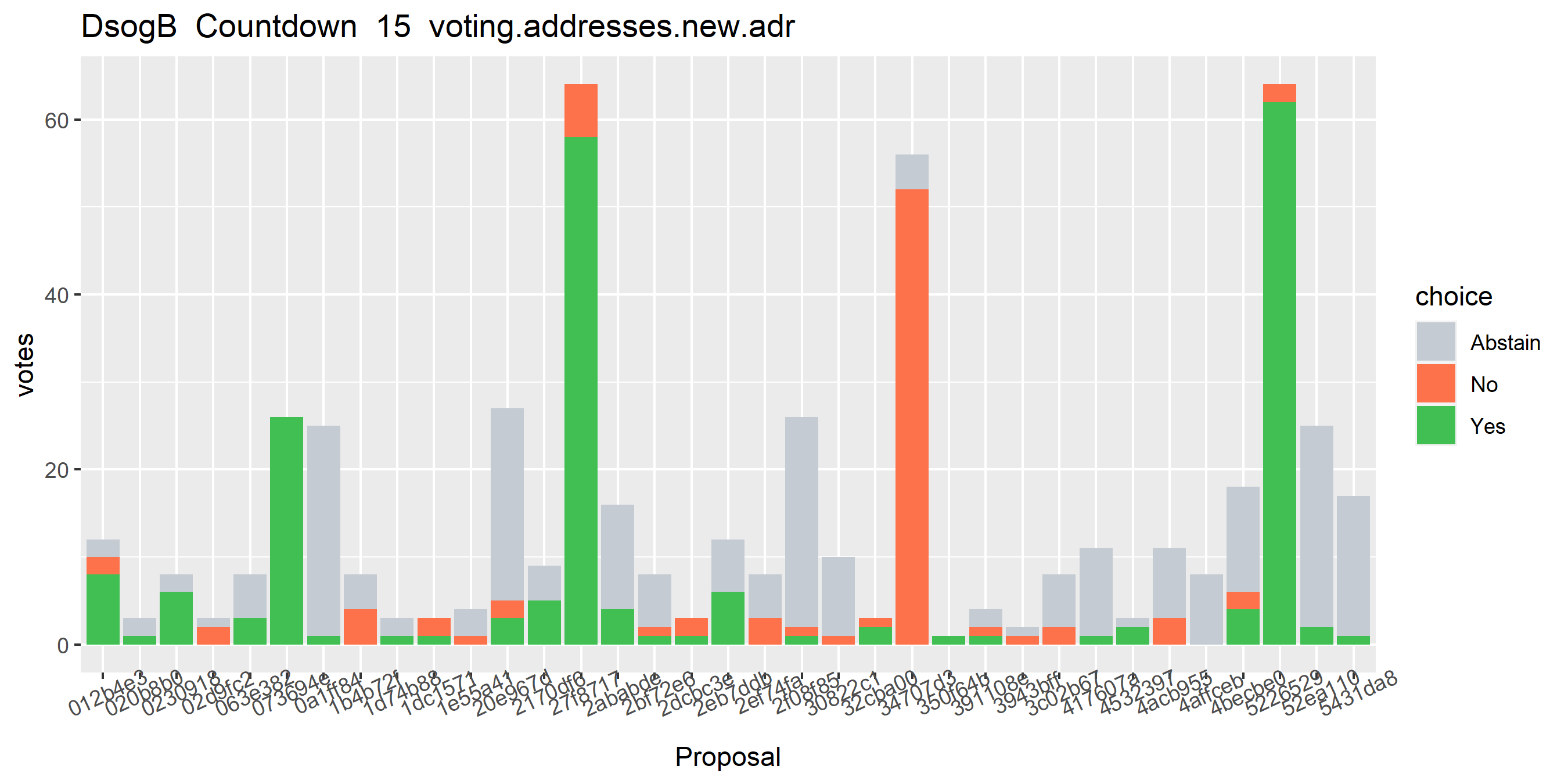
Initially, from looking at the graphs, it seemed like the problem was occurring, or most extreme, at this step of adding the addresses associated with inputs to voting transactions. However, while writing out this explanation, I realised that the prominence of older tickets associated with the seed address (“DsogB”), which did not have any Politeia votes, meant that the problem could have been occurring in previous steps but without any Politeia votes for the set there would be no indicator of this.
So, the best place to test the enhanced clustering is with seed addresses that became active after Politeia launched. Using this testing set, the clusters should have Politeia voting records from the first steps that involve ticket-holding addresses. This marked a second phase of searching for problem cases, restarted with an initial filter for any old pre-Politeia addresses. This didn’t work so well however as starting with “Pi era” tickets often led directly back to “pre Pi” tickets, and those older transactions seem to result in most of the dodgy clusters.
Testing the enhanced clustering - searching for Dsog cluster’s origins
At this point it really looks like something in the pre-Pi era is confusing my scripts and leading a lot of clustering runs to end up back at the same place - this large cluster of addresses which includes Dsog. So I started running some of the addresses which end up in this big cluster manually, inspecting the new addresses being added at every step and looking for evidence of when and why things went wrong.
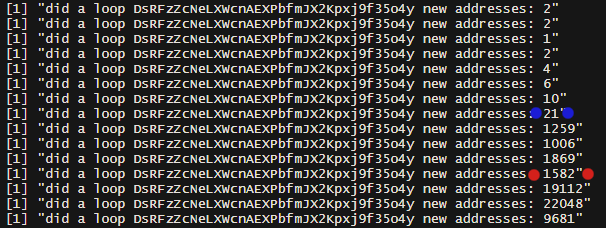
When this script is running it prints status updates to the terminal after each iteration. After 8 iterations of picking up one associated ticket going forward and backward from the starting point, the script suddenly adds 1,259 new addresses. This is a few iterations before the first politeia votes are detected (iteration 11, red dots).
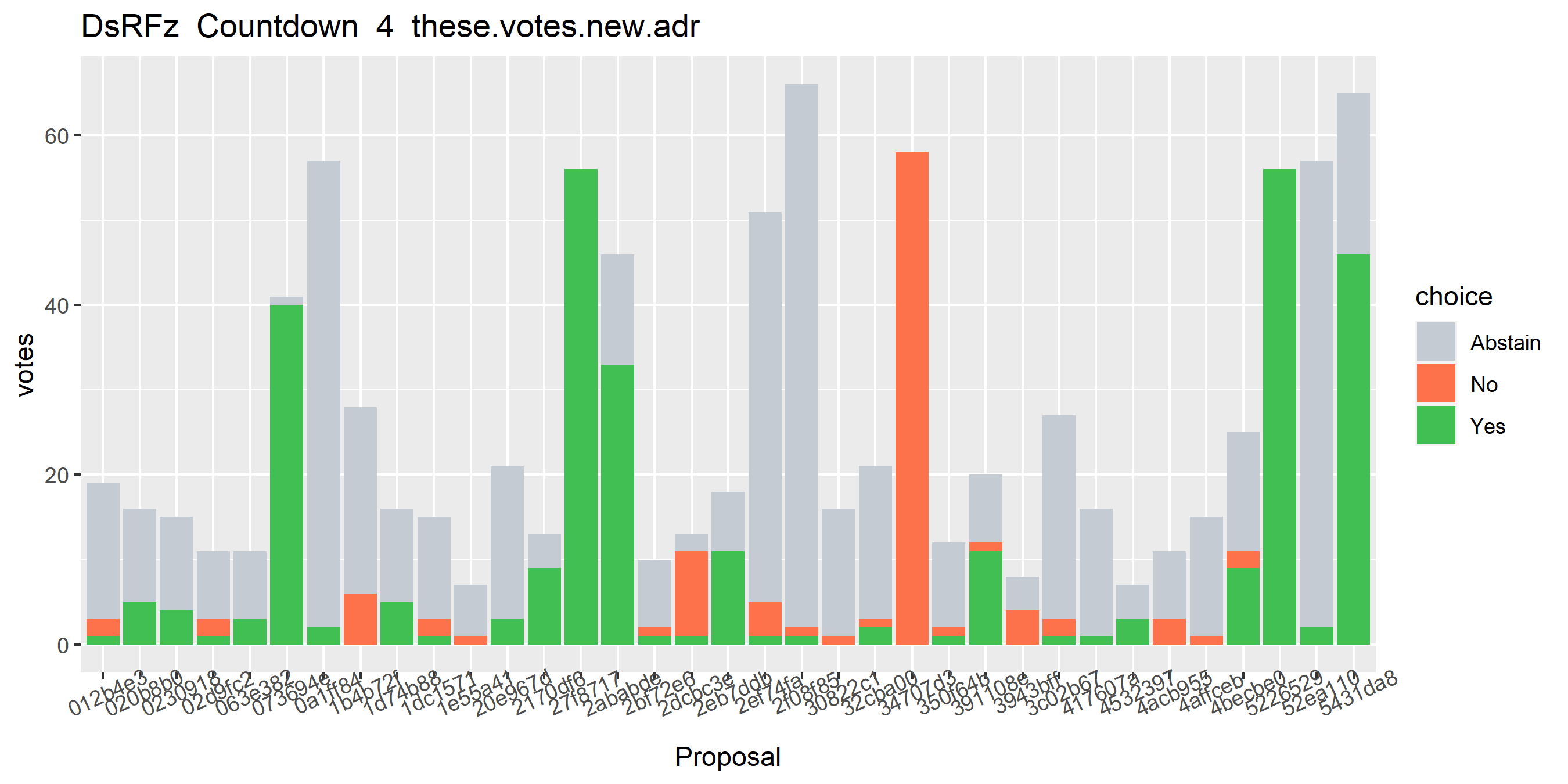
The Countdown variable starts at 15, so Countdown 4 means it’s already done 11 iterations of the clustering (check each heuristic, add any new addresses to the list, fetch all associated transactions and start again checking each heuristic). At the first point where this cluster has Politeia votes it has a bunch of conflicting votes on yes/no proposals, so something is already broken.
I worked through each of the iterations manually, checking the transactions associated with new addresses that were being added to the cluster, to see if I could spot the point where the dodgy addresses were being added to the list. This appears to have happened at iteration 8 where the big jump in addresses happened, unsurprisingly.
I started calling up transactions on dcrdata’s explorer to see what was going on, and it seemed to be related to change from ticket transactions. After looking again at the code, it turns out that a function I have been using for a long time to filter out VSP fee payments was missing some edge cases from early in Decred’s history. This meant that addresses of users of a certain VSP at a certain point in time have been mixed with the VSP operator’s addresses, bundling all of these people into a single cluster.
This makes a lot of sense and it was my suspicion that VSPs had something to do with these issues. The reason it was hard to detect is that the mingling of addresses happens only with 2016-2017 transactions, and then the reveal of this error only becomes obvious when you see how tickets associated with this cluster are voting on Politeia proposals years later.
I went through a few iterations of tightening up the checks on new addresses associated with tickets, but in the end I had to cut the step that added new addresses associated with the outputs of tickets entirely because these dodgy looking clusters would eventually creep in no matter what checks I put in place.
In practice I could see from the checking that cutting out this step was not a huge loss, it’s not like some of the other steps where the clusters would be dramatically smaller without the new addresses being added in this way. So, I cut my losses and dropped that step entirely, and started to run all the clusters and checks again.
The final (?) problem was when going from a VSP cluster’s addresses, such as the wallet’s own voting address, the multi input heuristic was picking up VSP fee payments and tracking back from these to include the tickets which belong to a VSP user in the VSP’s set. This one goes back to a quick hack I took a long time ago which got buried in my code - differentiating between ticket outputs which are returning the stake and voting reward and the VSP fee payments by using the value. Initially I set a rule that all outputs worth less than 1 DCR should be considered VSP fees, but then the voting reward decreased below this level after a series of monthly one percent diminishing supply events. At some point I dropped the level down to 0.75 DCR, and at this level there are (more?) errors creeping in from Decred’s early history. These errors don’t appear unless one looks up addresses associated with very old tickets, and those very old tickets have no pi votes, so it was difficult to determine that this is where the error crept in.
For now the best solution I have found does this filtering in two epochs, before (all outputs <1 DCR considered VSP fees) and after (all outputs <0.5 DCR considered fee payments) Jan 1 2018. This is still a rough heuristic because I couldn’t find anything more reliable, it seems to always be true and in the post-2018 era VSP fee payments are much much lower.
Stakeholder voting records
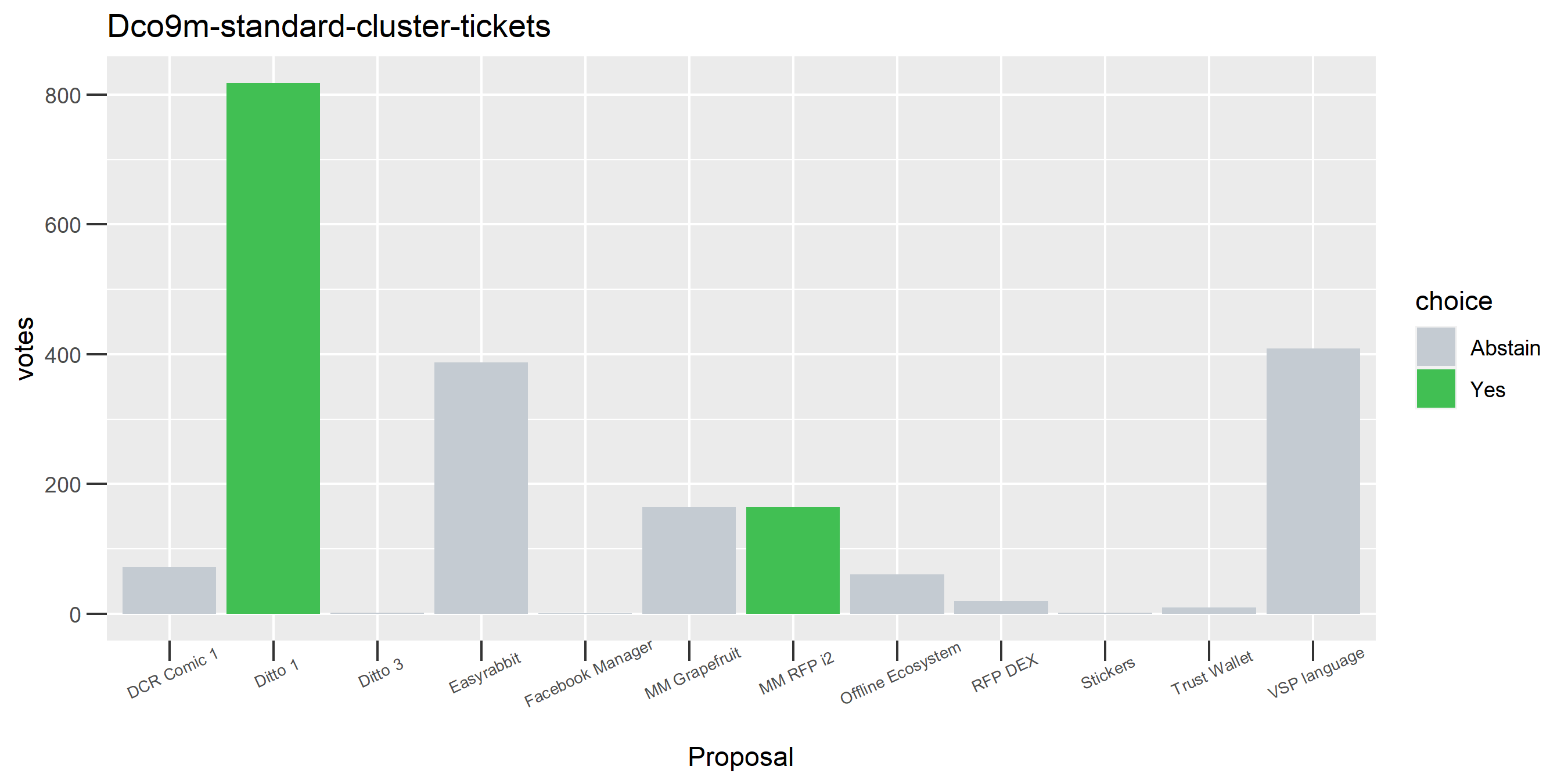
One of the uses for this data is to better understand stakeholders’ voting behavior by looking at patterns of support and opposition between proposals - maybe there are distinct constituencies of voter who always tend to vote, for example, against marketing proposals. Each voting record also tells a story, like where a stakeholder has voted Yes on Ditto 1 and 2 but no on the 3rd proposal.
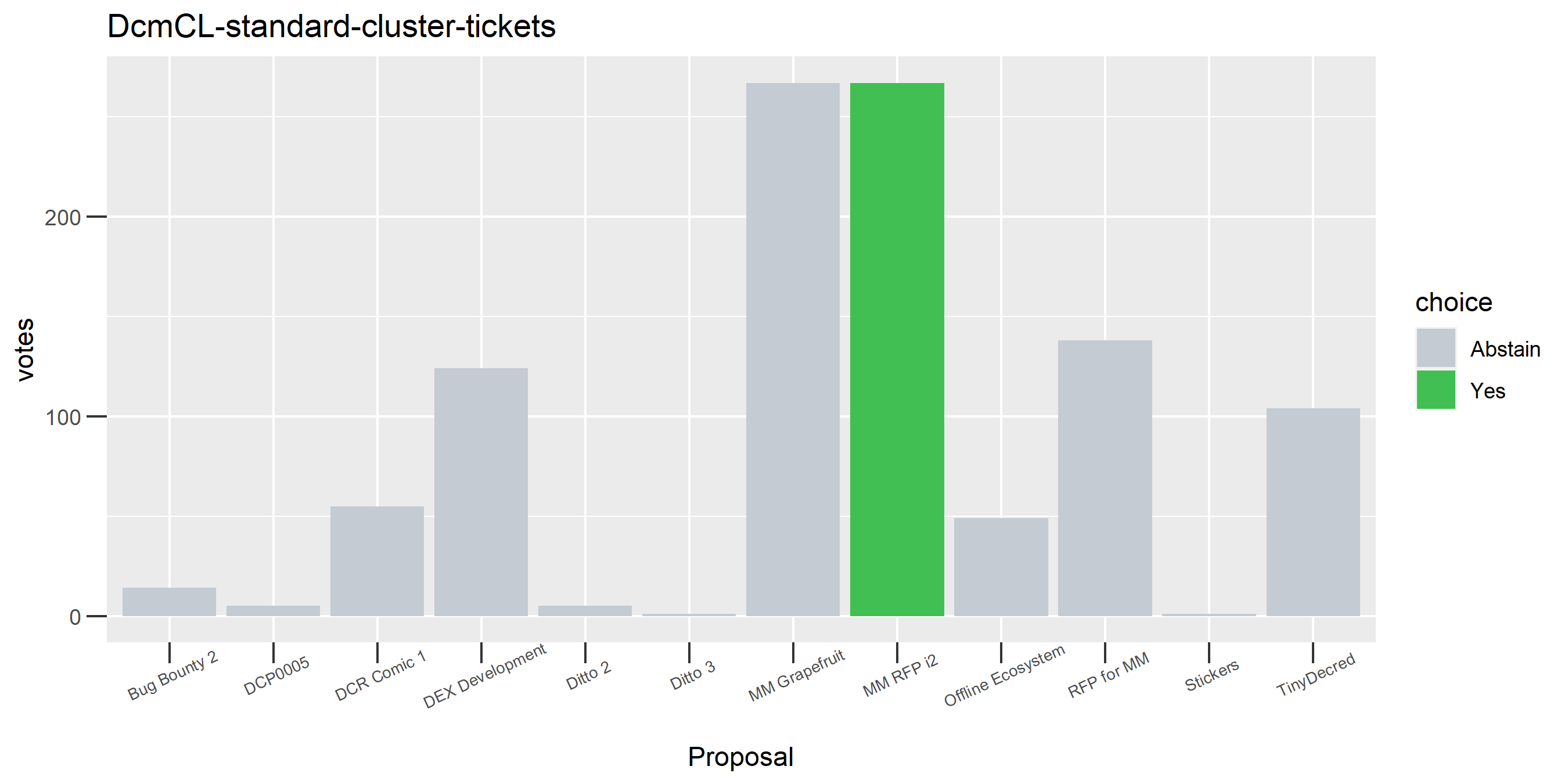
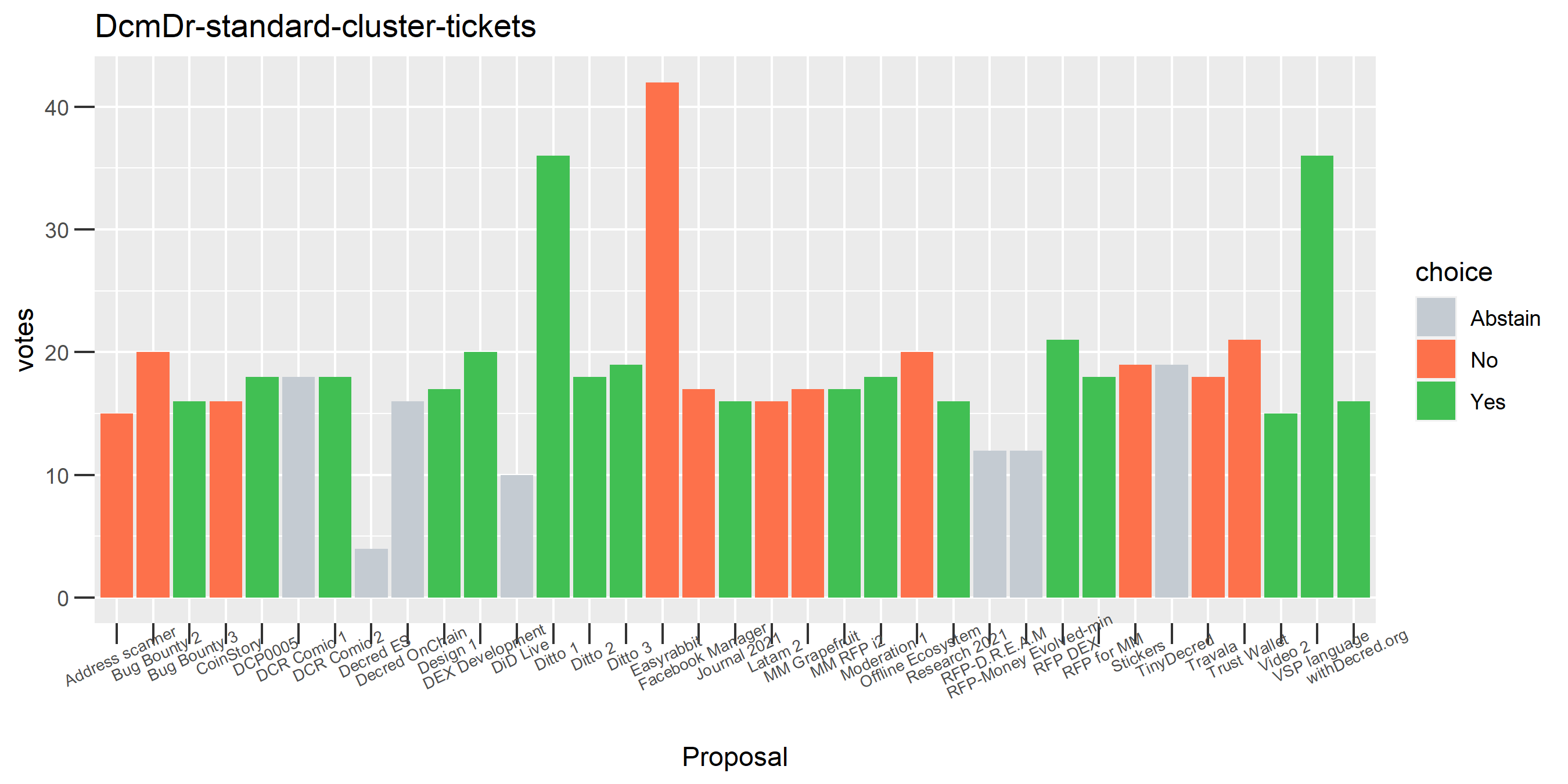
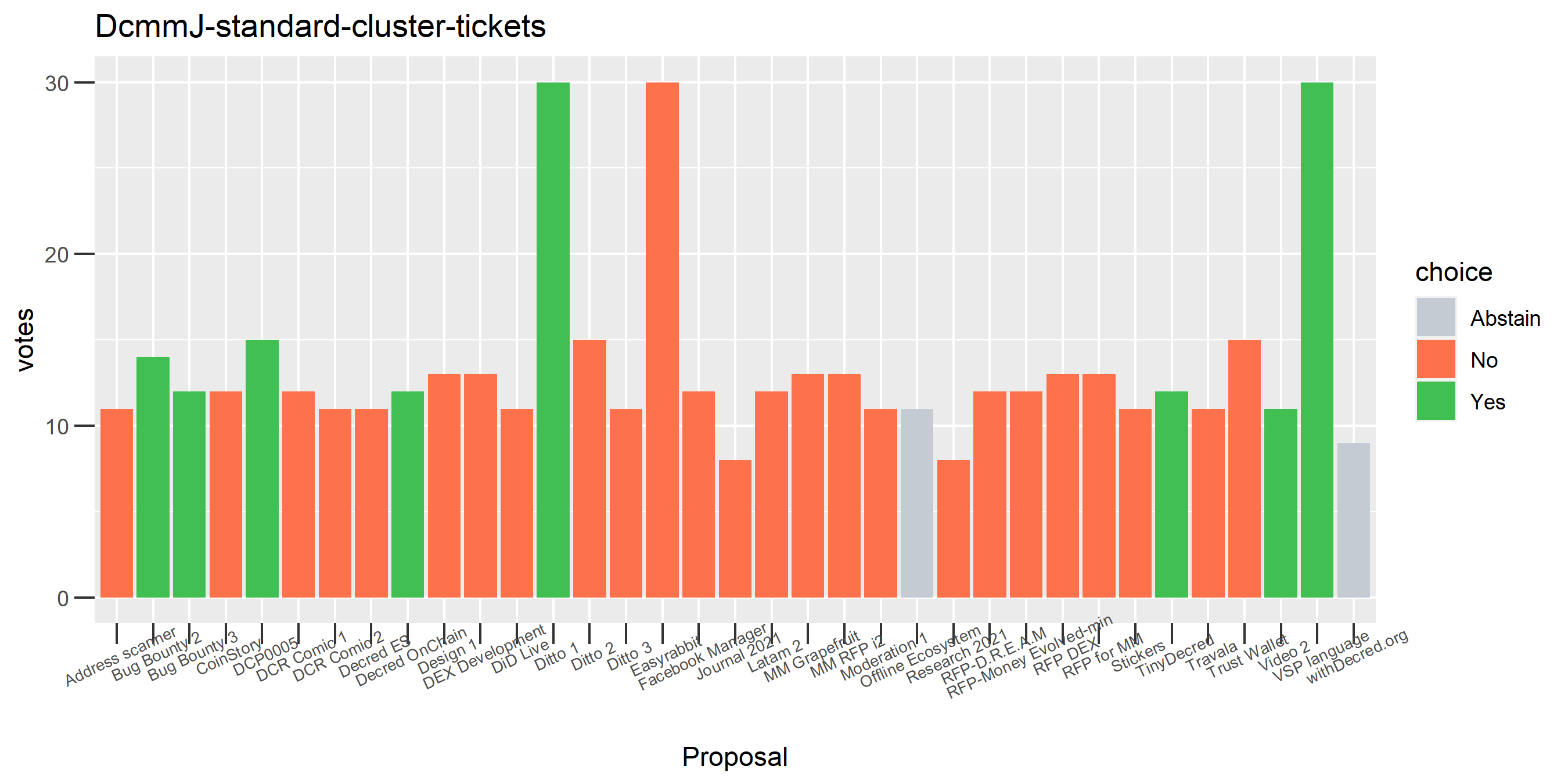
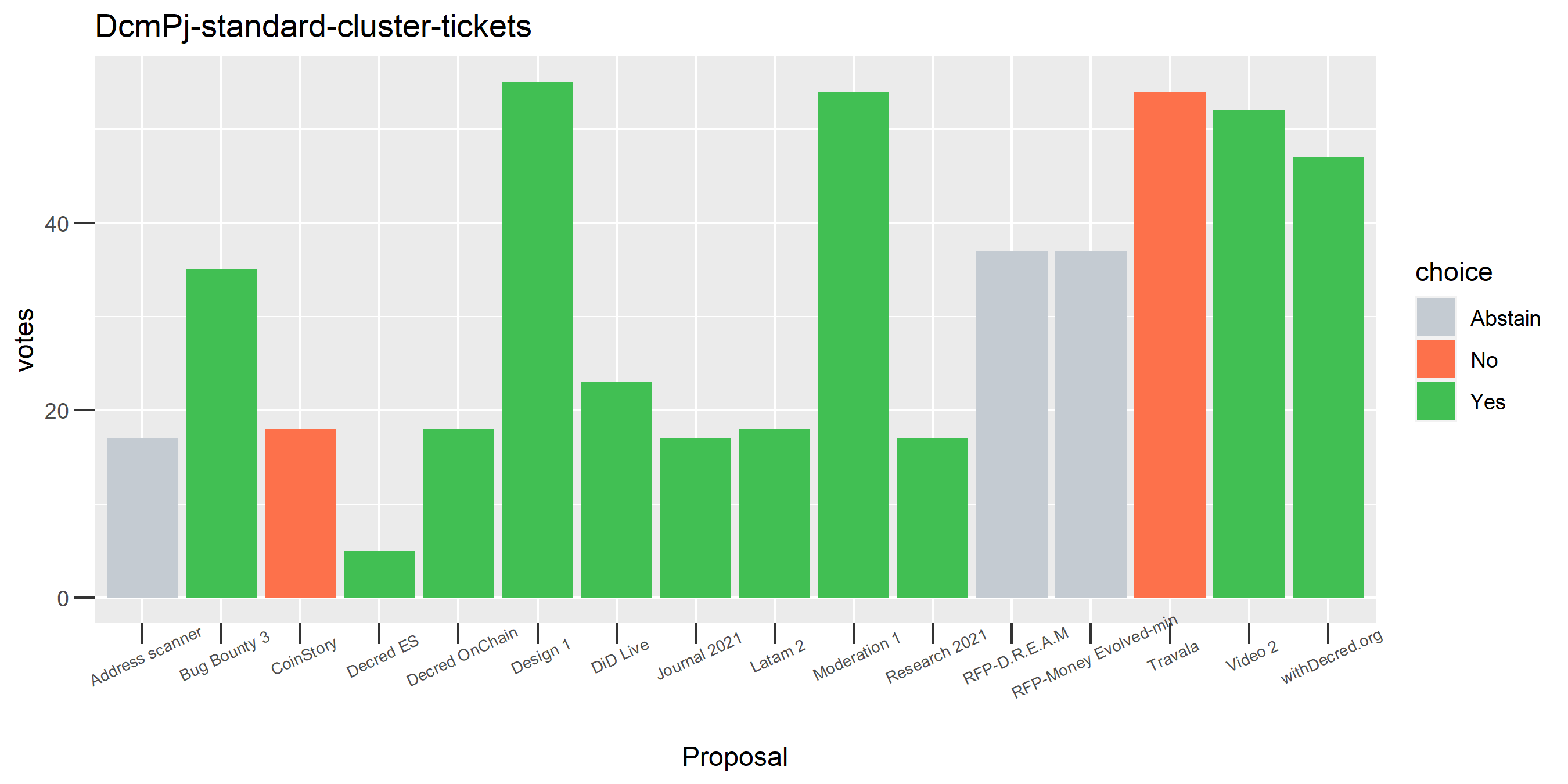
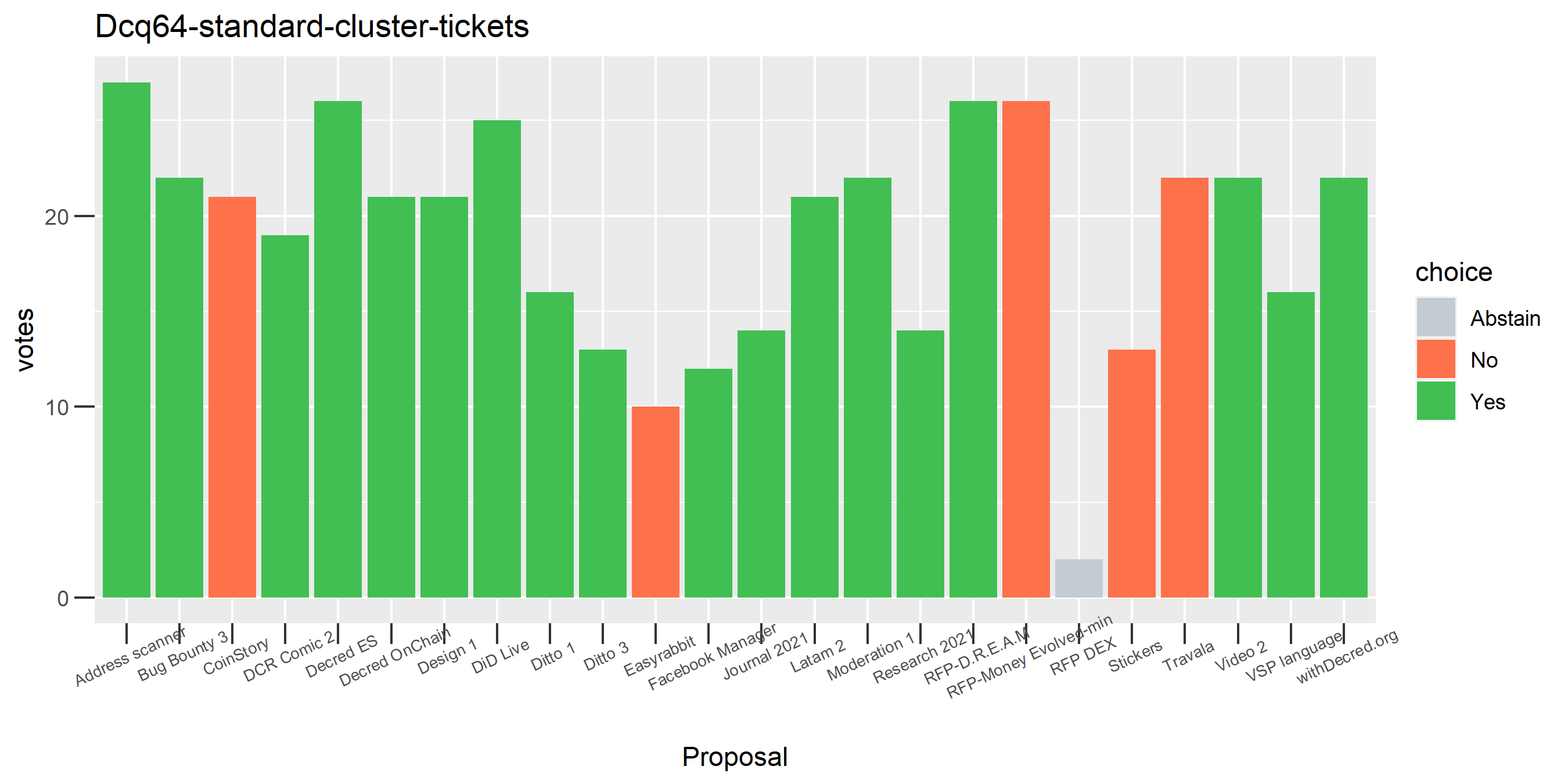
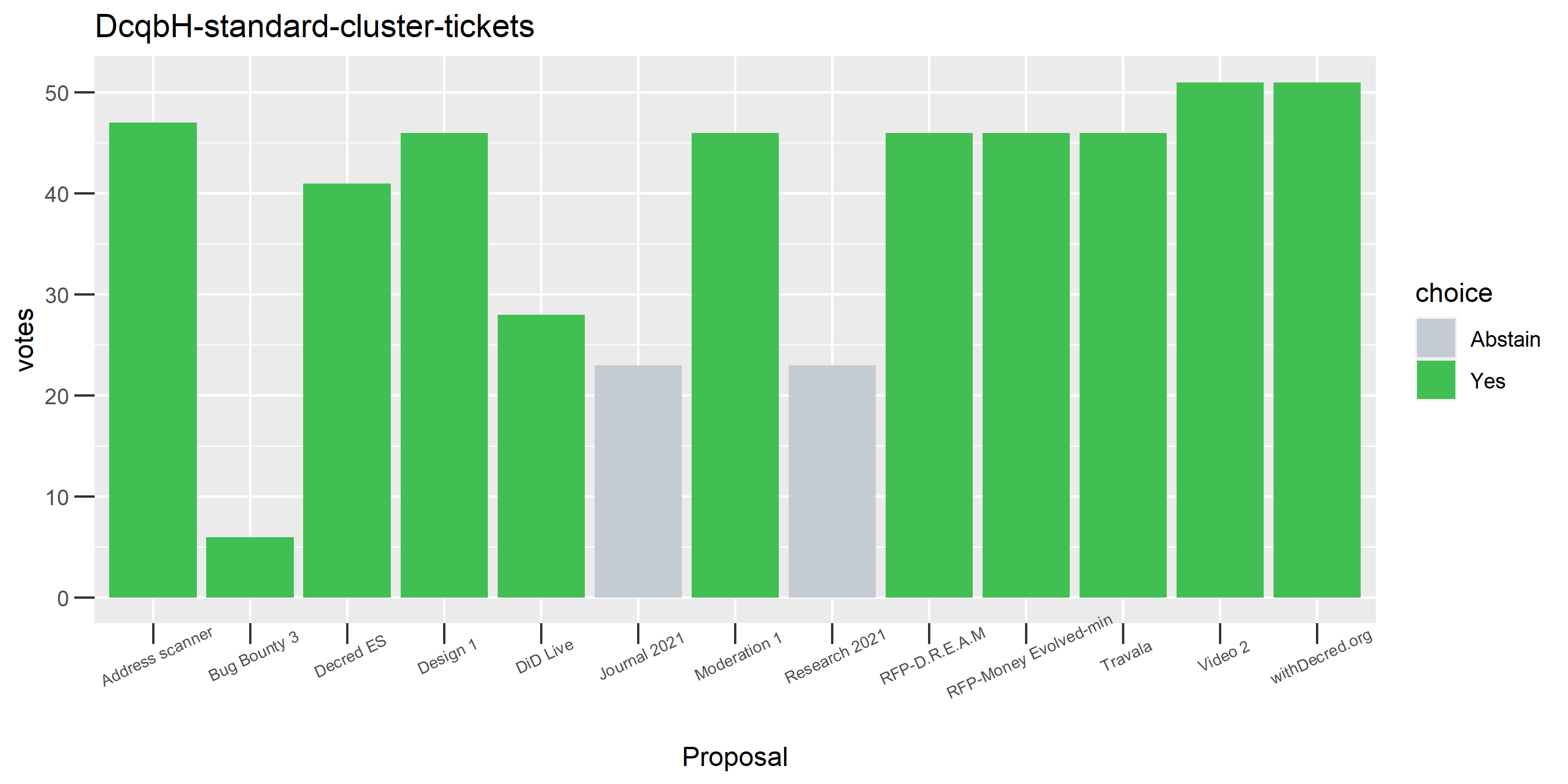
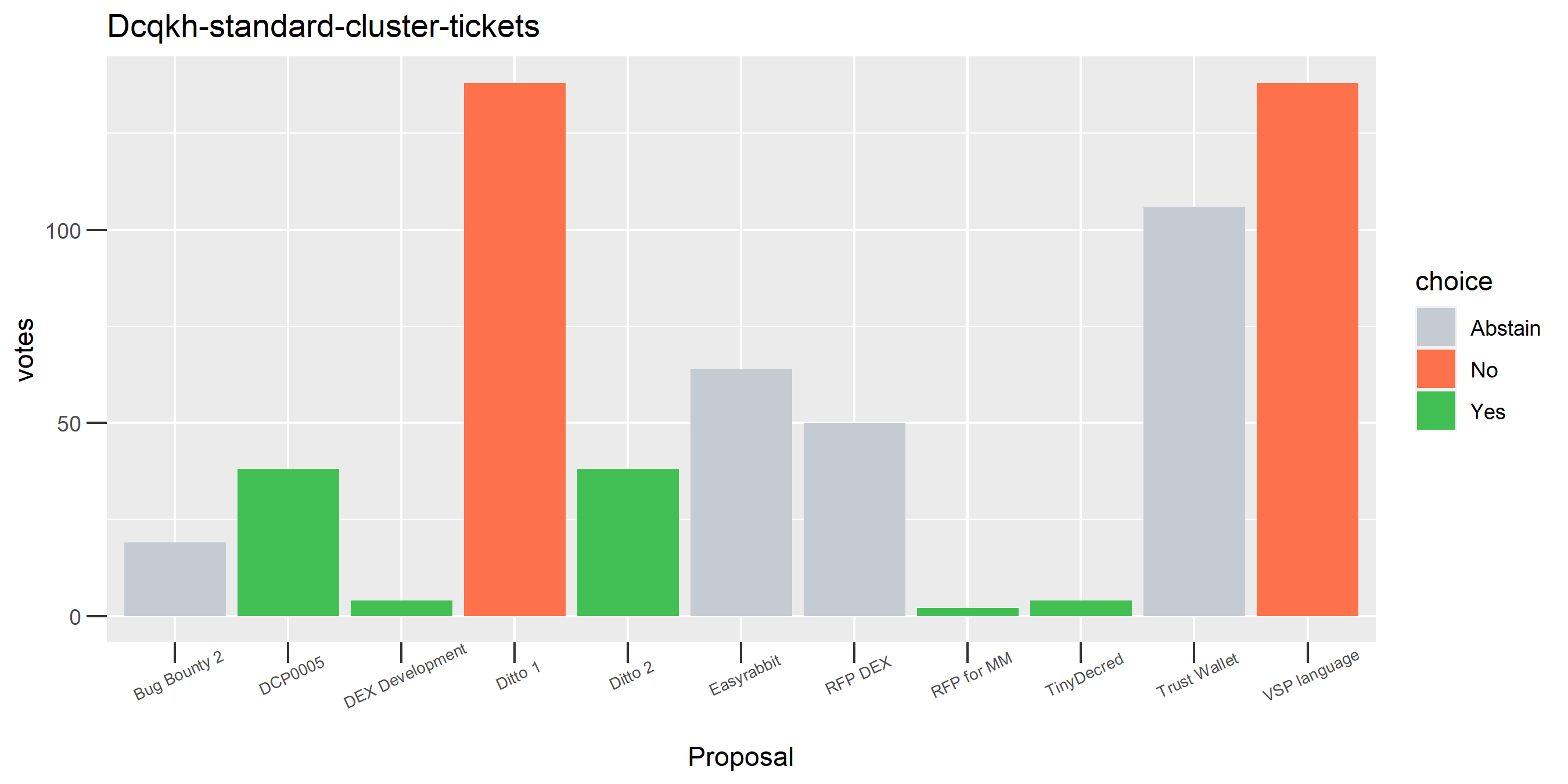
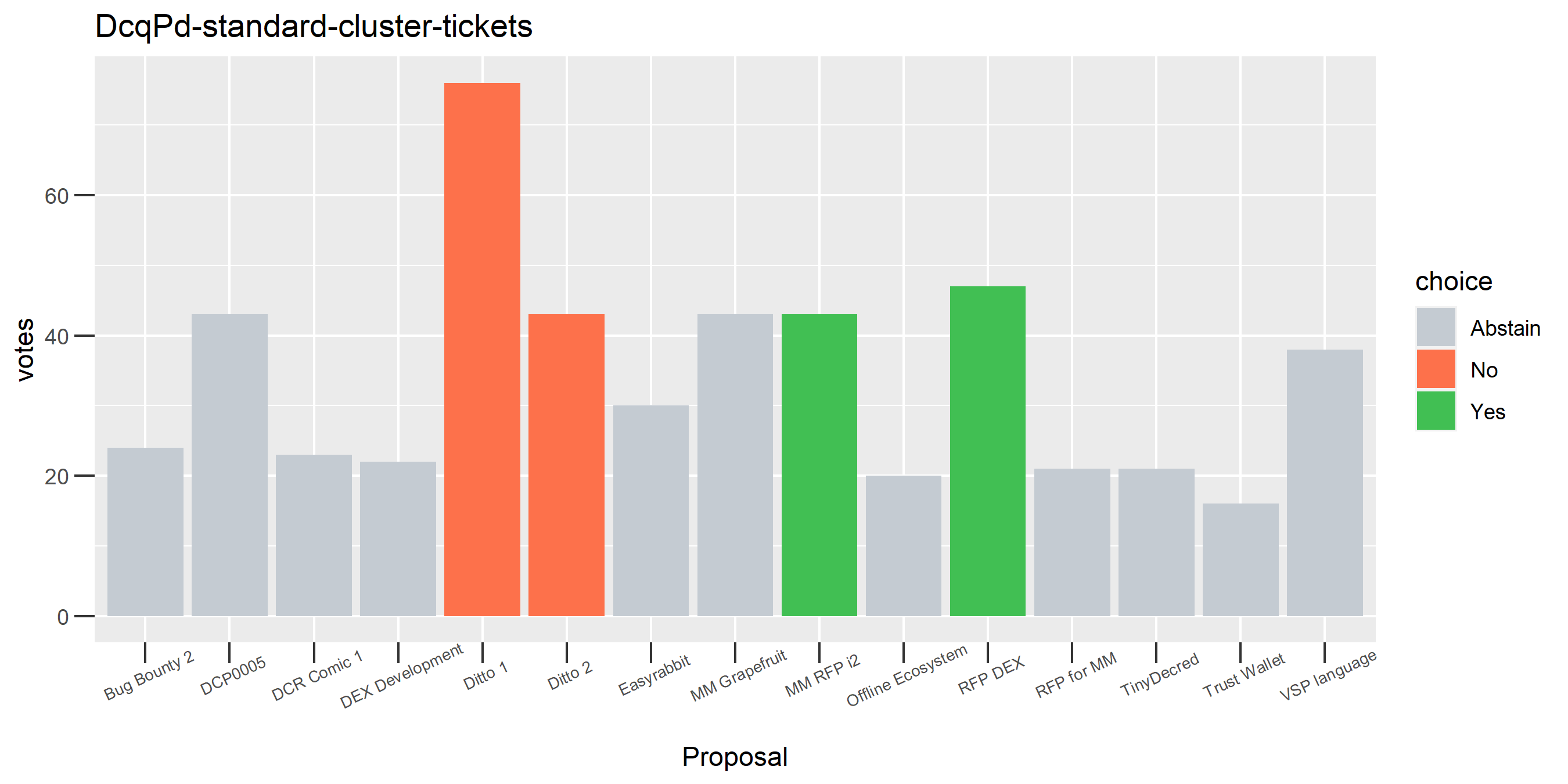
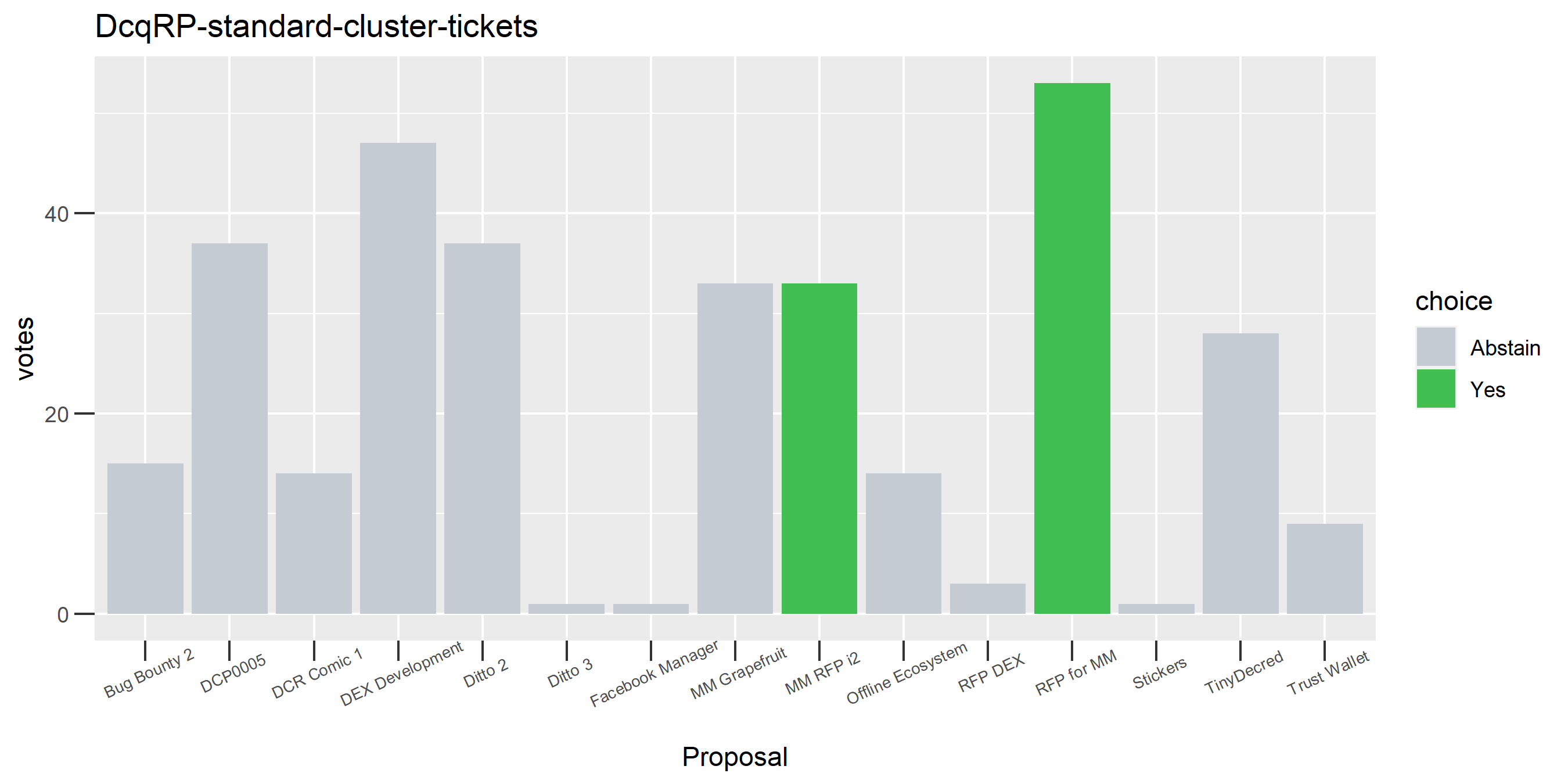
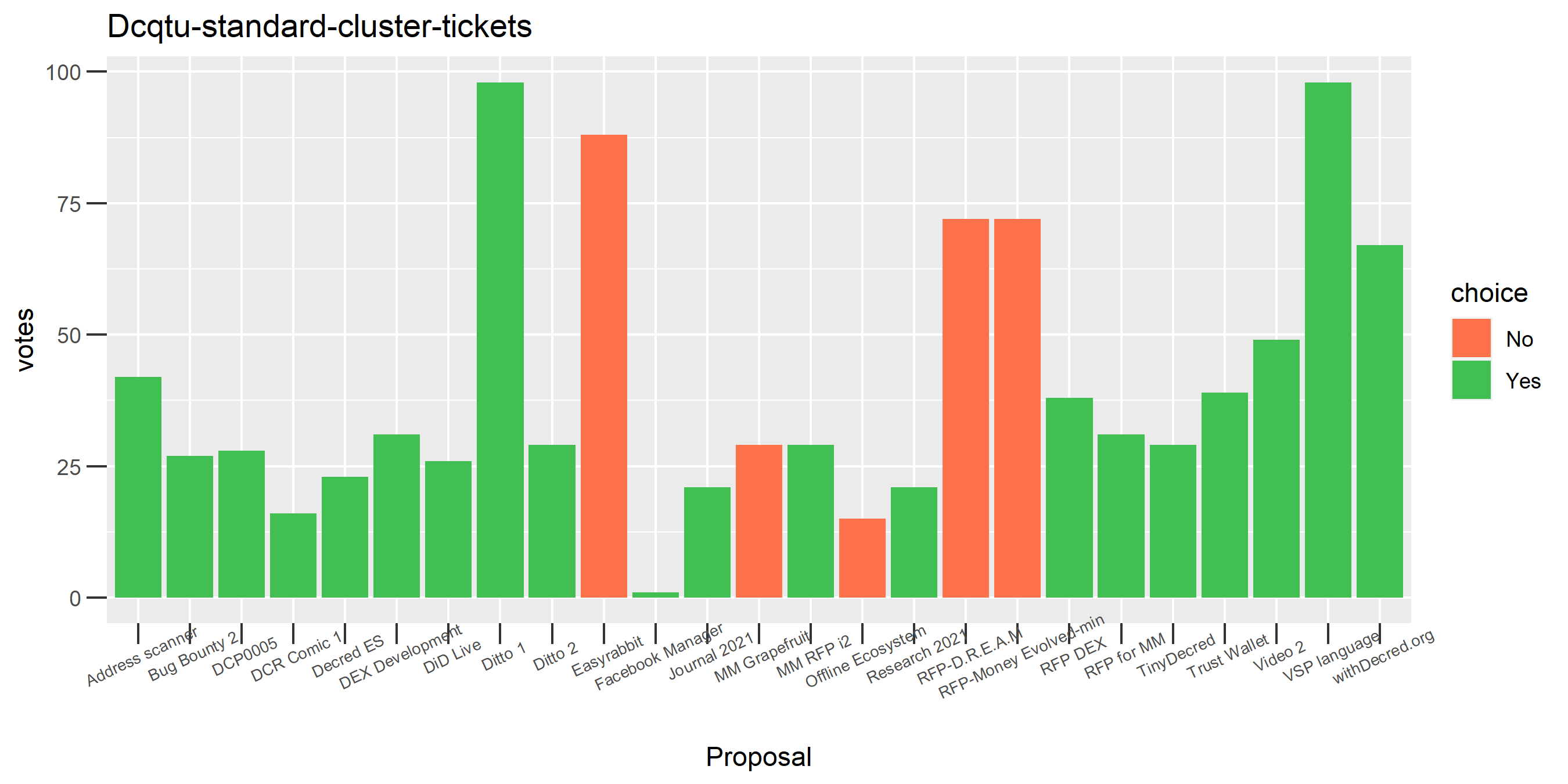
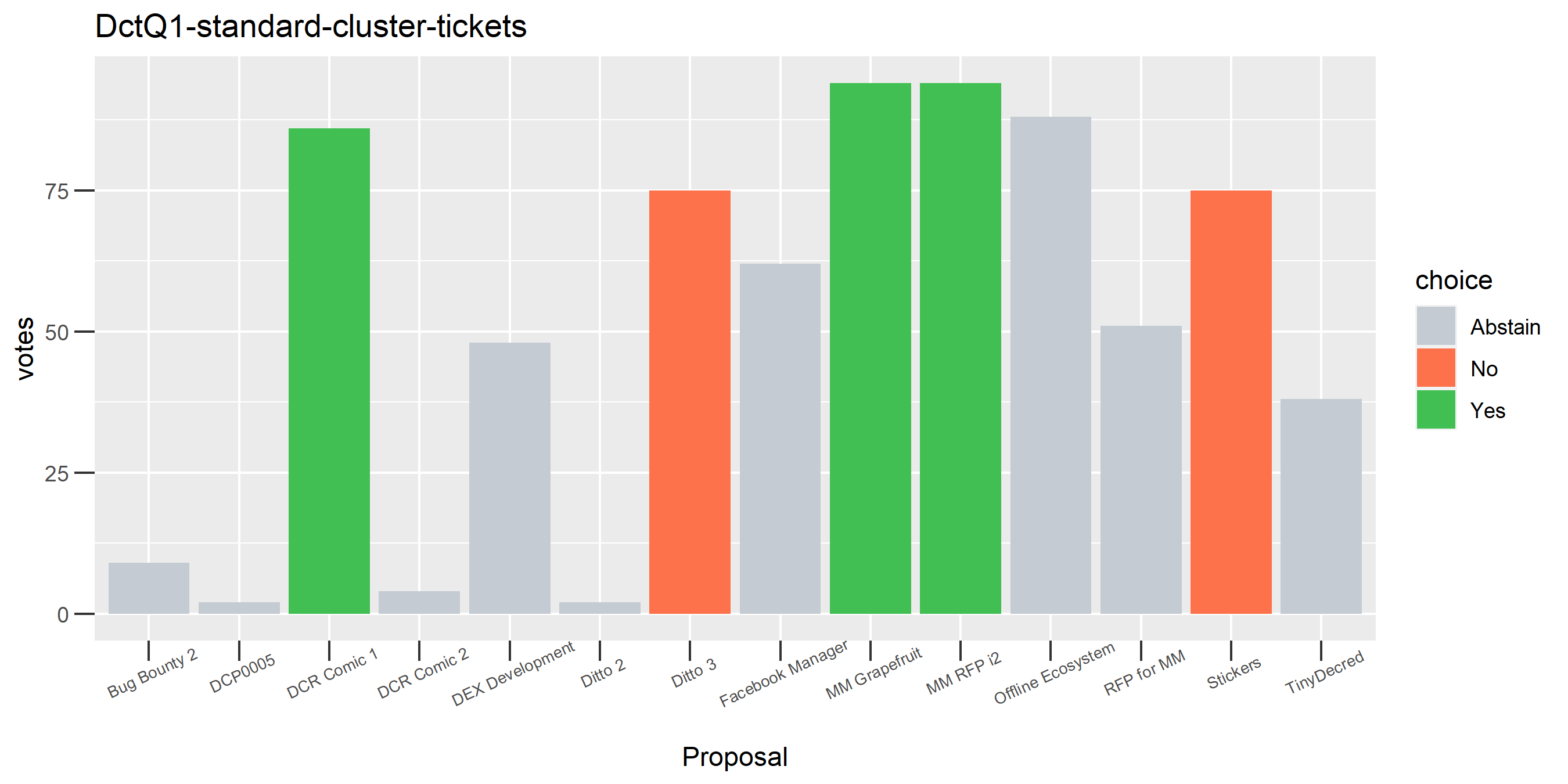
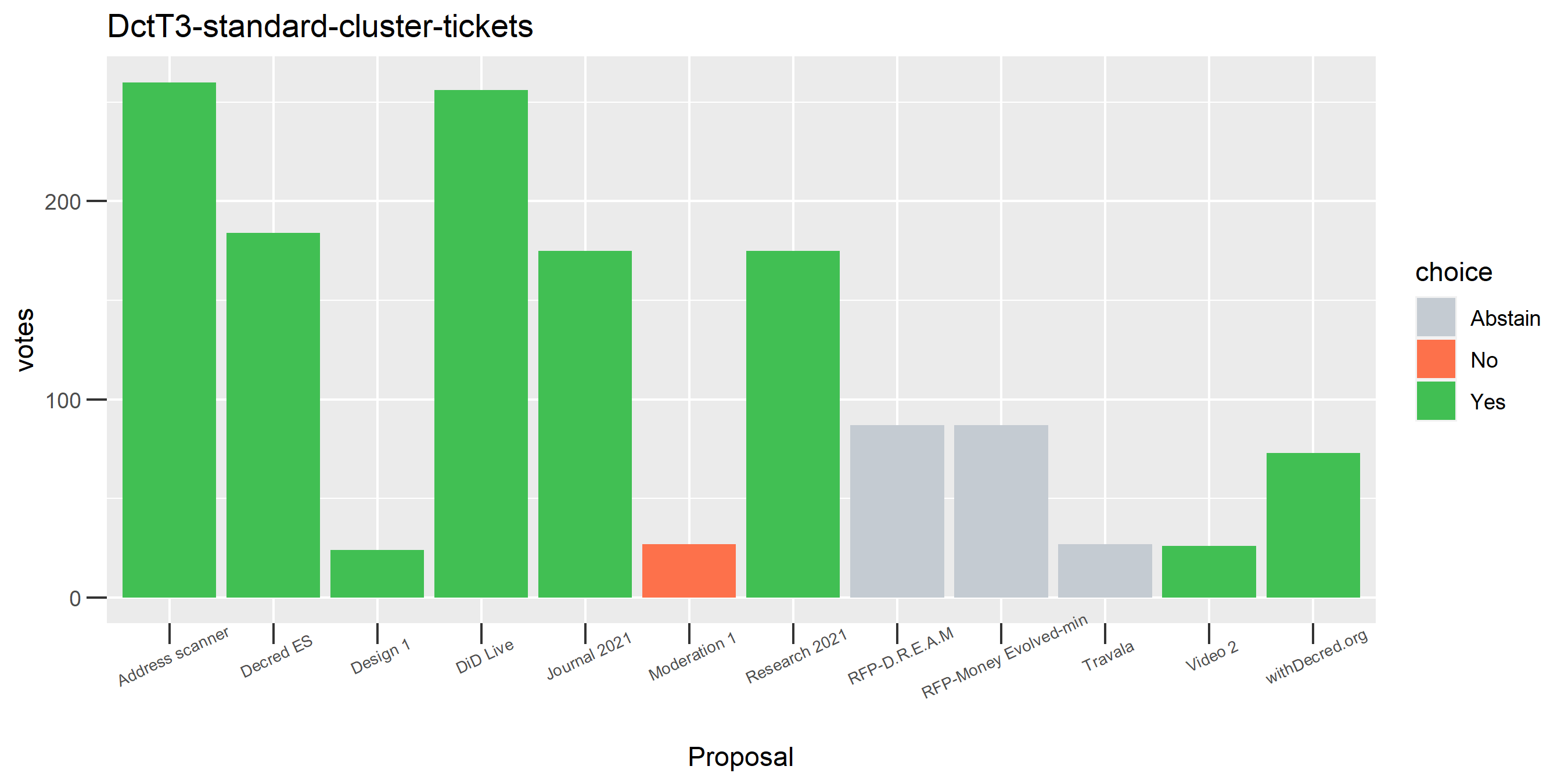
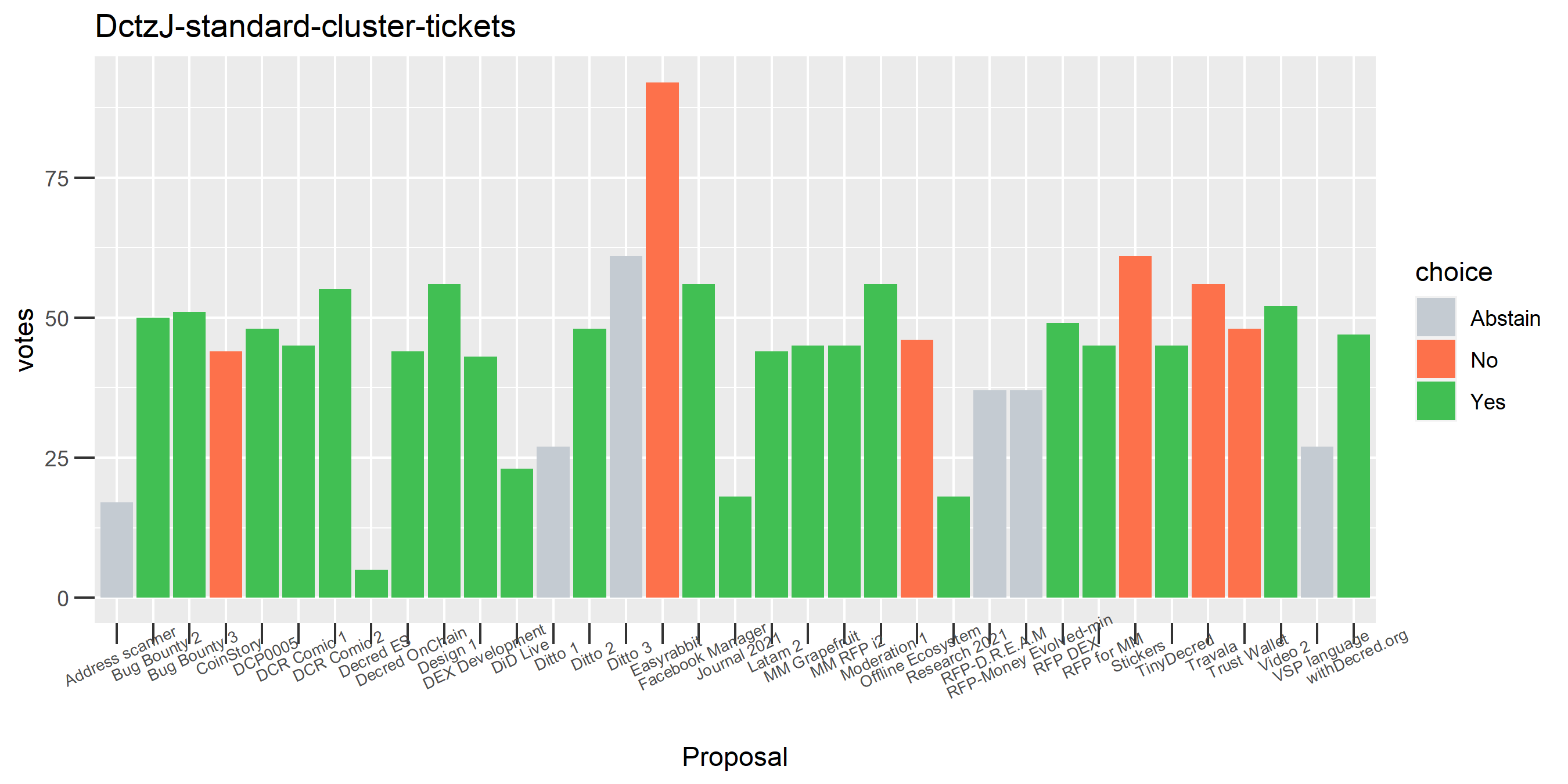
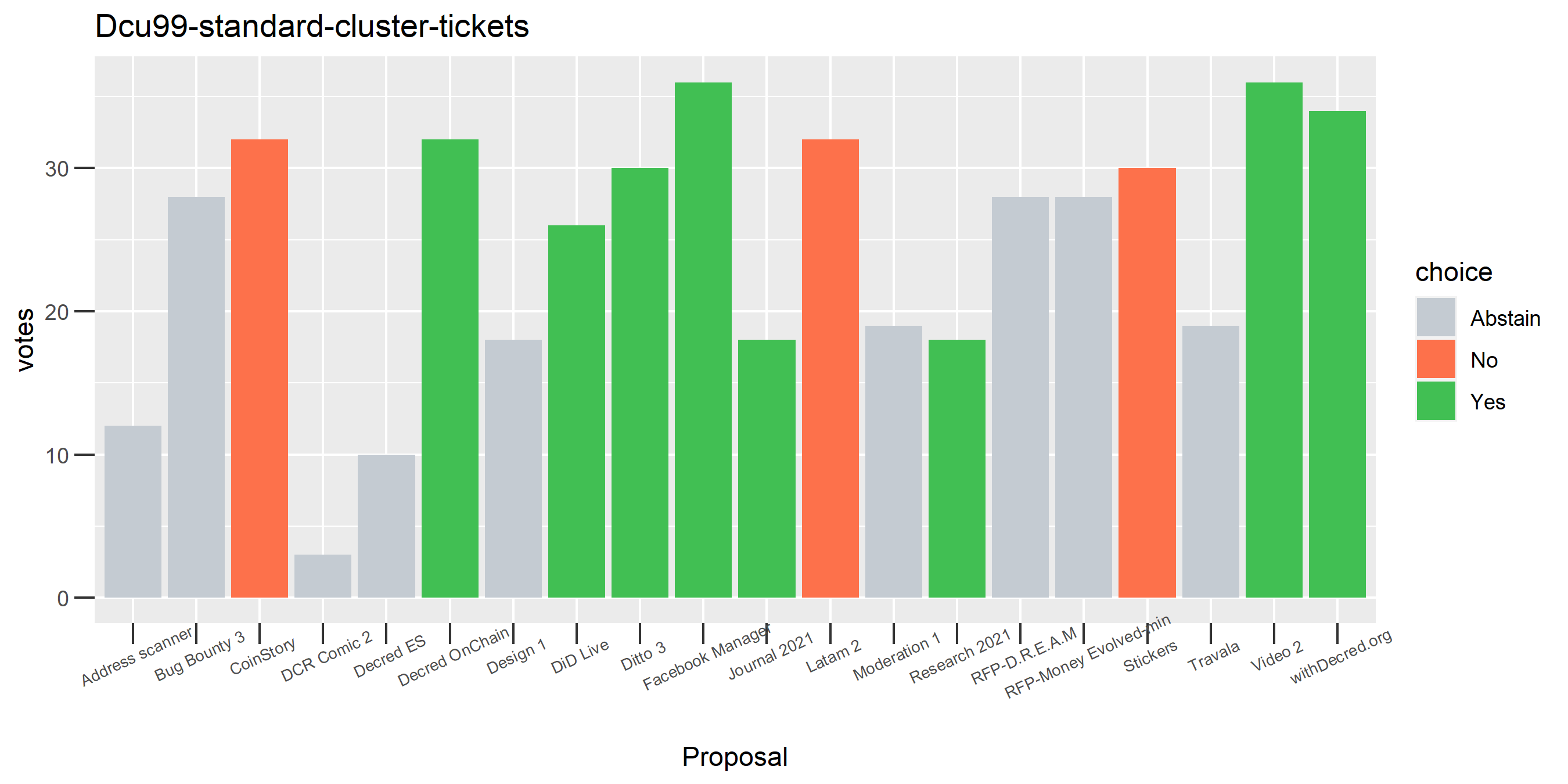
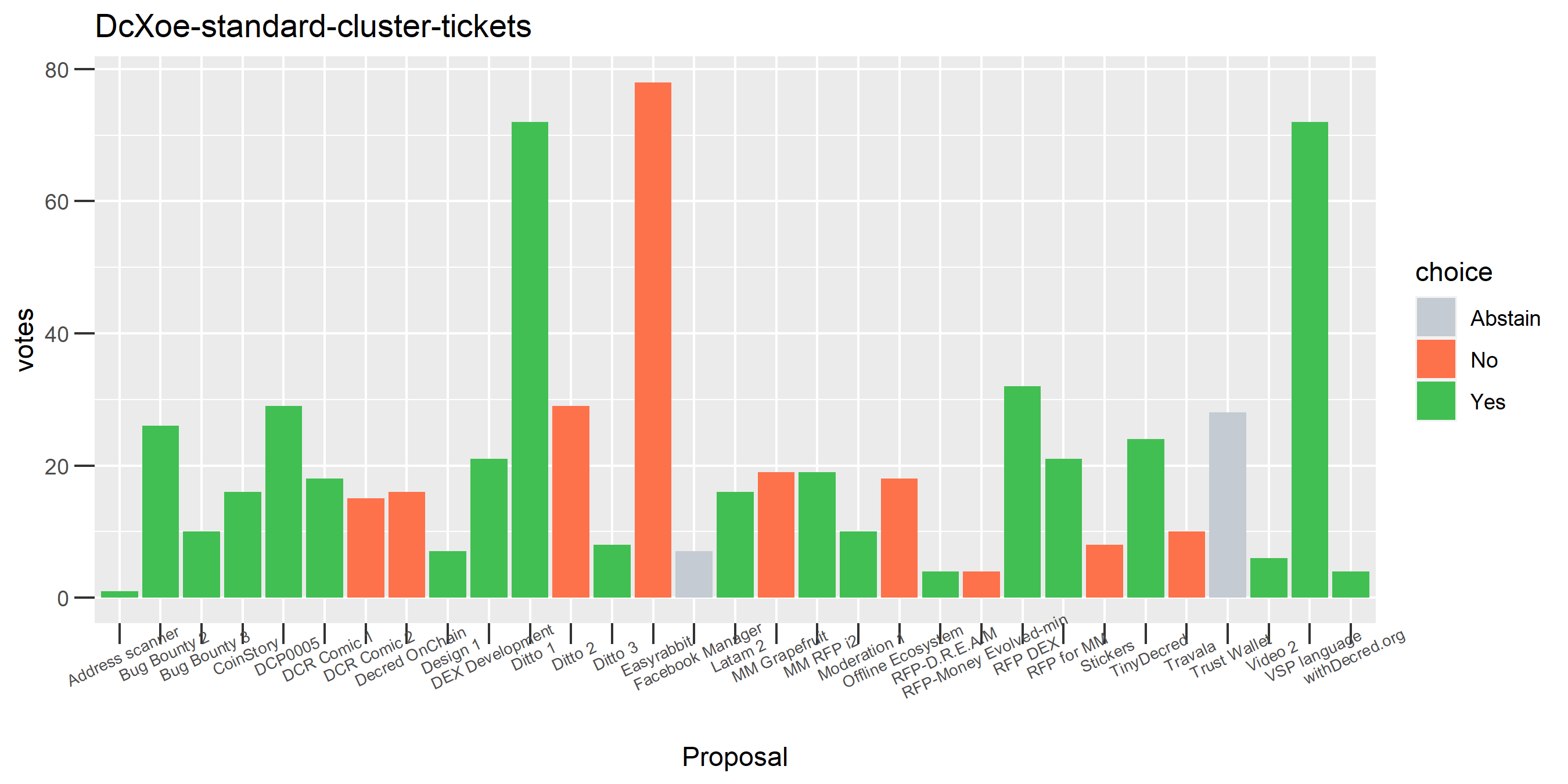
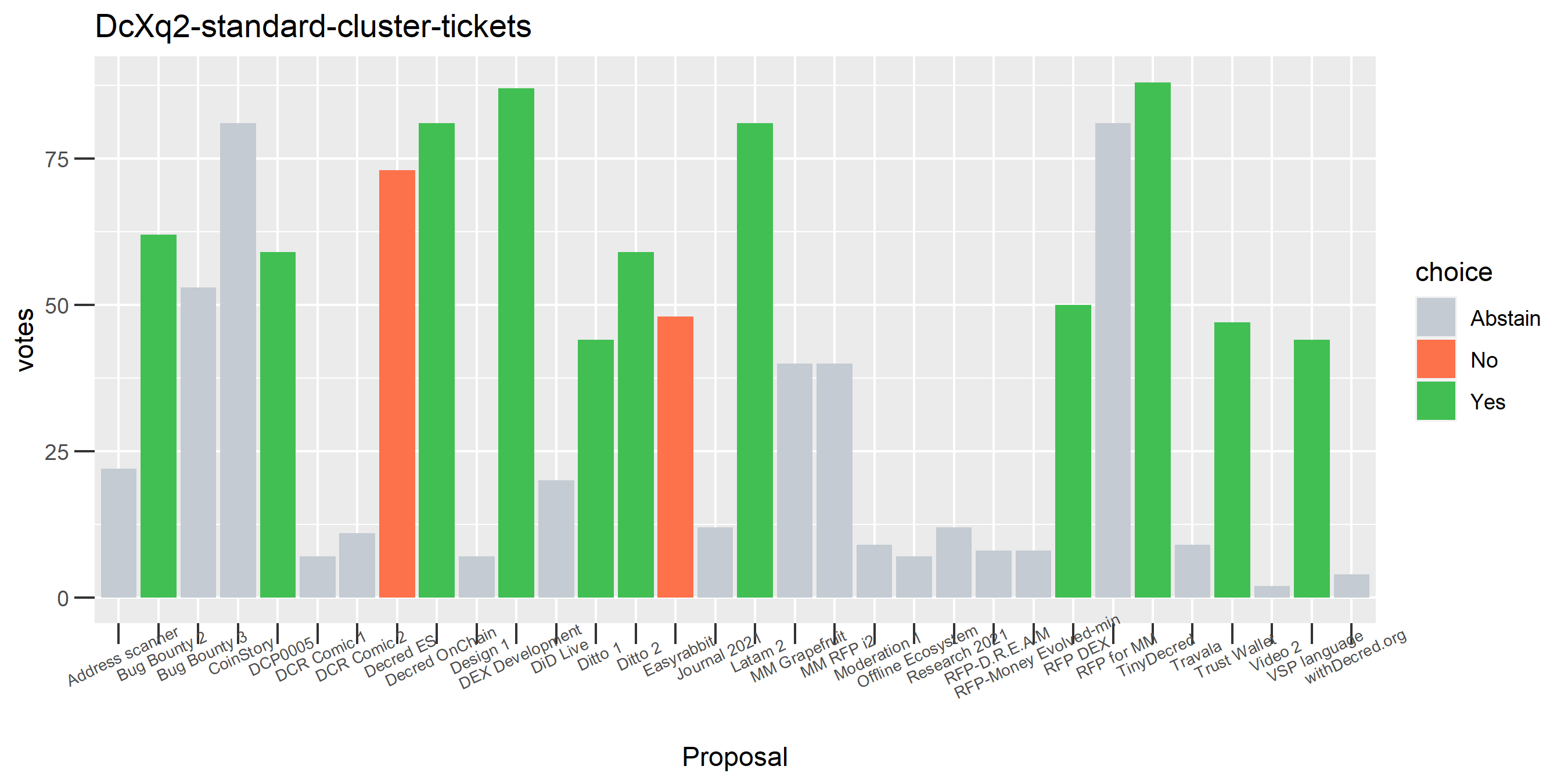
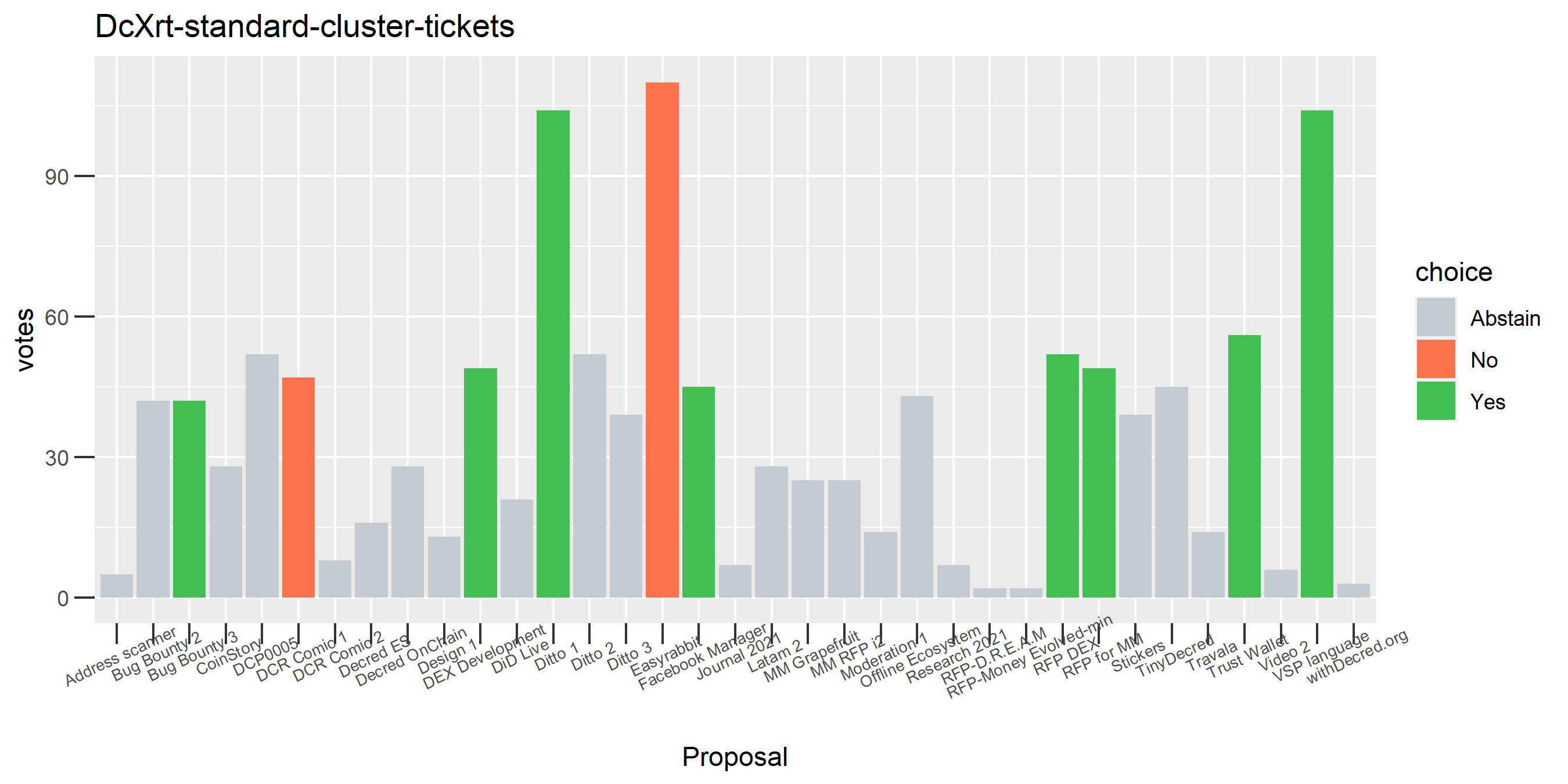
I picked the top 1,000 clusters by number of addresses and ran the functions to select all of their tickets and pull the voting record for each, then inspected all of these to see how common patterns of “self-contradictory” voting were and whether they looked likely to reflect genuine stakeholder behavior. The short answer is that self-contradictory voting is quite uncommon. I feature every cluster which exhibited this behavior below along with a note. I have also selected a number of clusters with a longer voting record, as these are quite interesting to look at and I suspect usually represent individual humans.
But first those outliers.
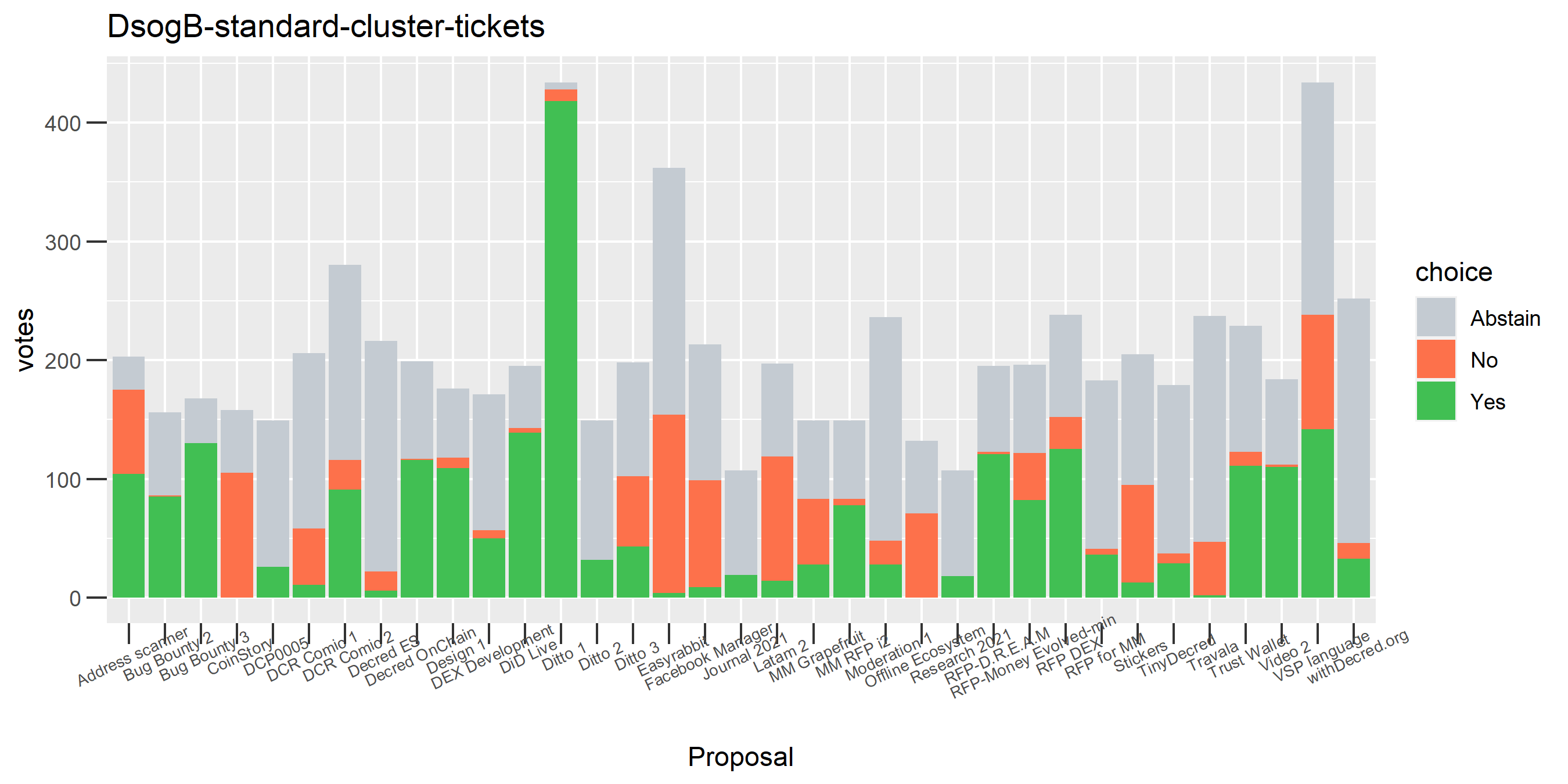
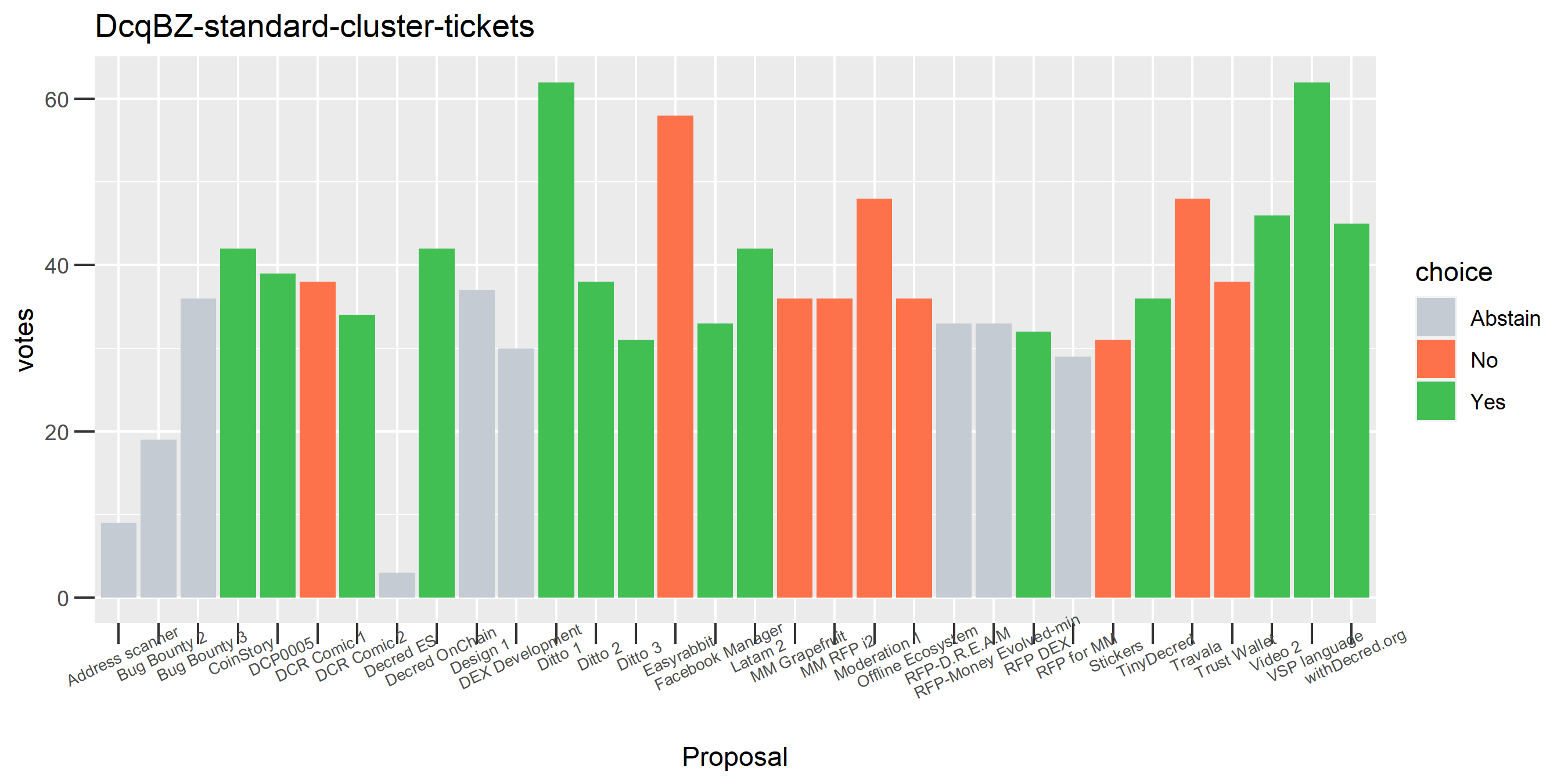
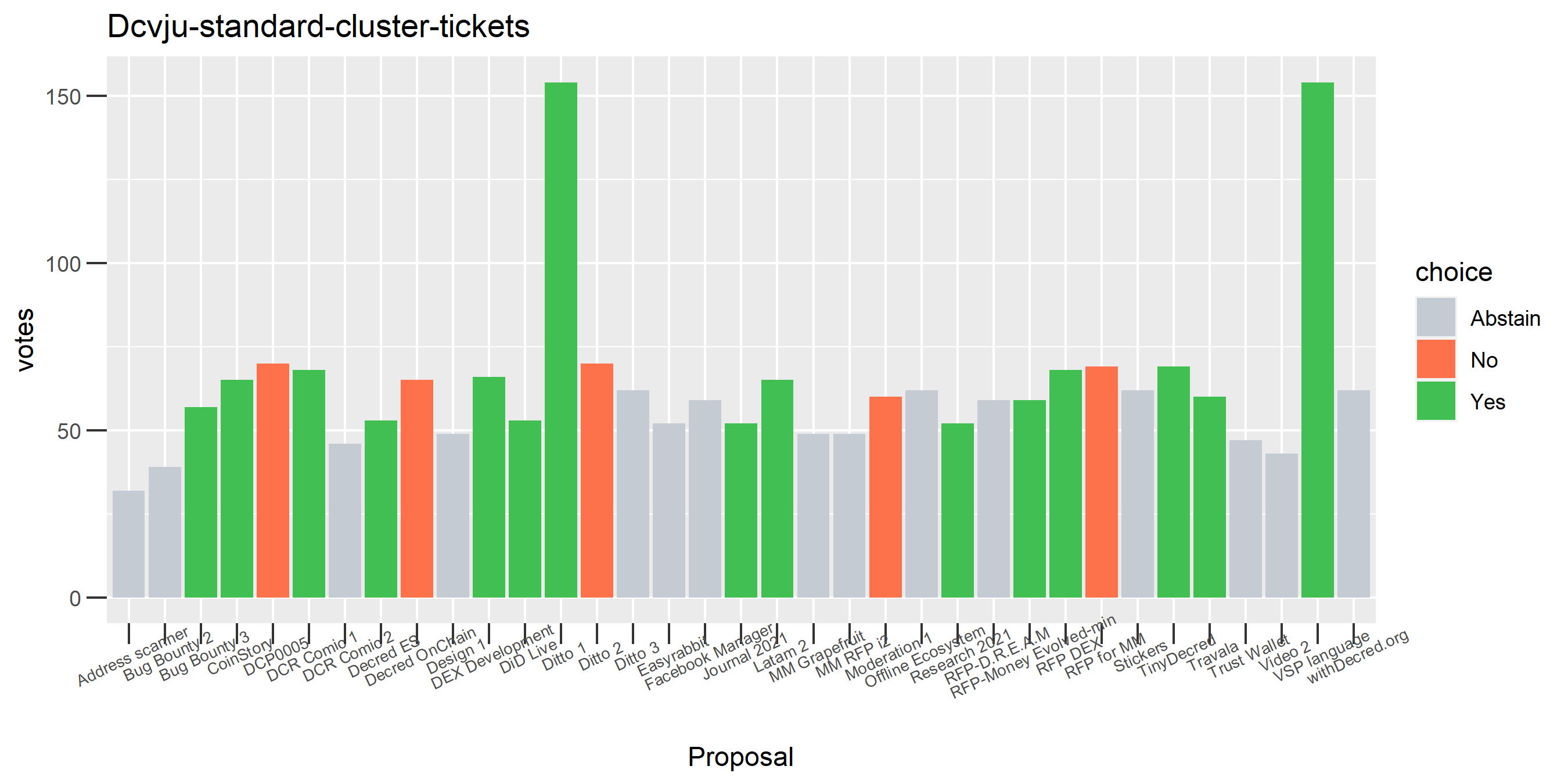
Unfortunately there is still something going wrong with this DsogB cluster - it looks like a stakepool for which all the tickets are being intermingled. It’s quite possible this relates to ticket splitting, where people pool DCR to buy tickets. In any case the magnitude of the issue is quite small under this clustering formulation, only 0.5 - 1% of tickets in the pool are falling into the problem cluster.
Also, there comes a time where one can’t spend any longer on the cycle of clustering -> checking -> reclustering when it’s taking over a week to do each limited clustering run.
The rest of these are still pretty interesting.
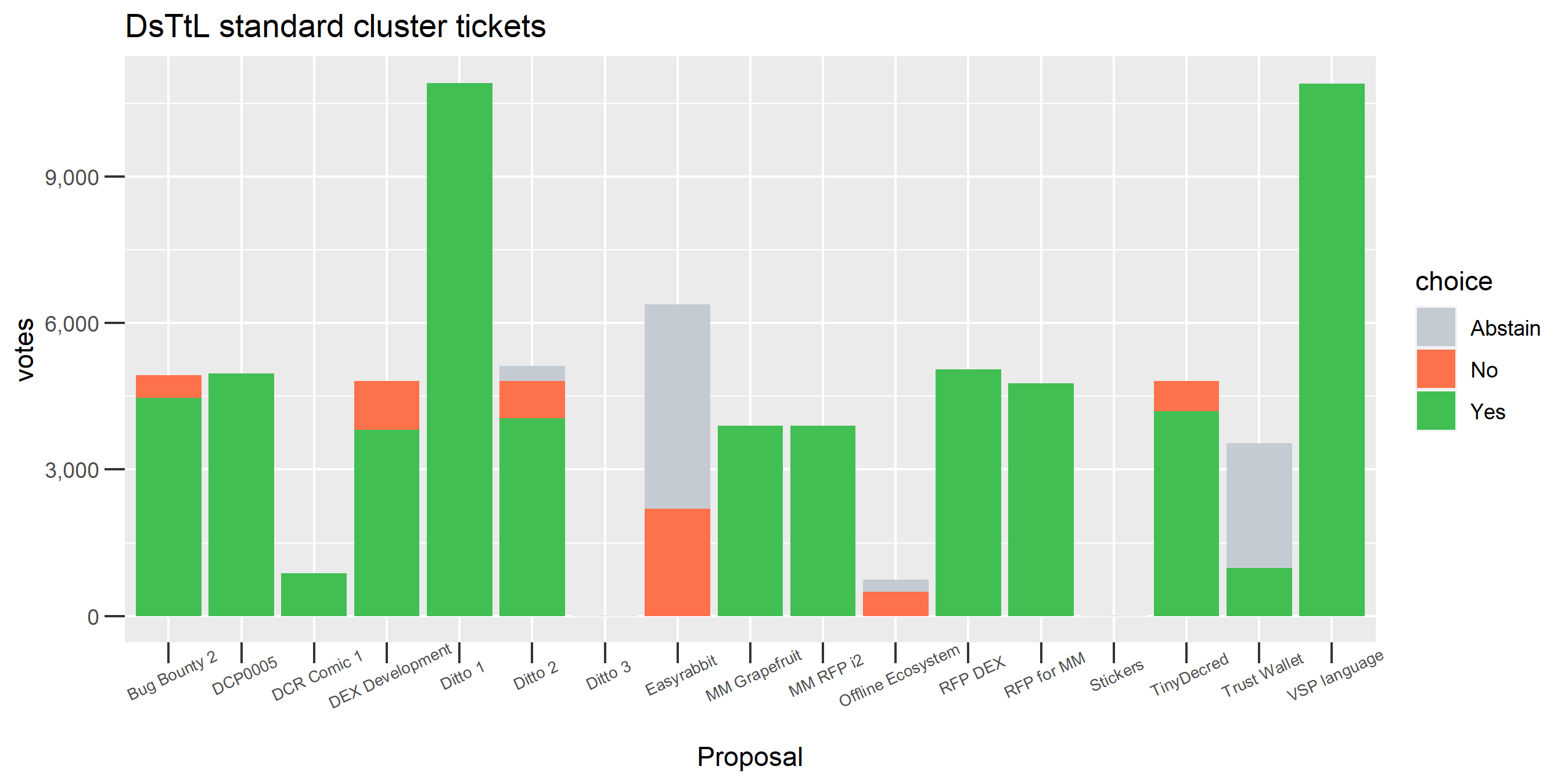
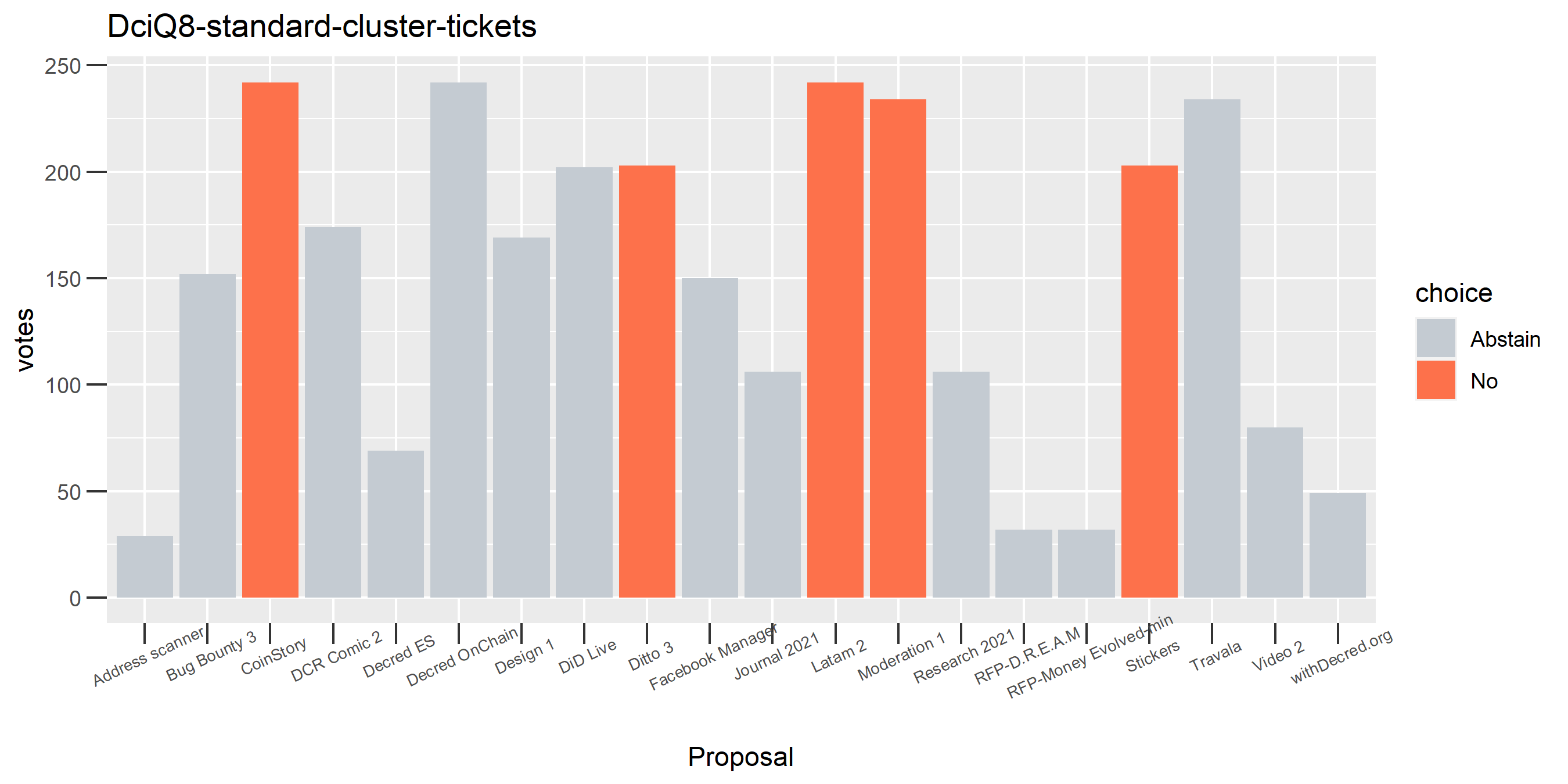
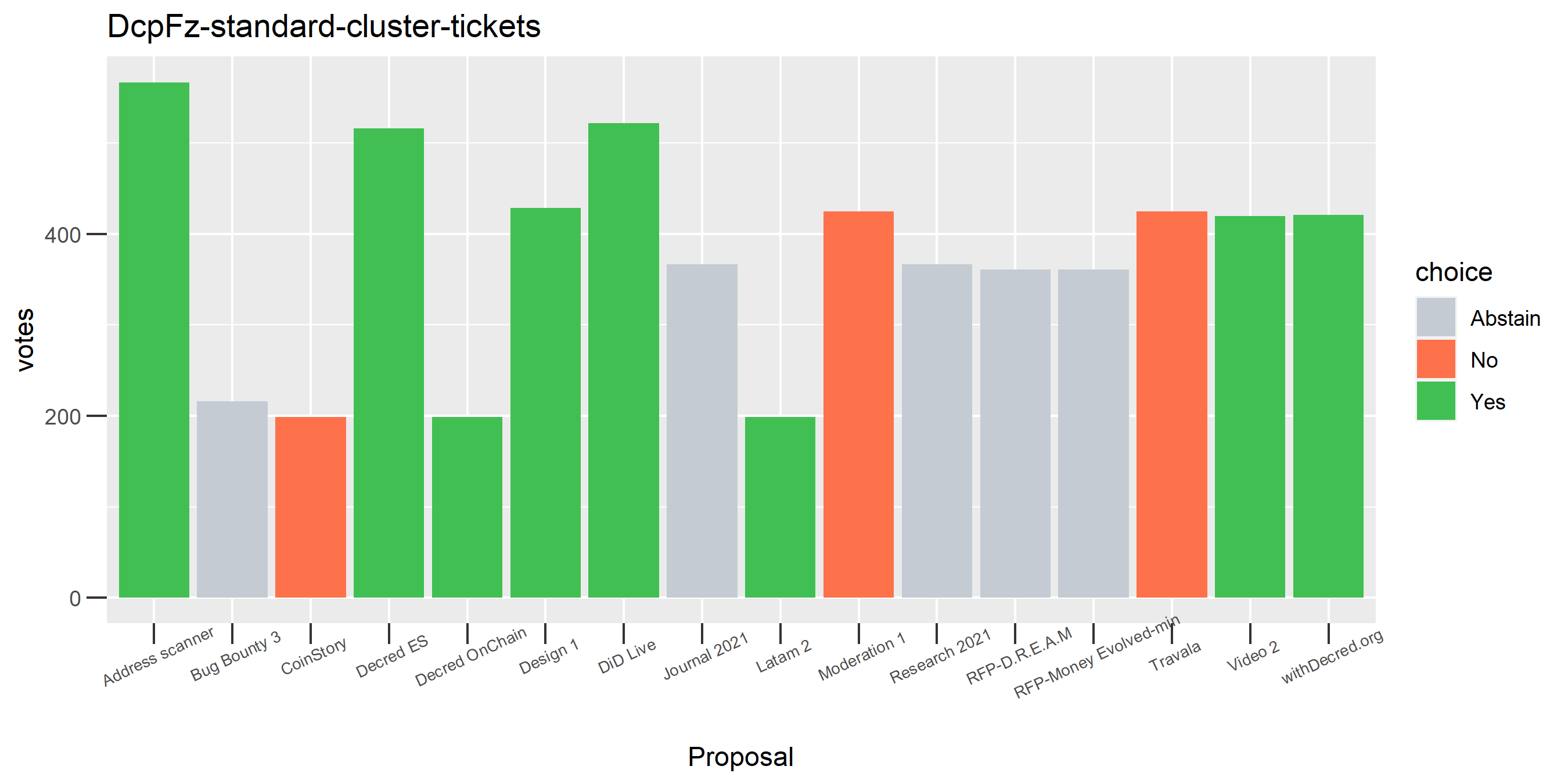
This cluster is associated with the founders’ reward, some interesting patterns of contradictory voting.
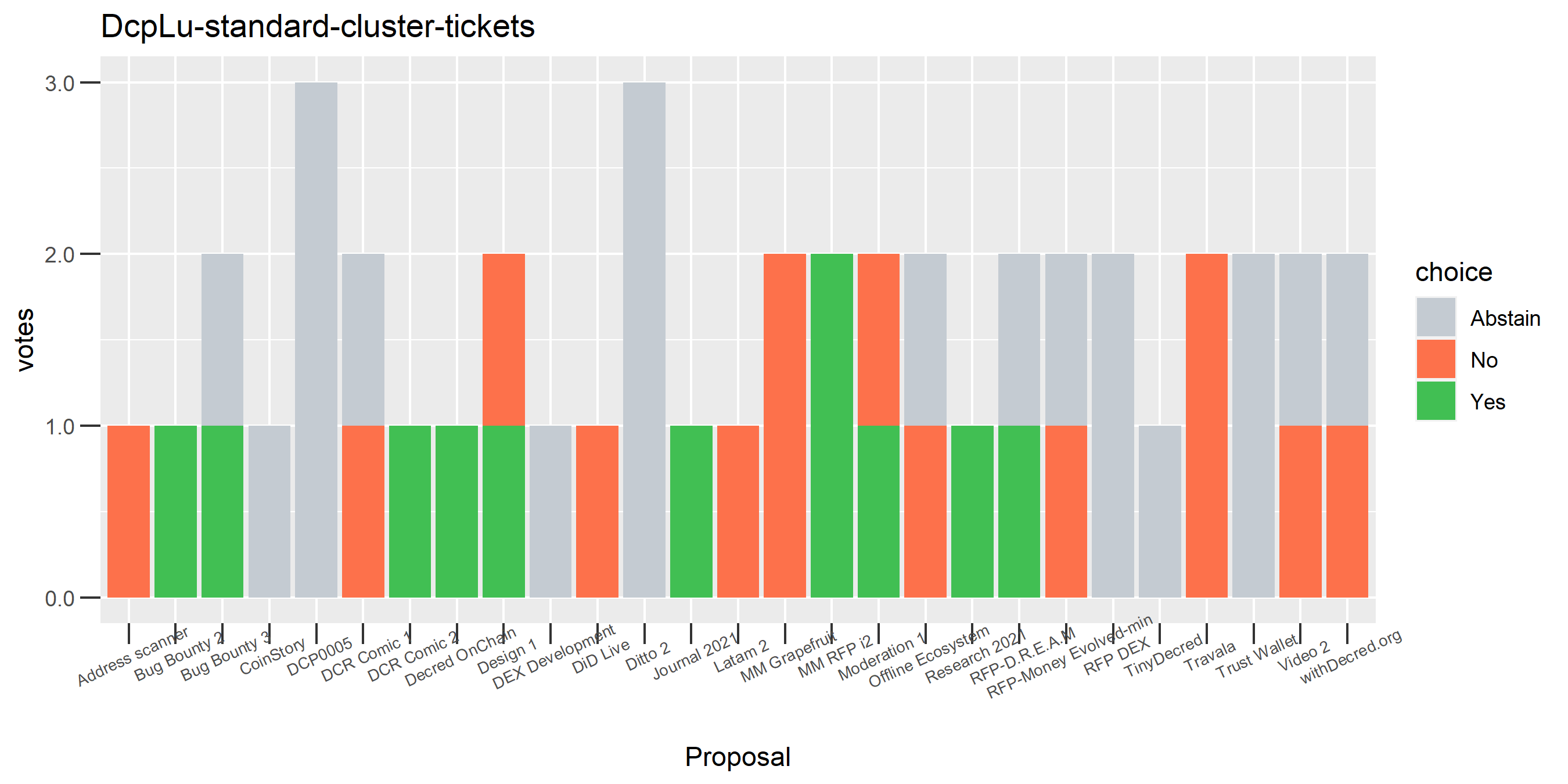
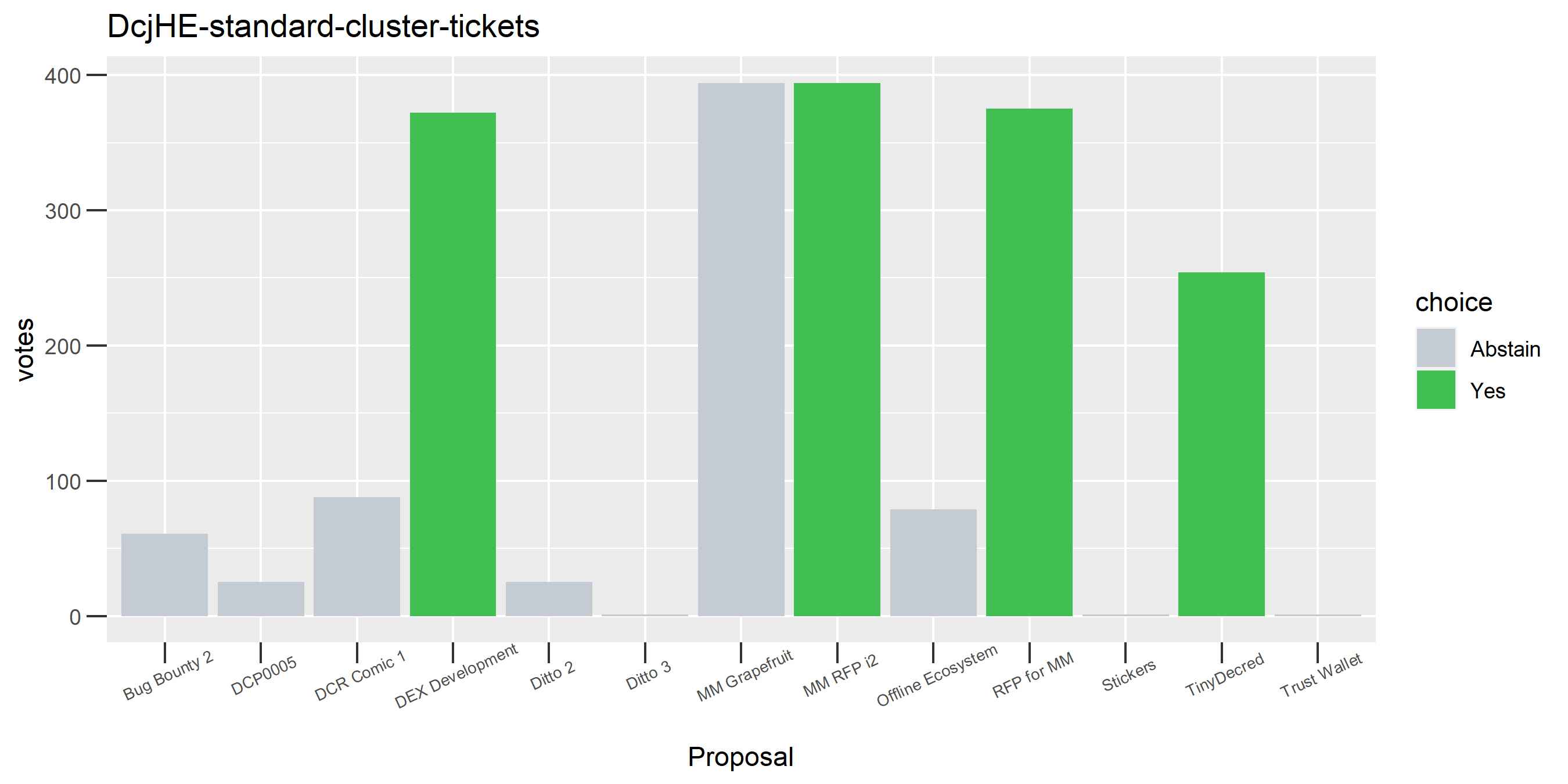
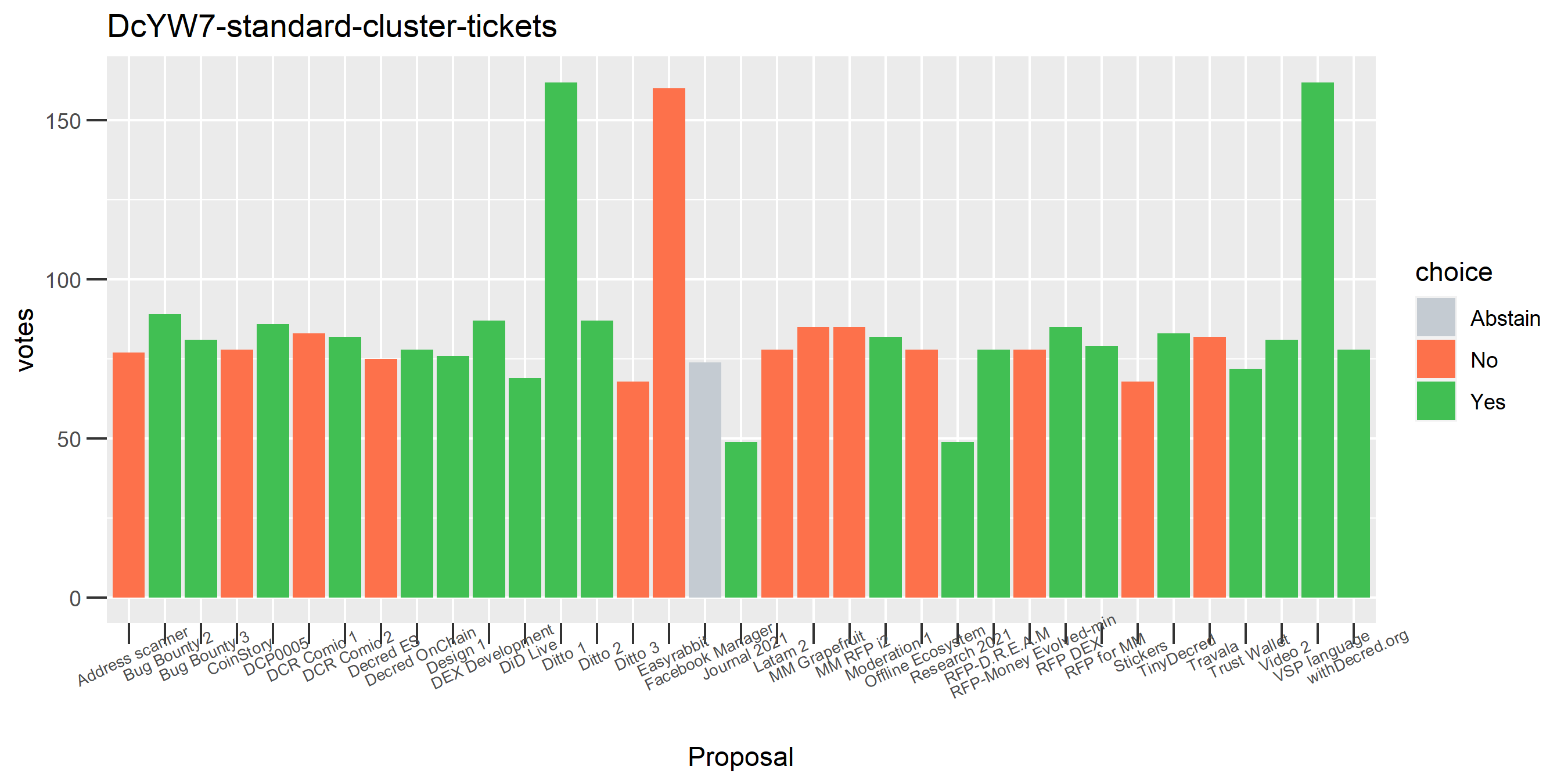
I’ve seen a bit of this, where a cluster has just a couple of tickets but they vote in opposite directions on a proposal. Strange. It could be the continuation of the deliberate self-contradictory voting seen in the “regular voting address re-use era”, now with tickets that are spread across many addresses and transactions.
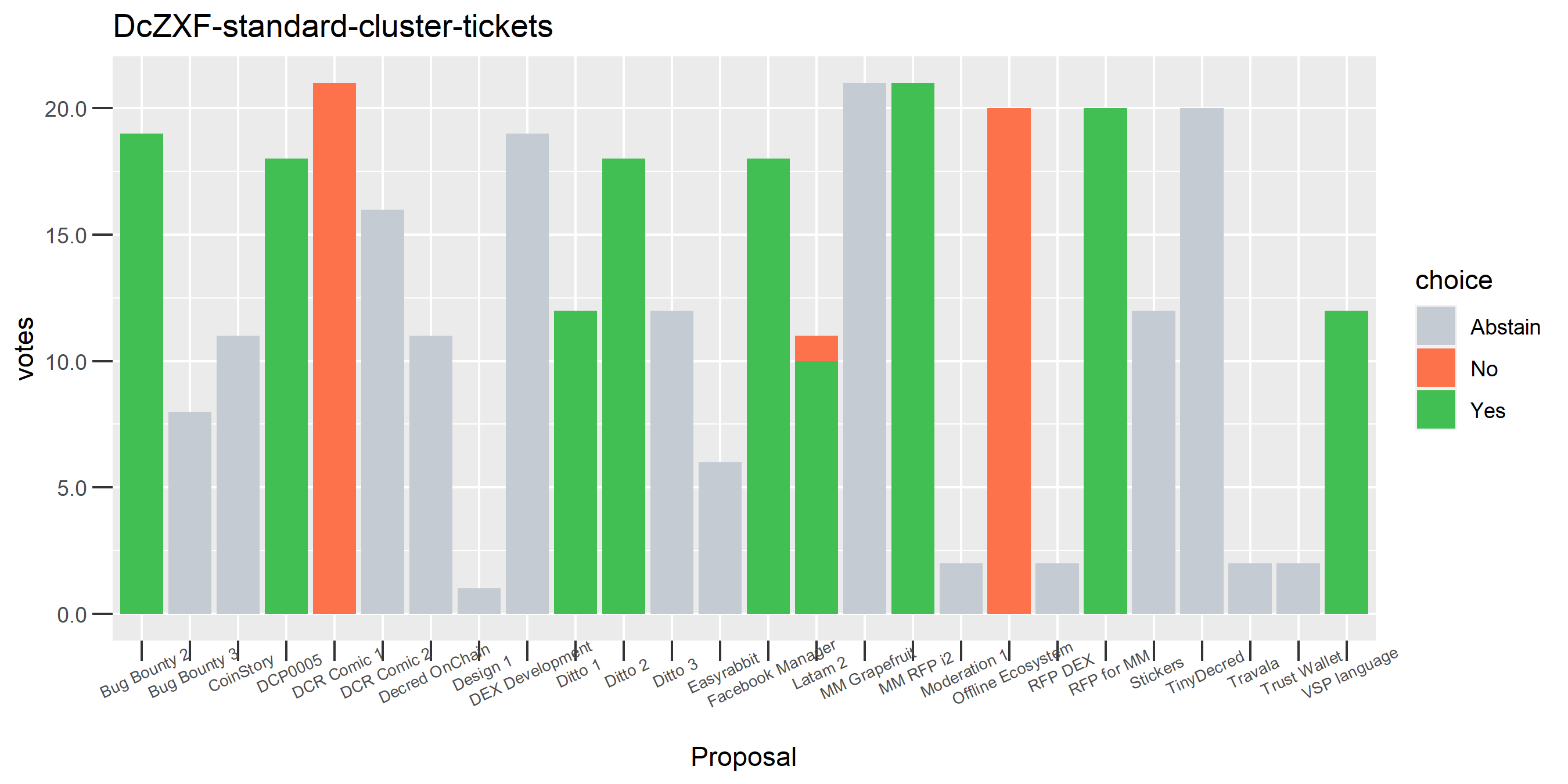
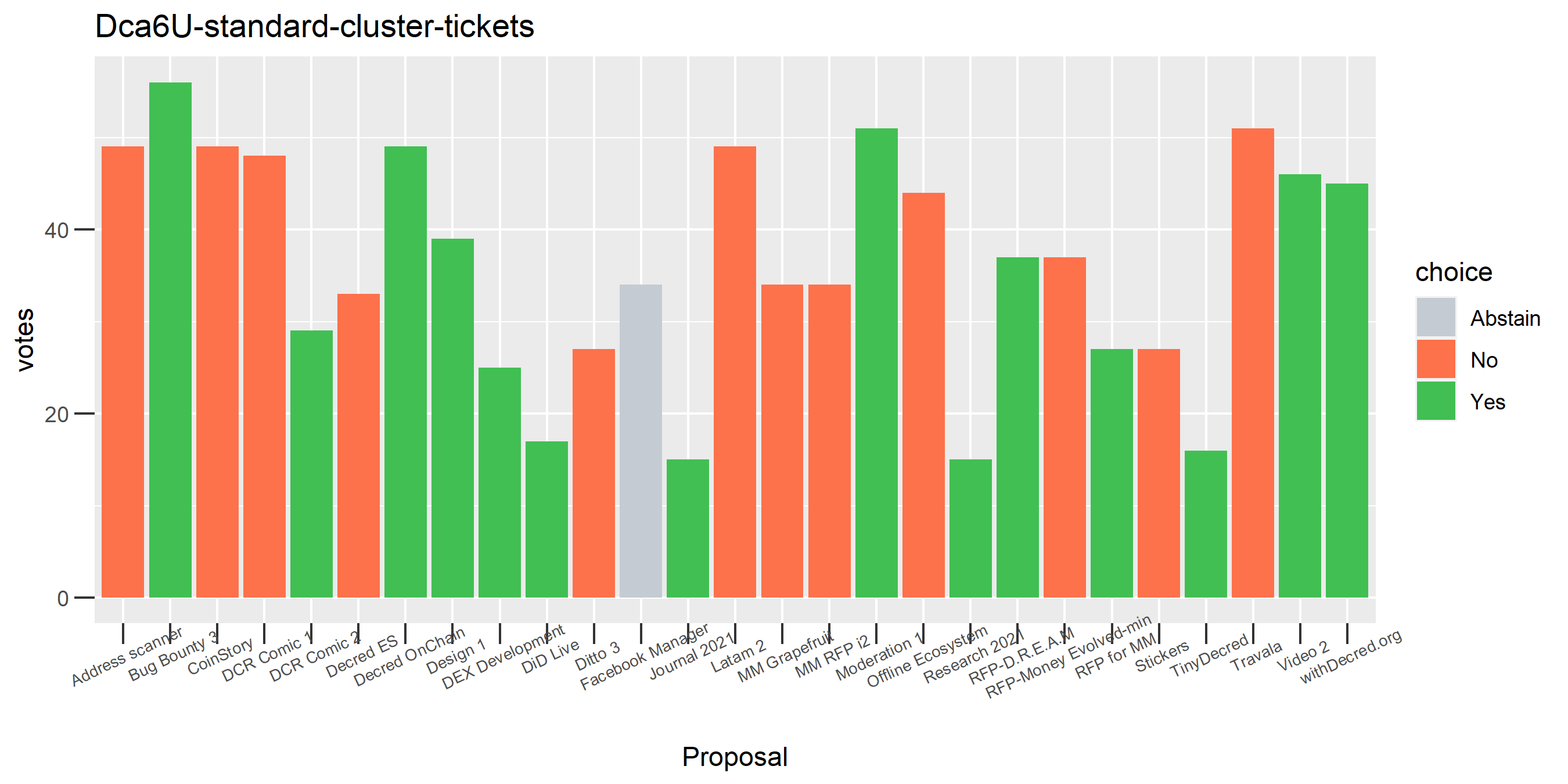
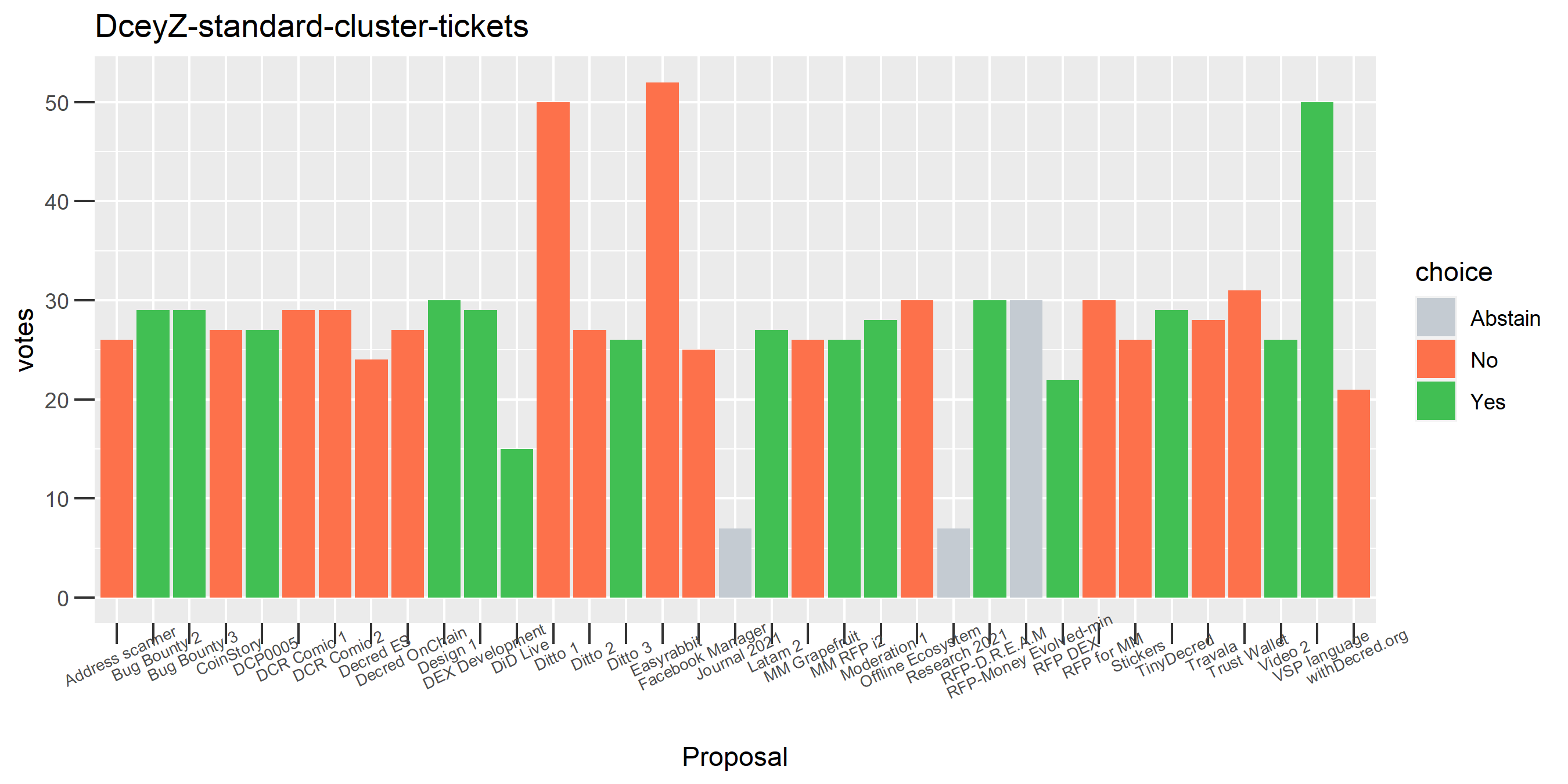
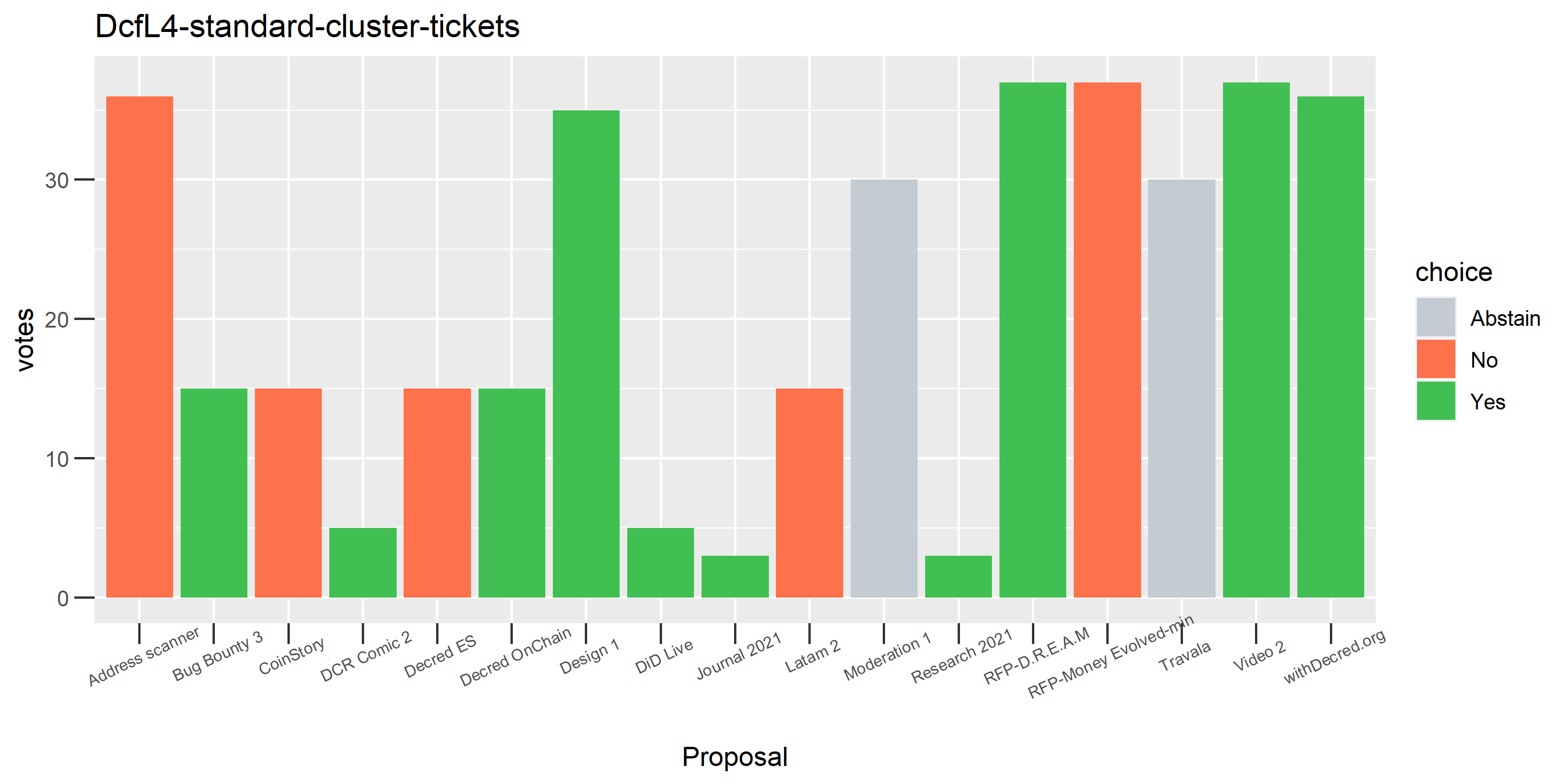
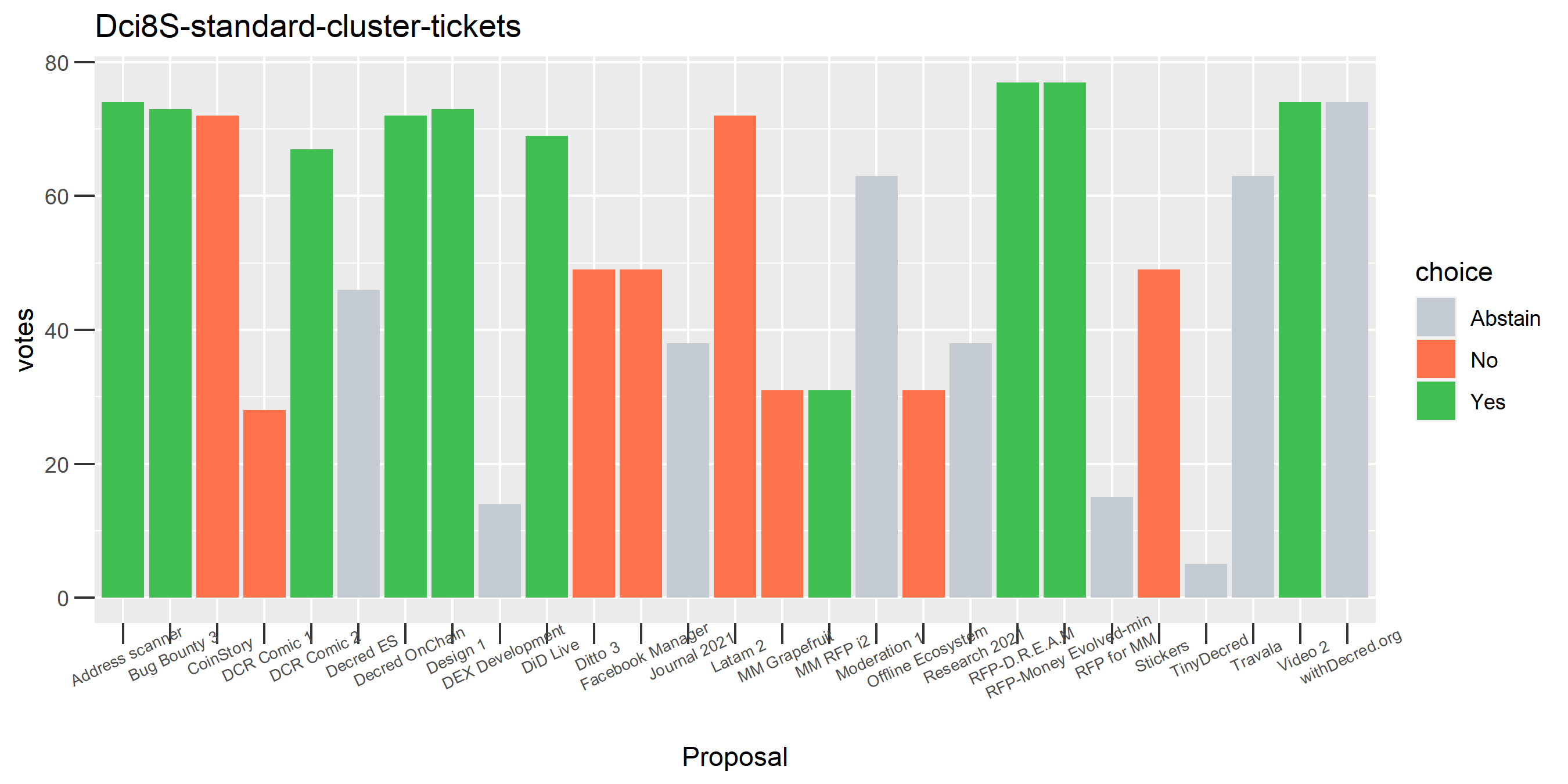
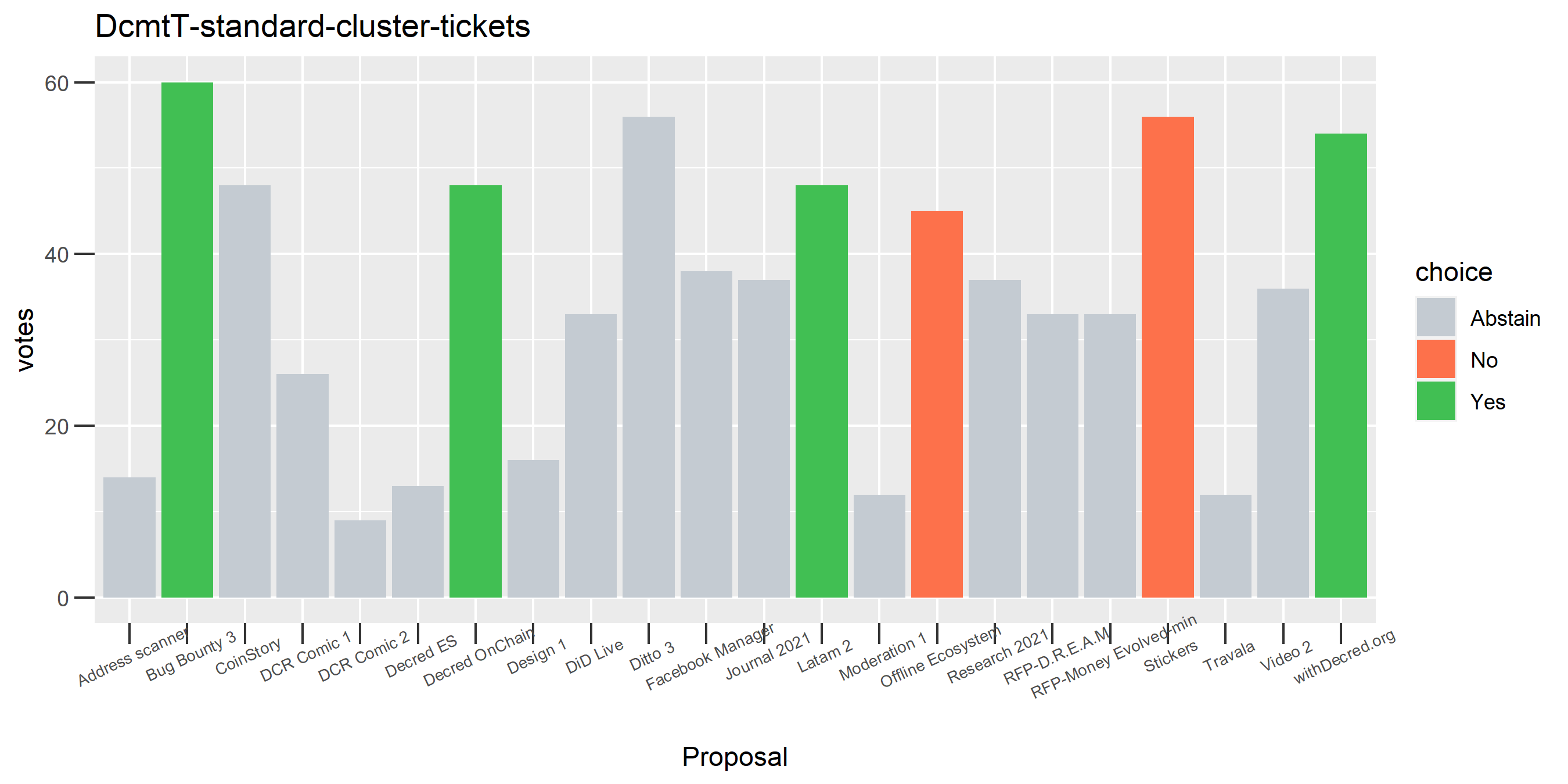
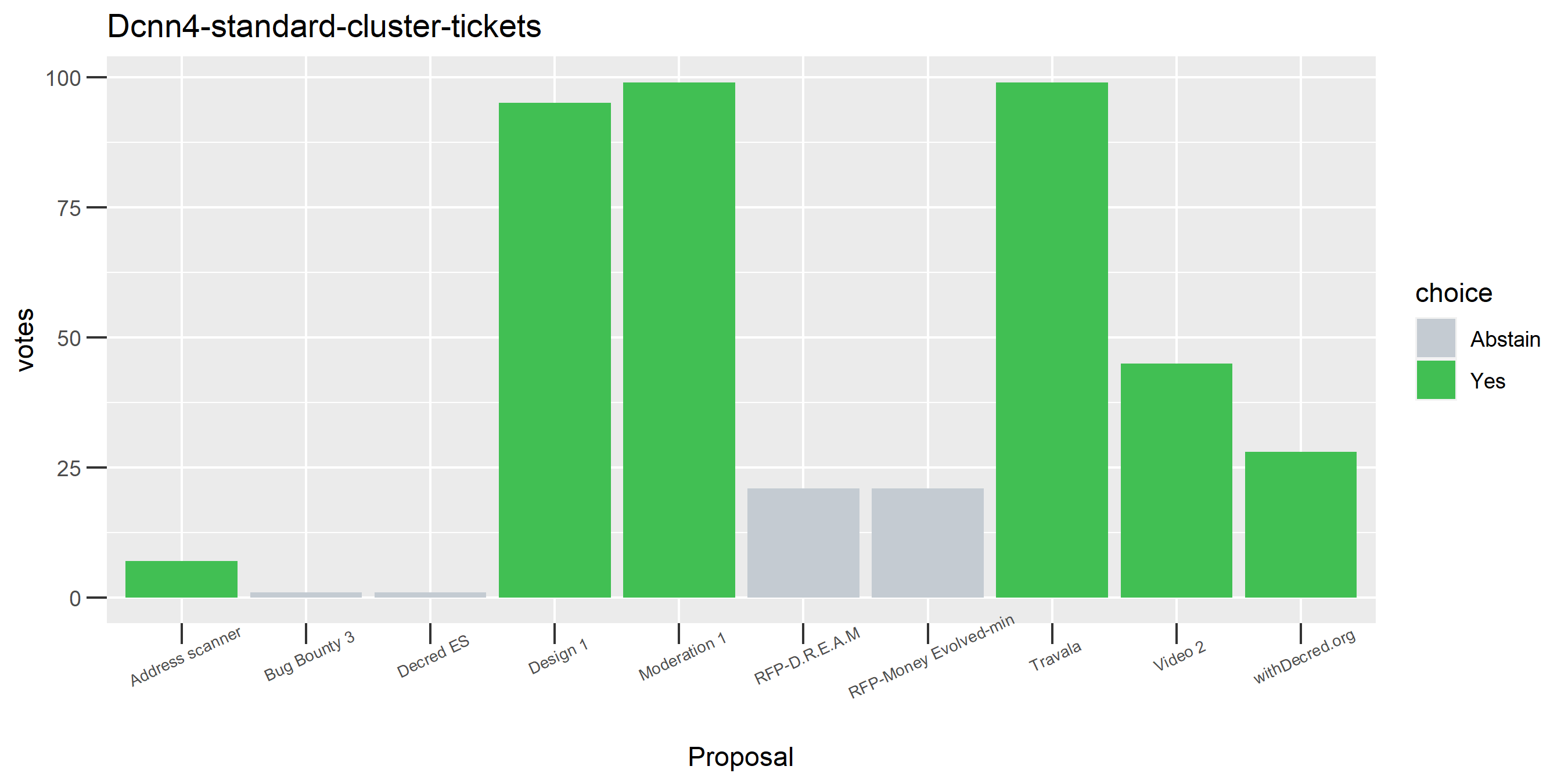
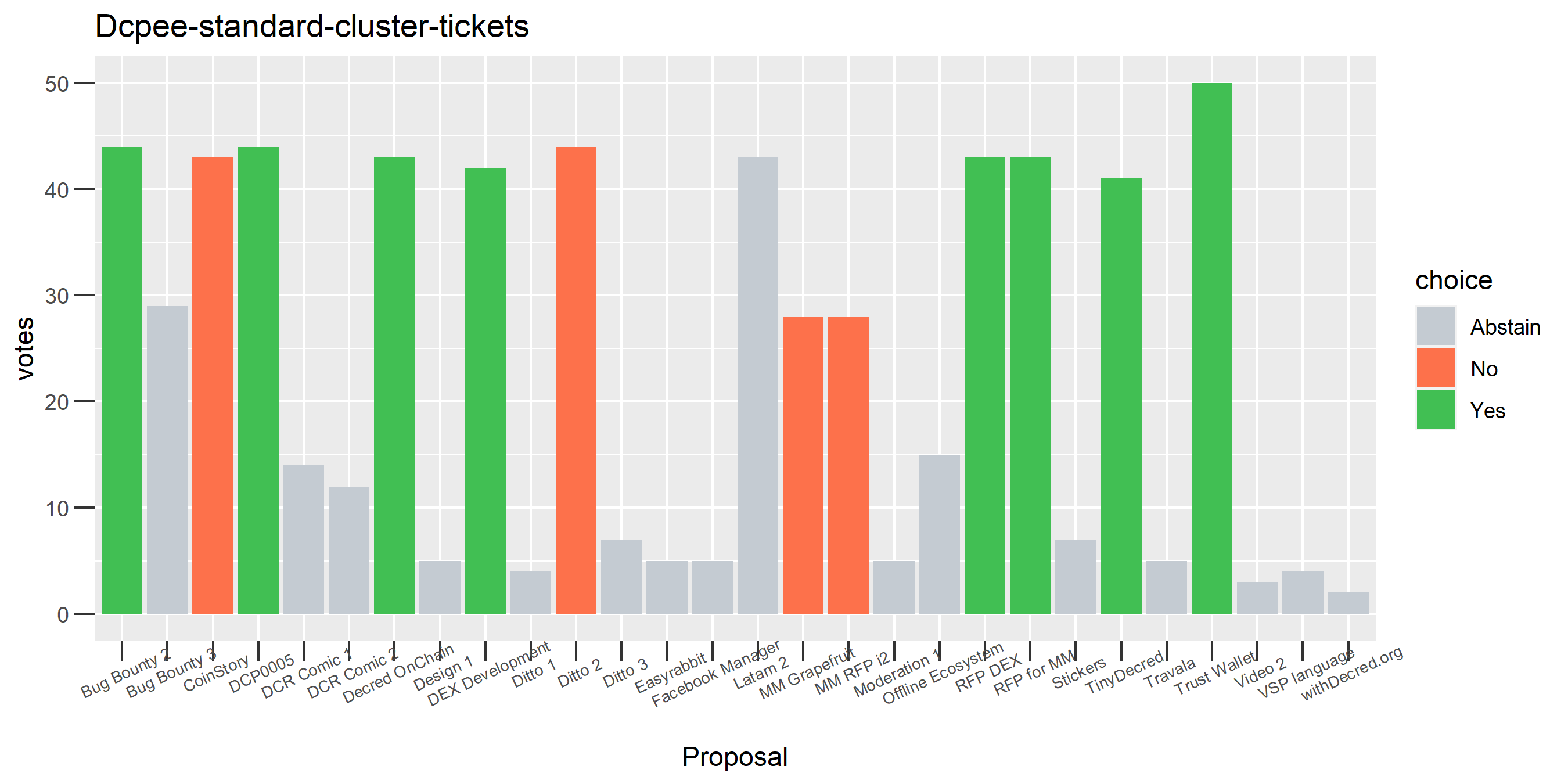
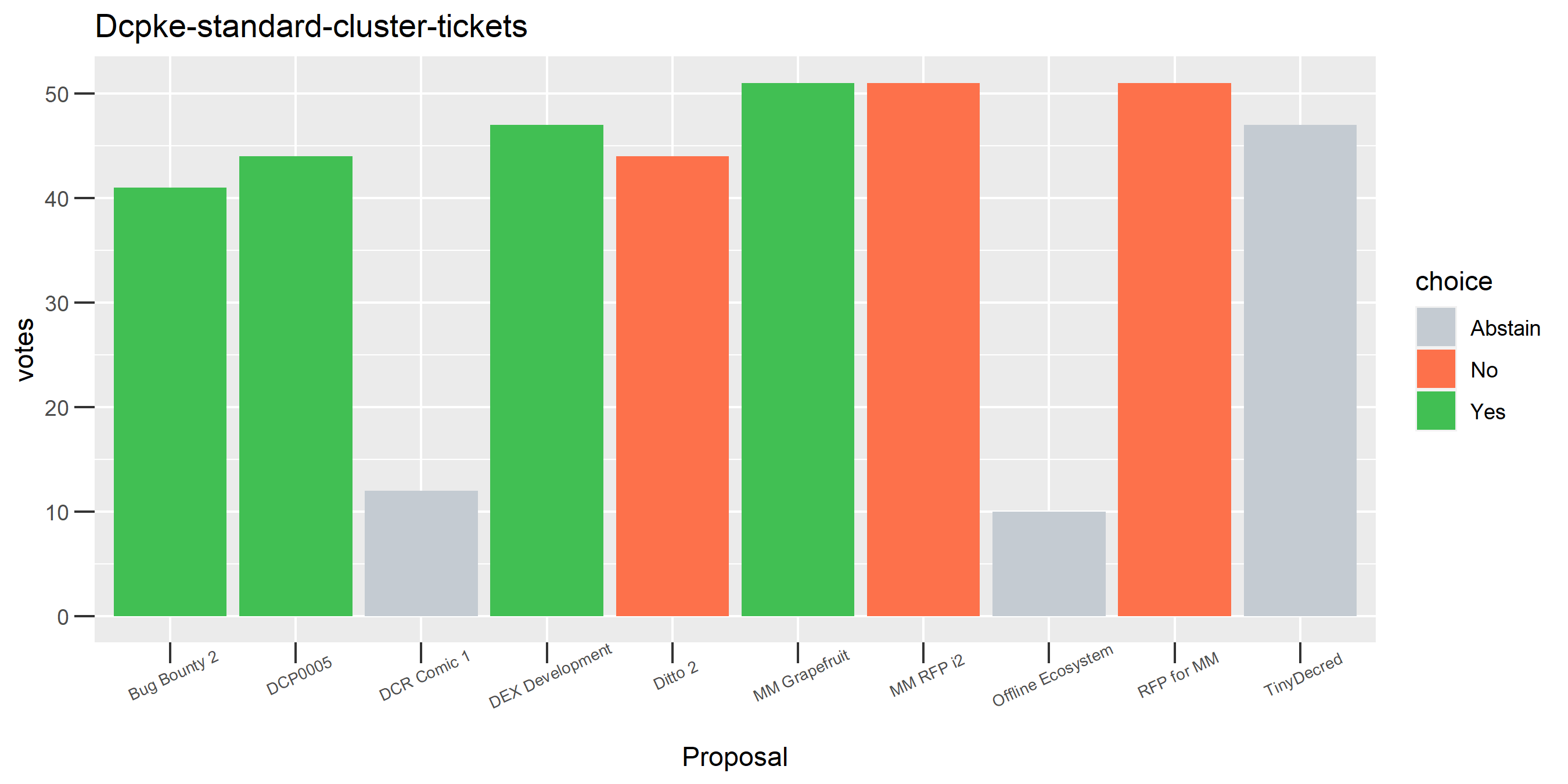
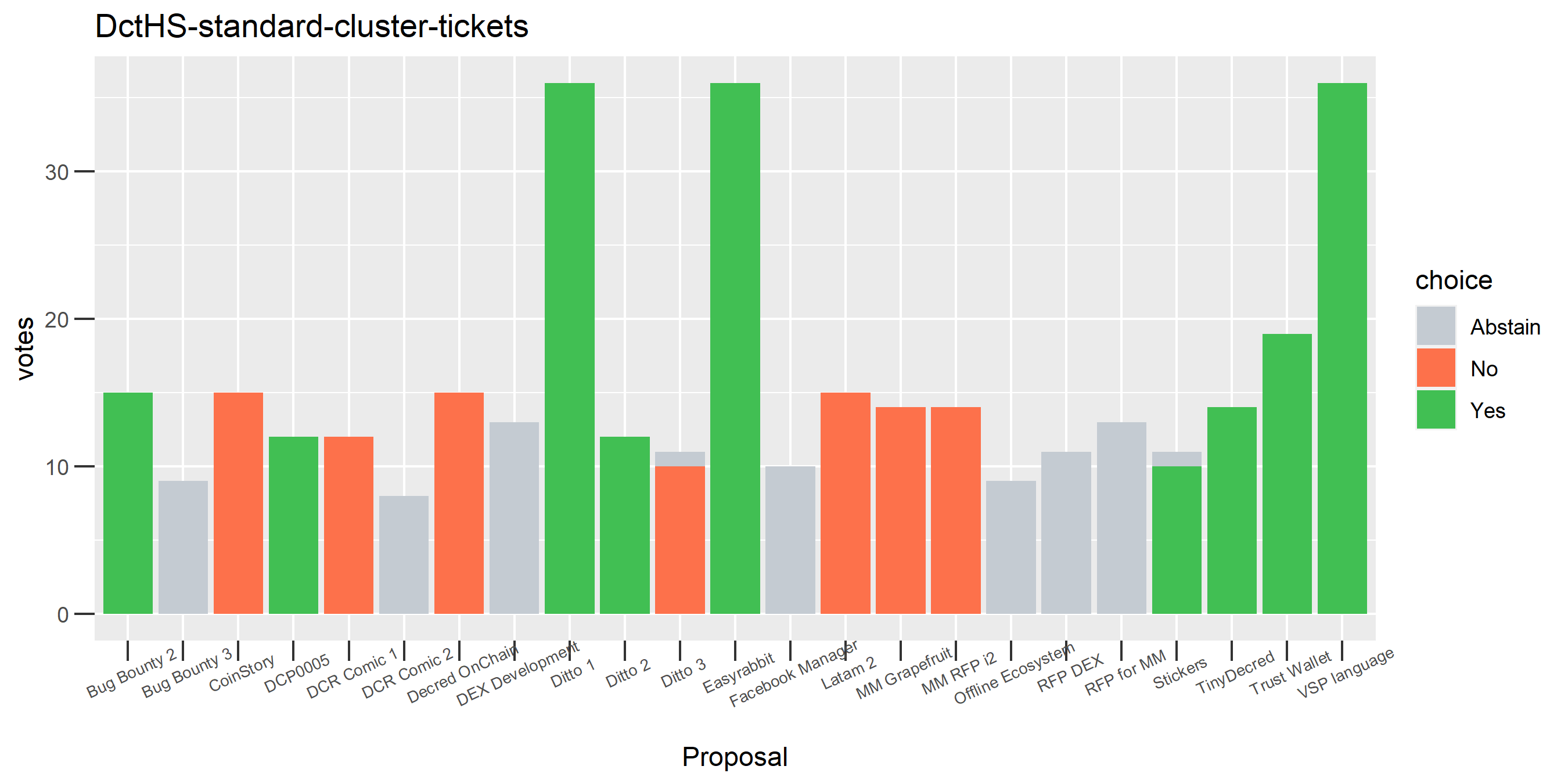
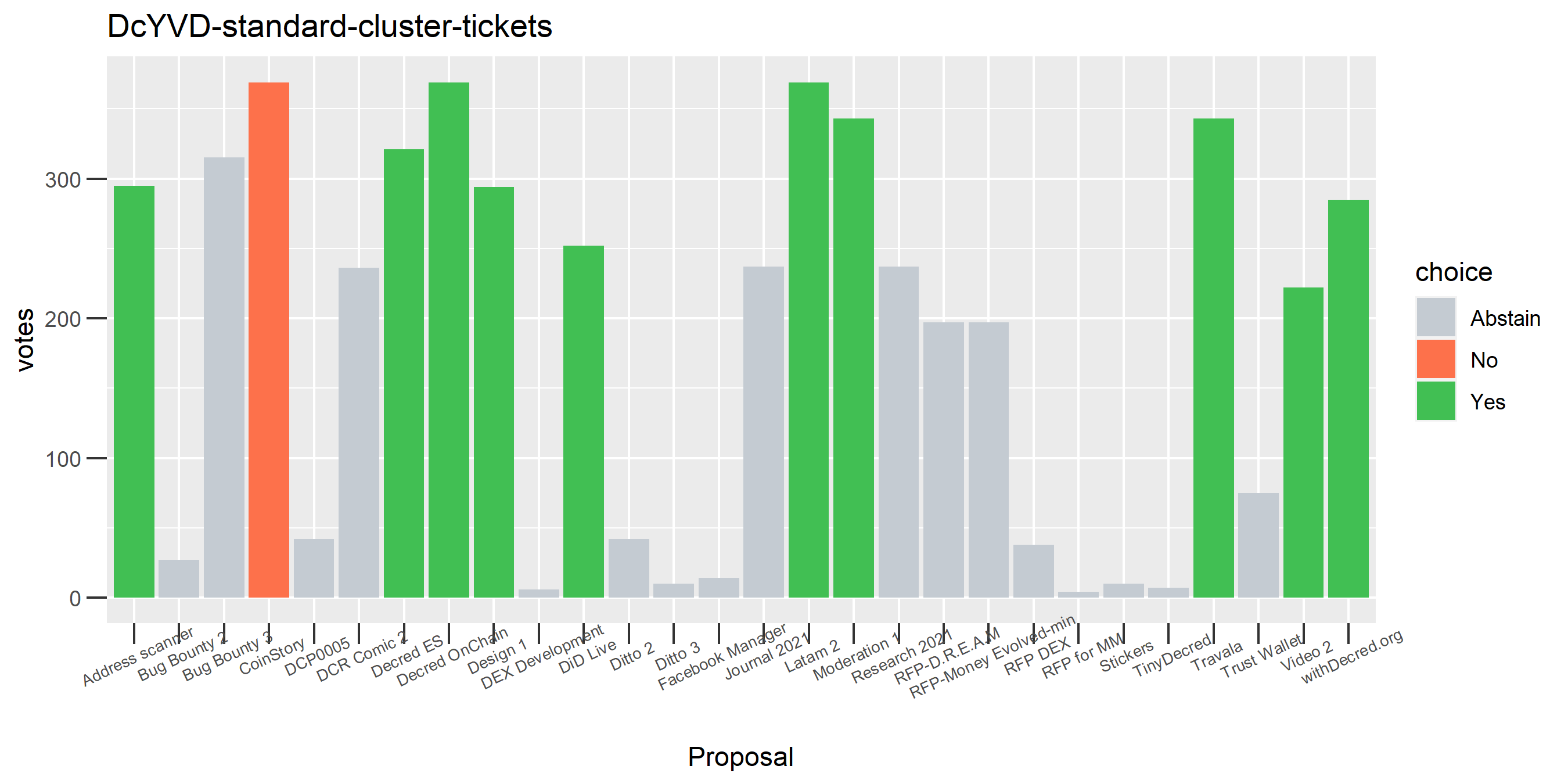
One proposal with contradictory votes, probably the voter changed their mind on the Latam 2 proposal while using politeiavoter voting.
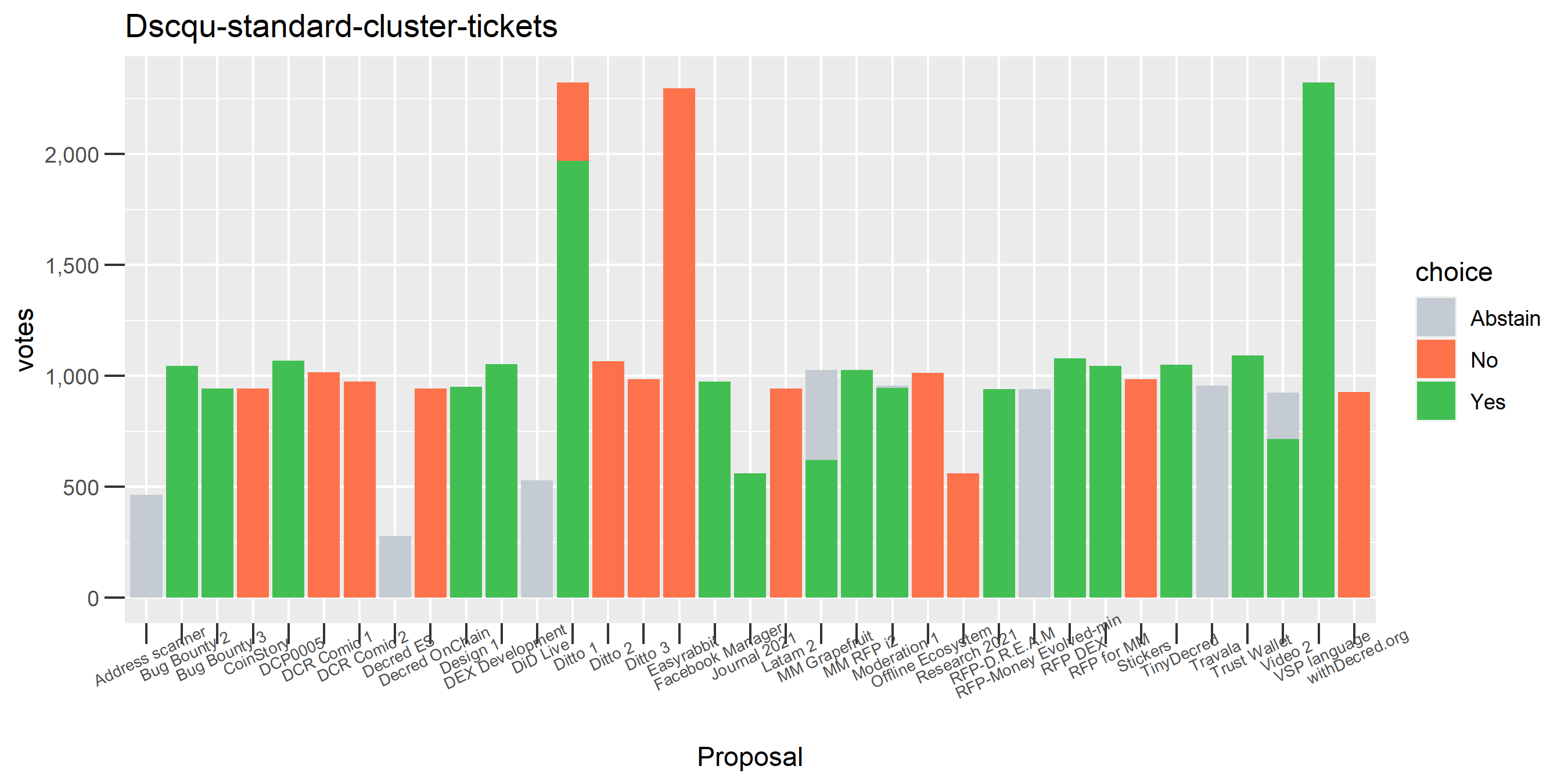
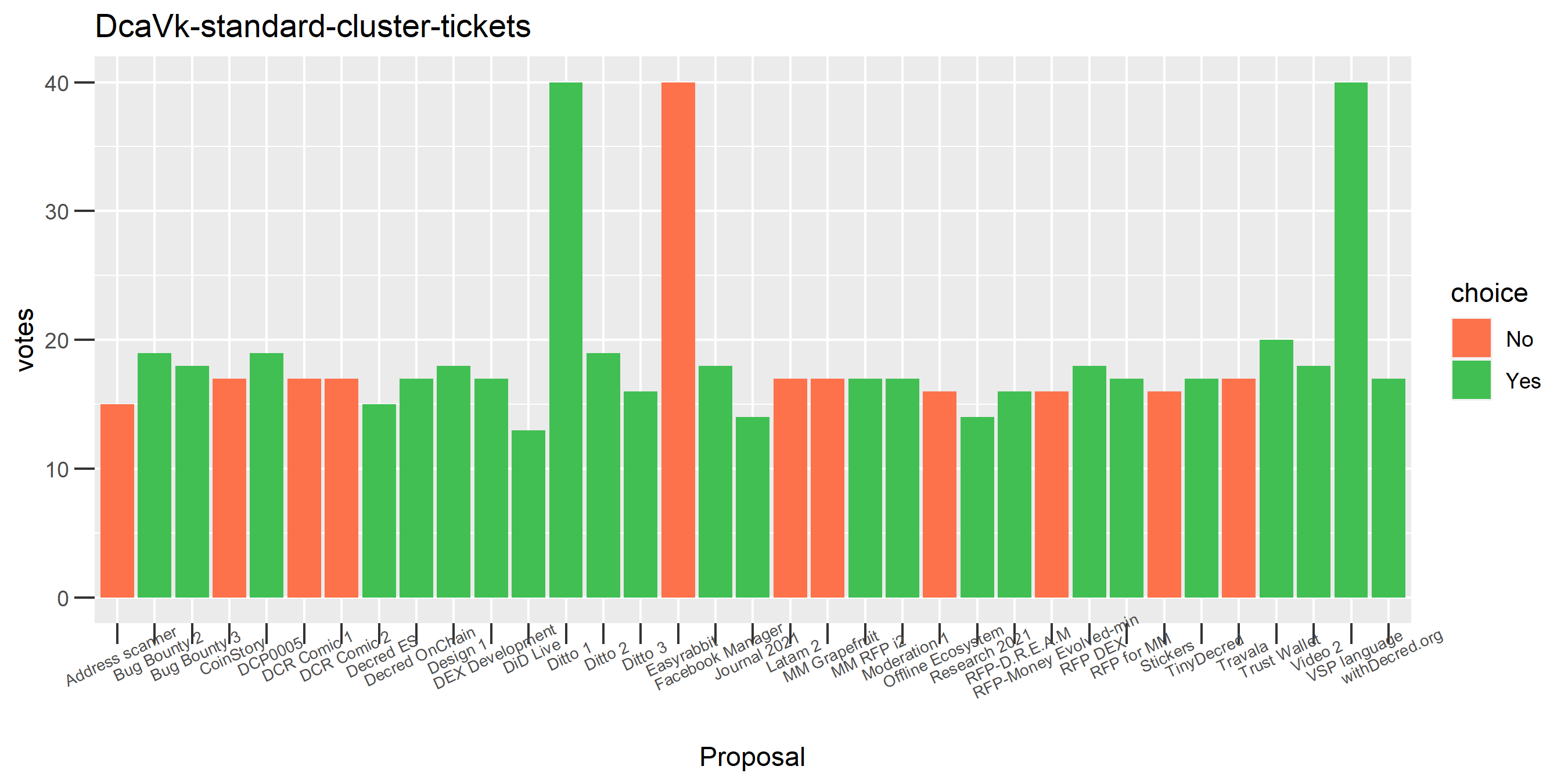
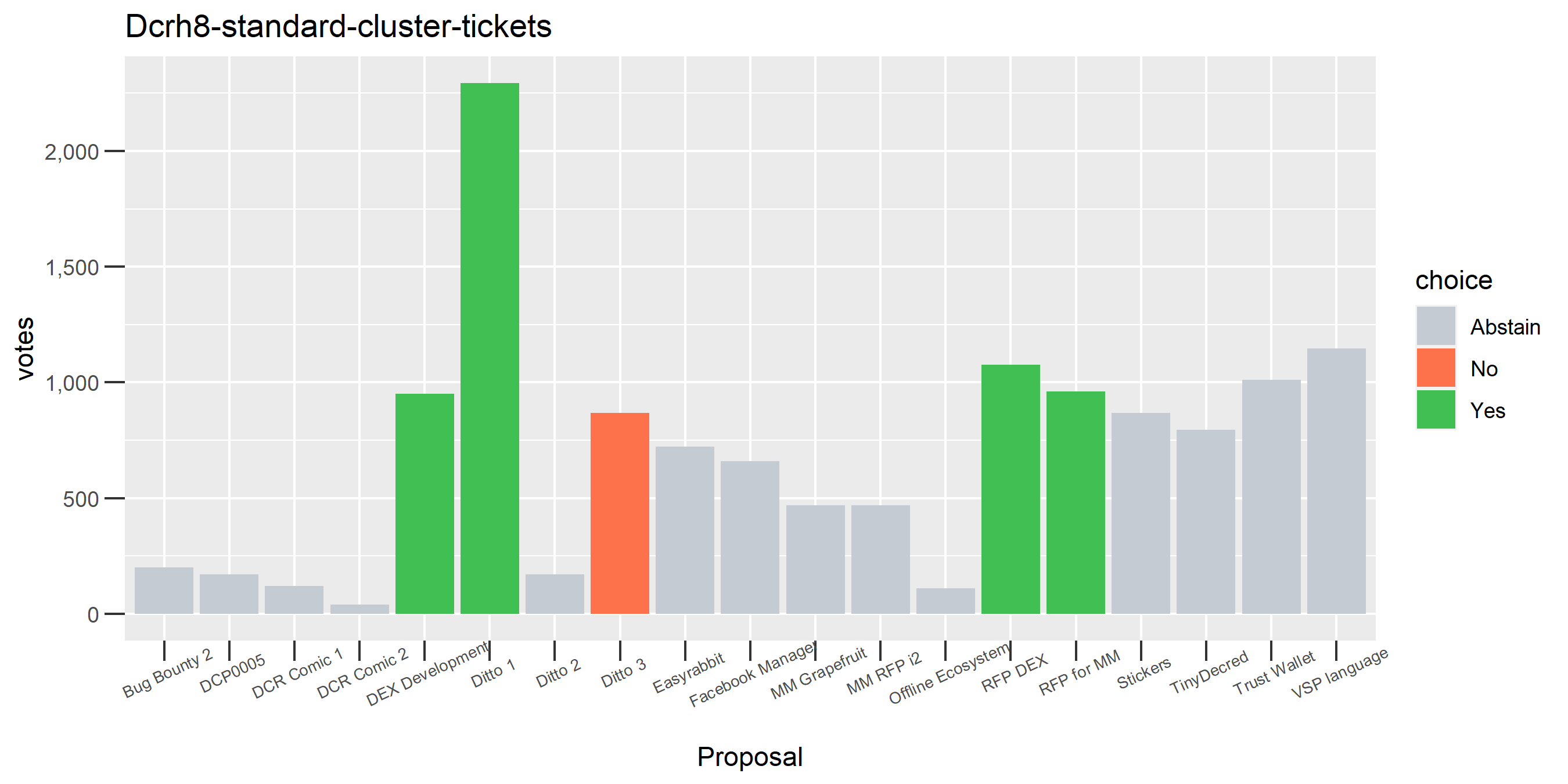
We saw this one earlier on just for the voting address, this time with the full clustering treatment and proposal labels.
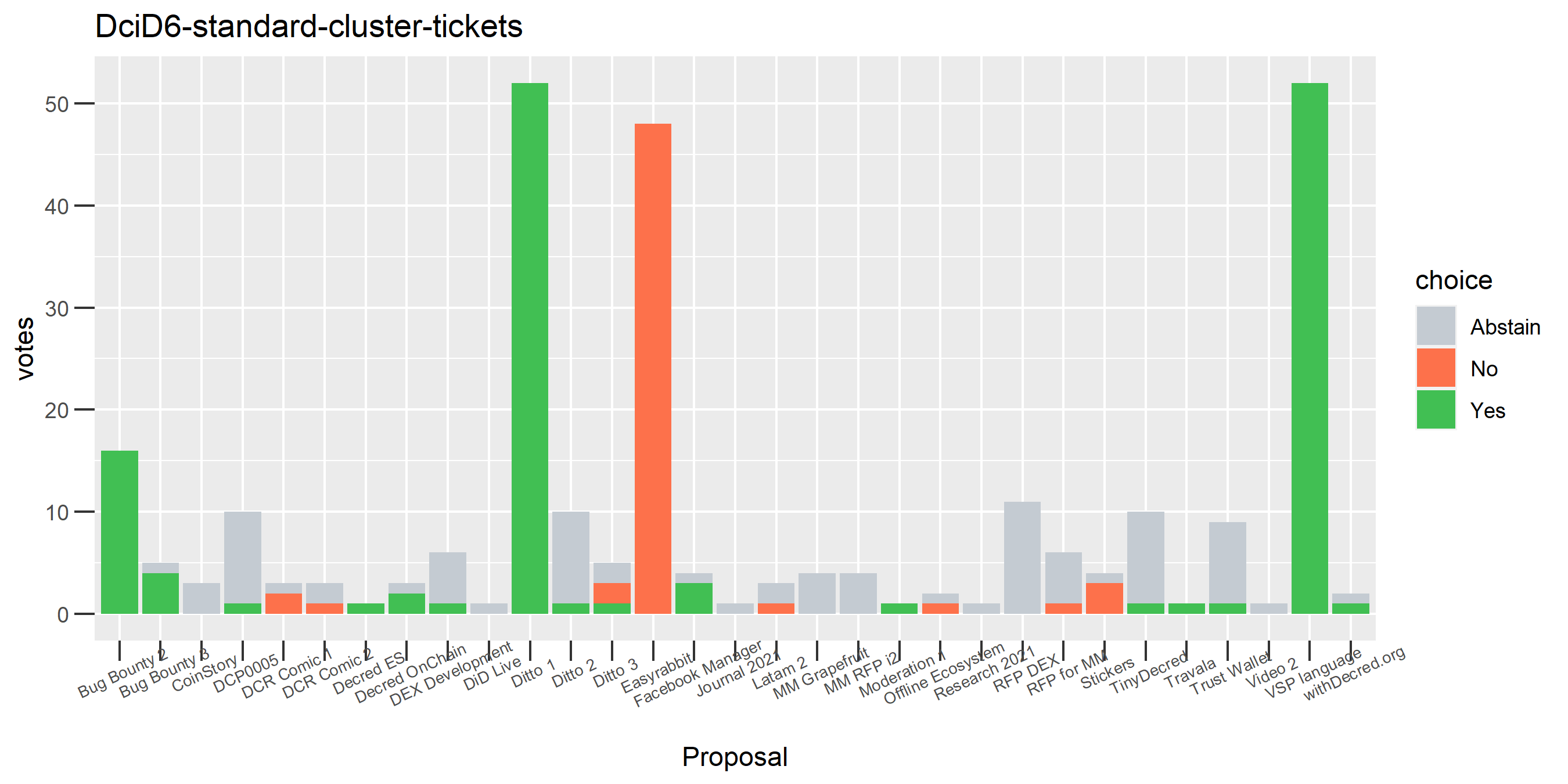
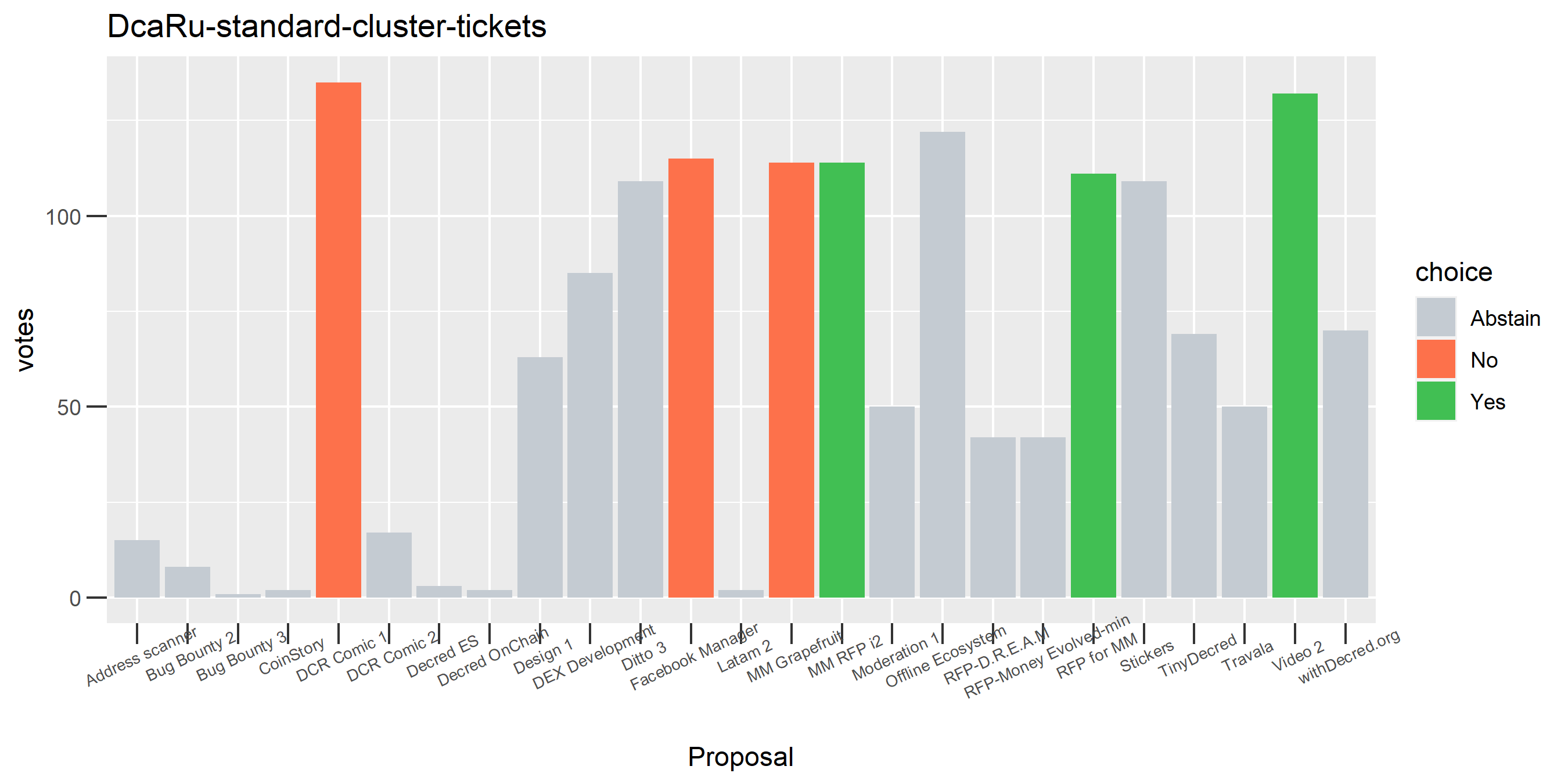
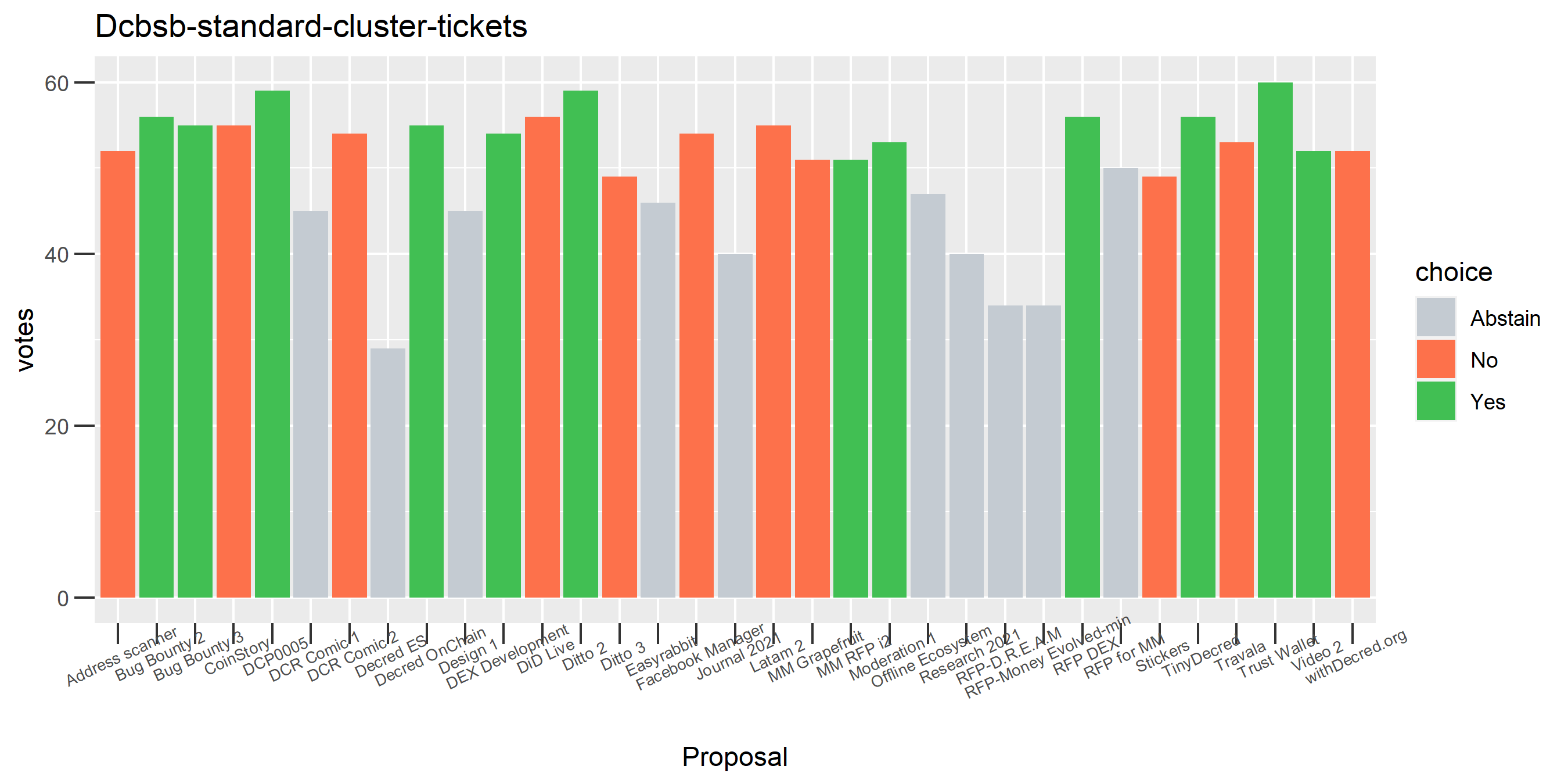
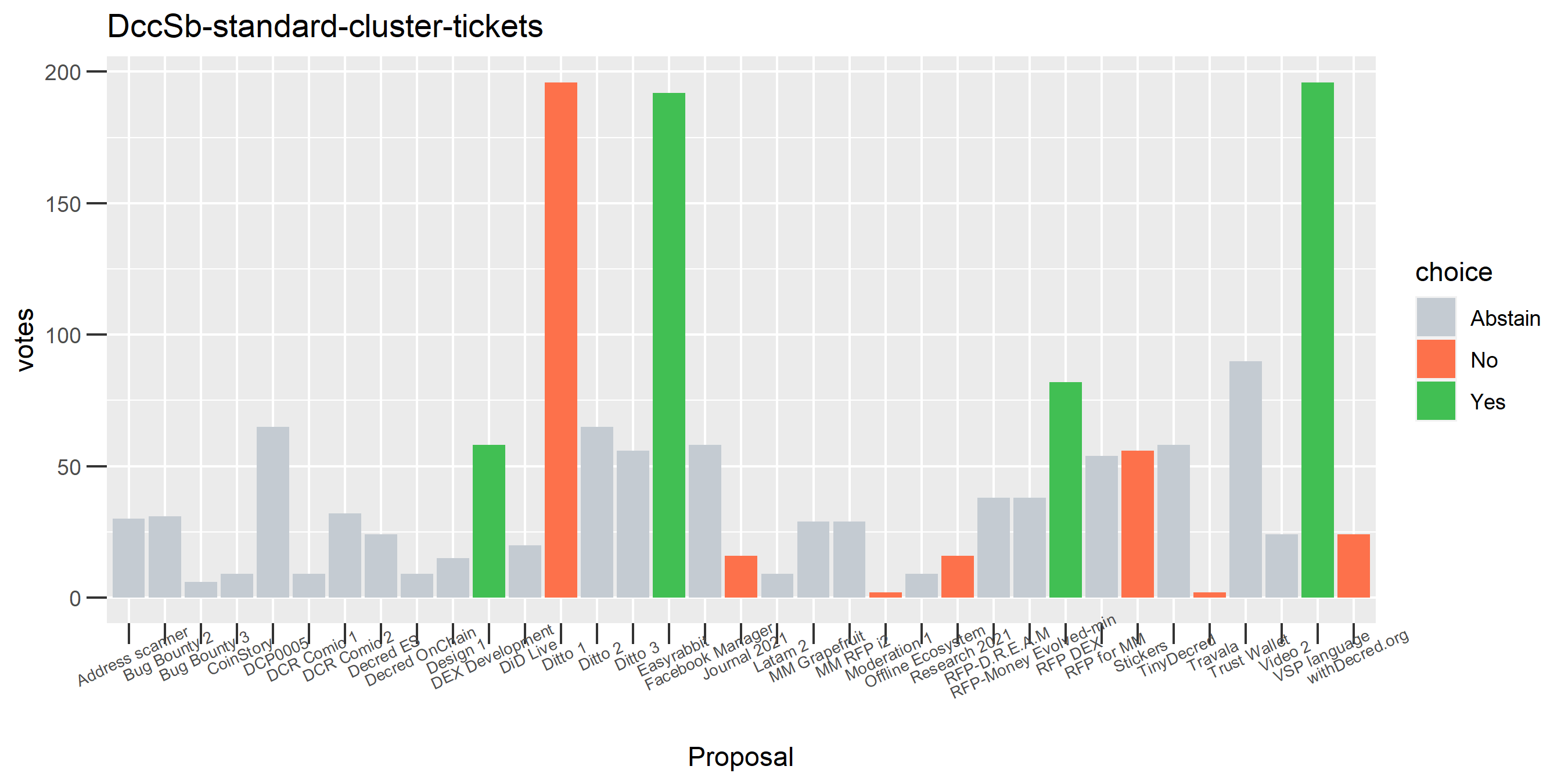
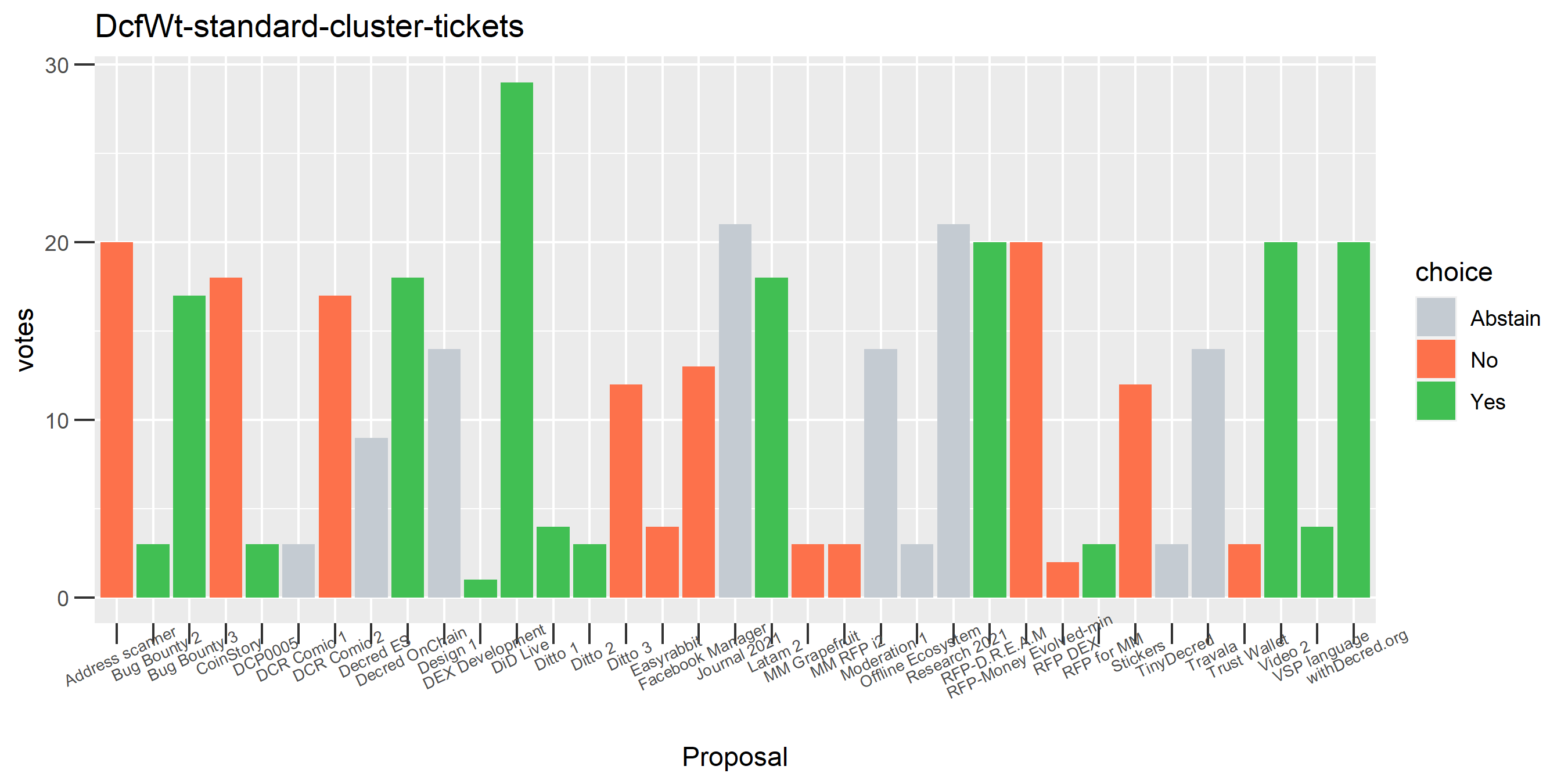
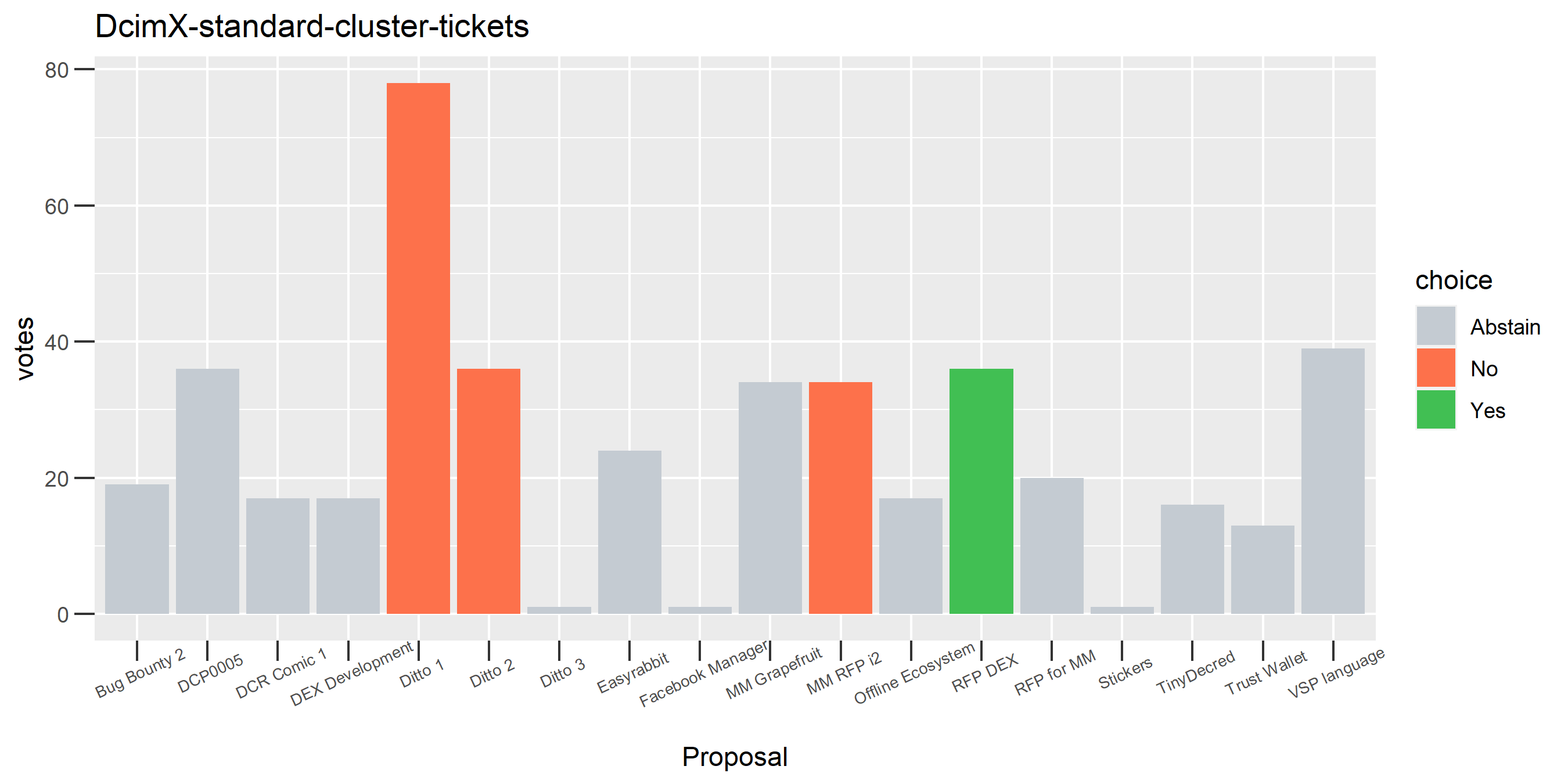
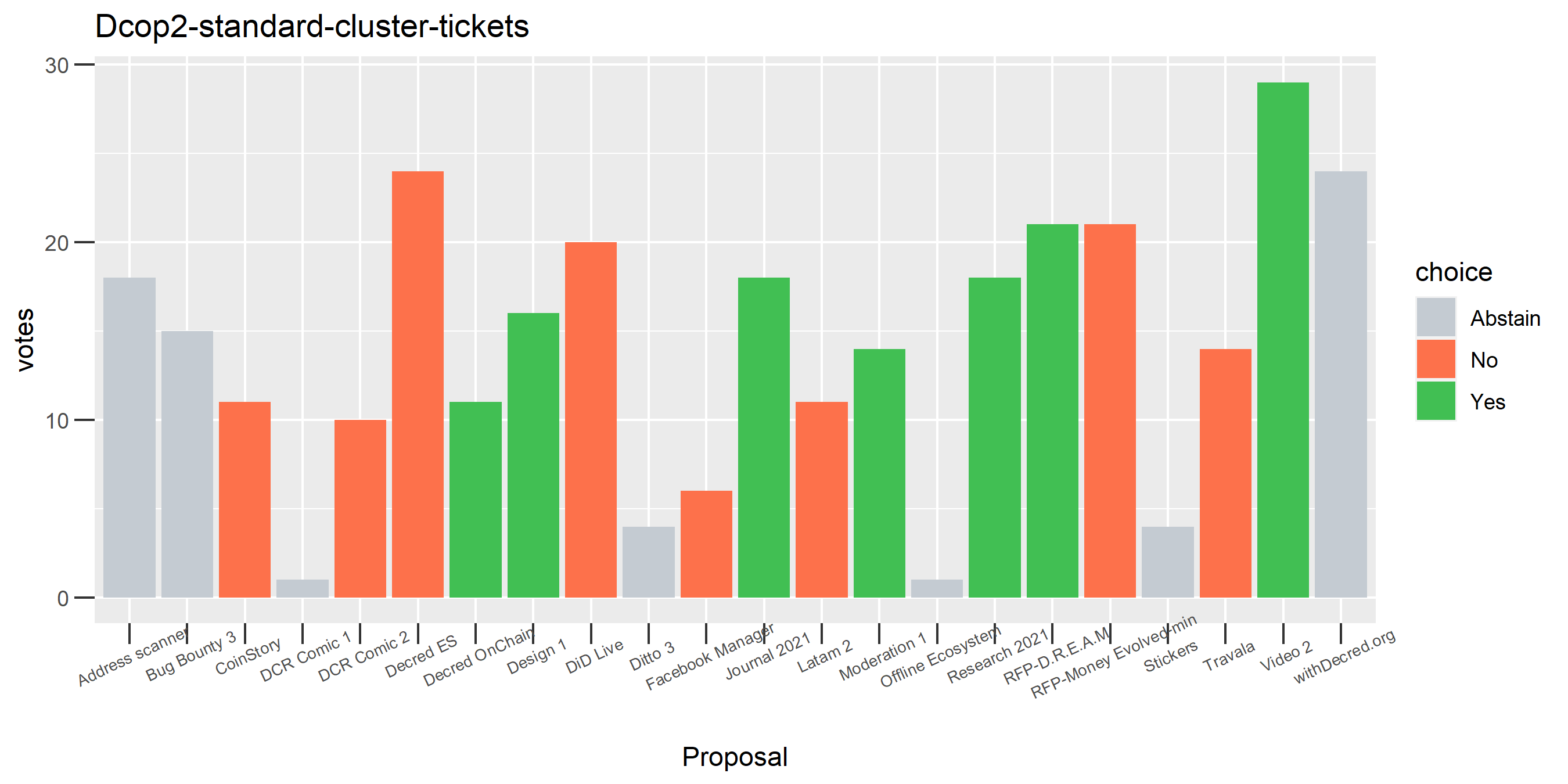
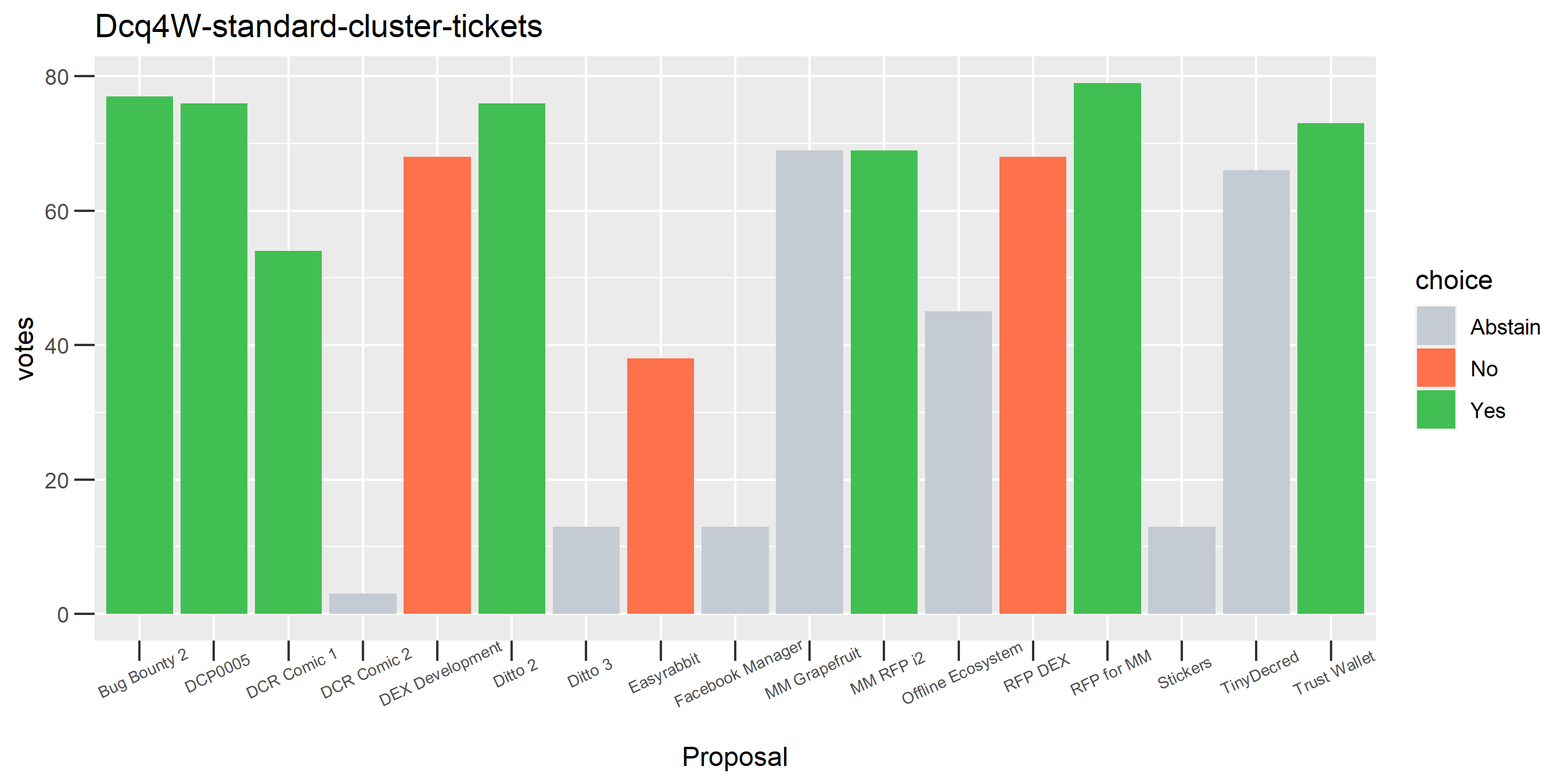
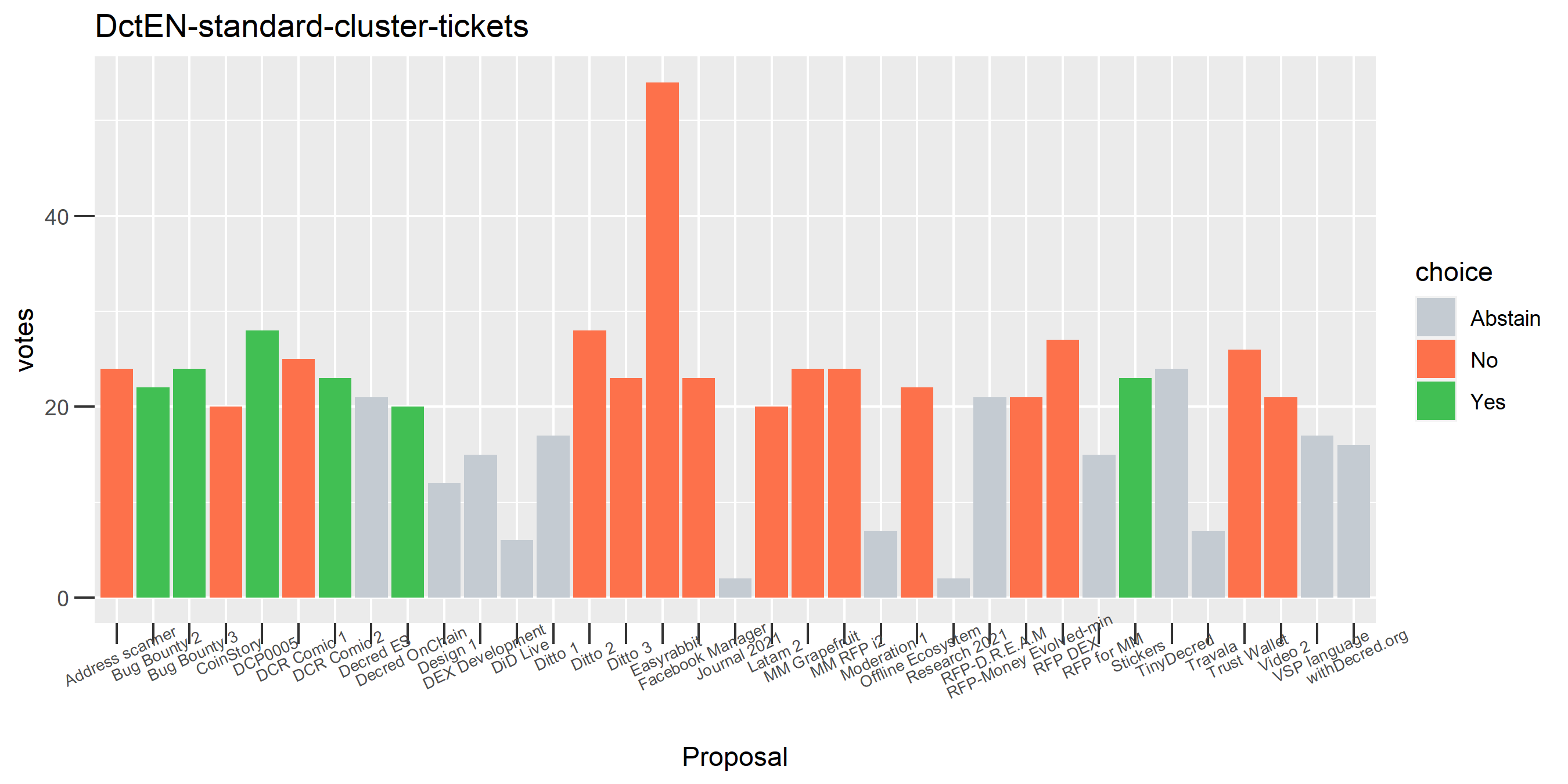
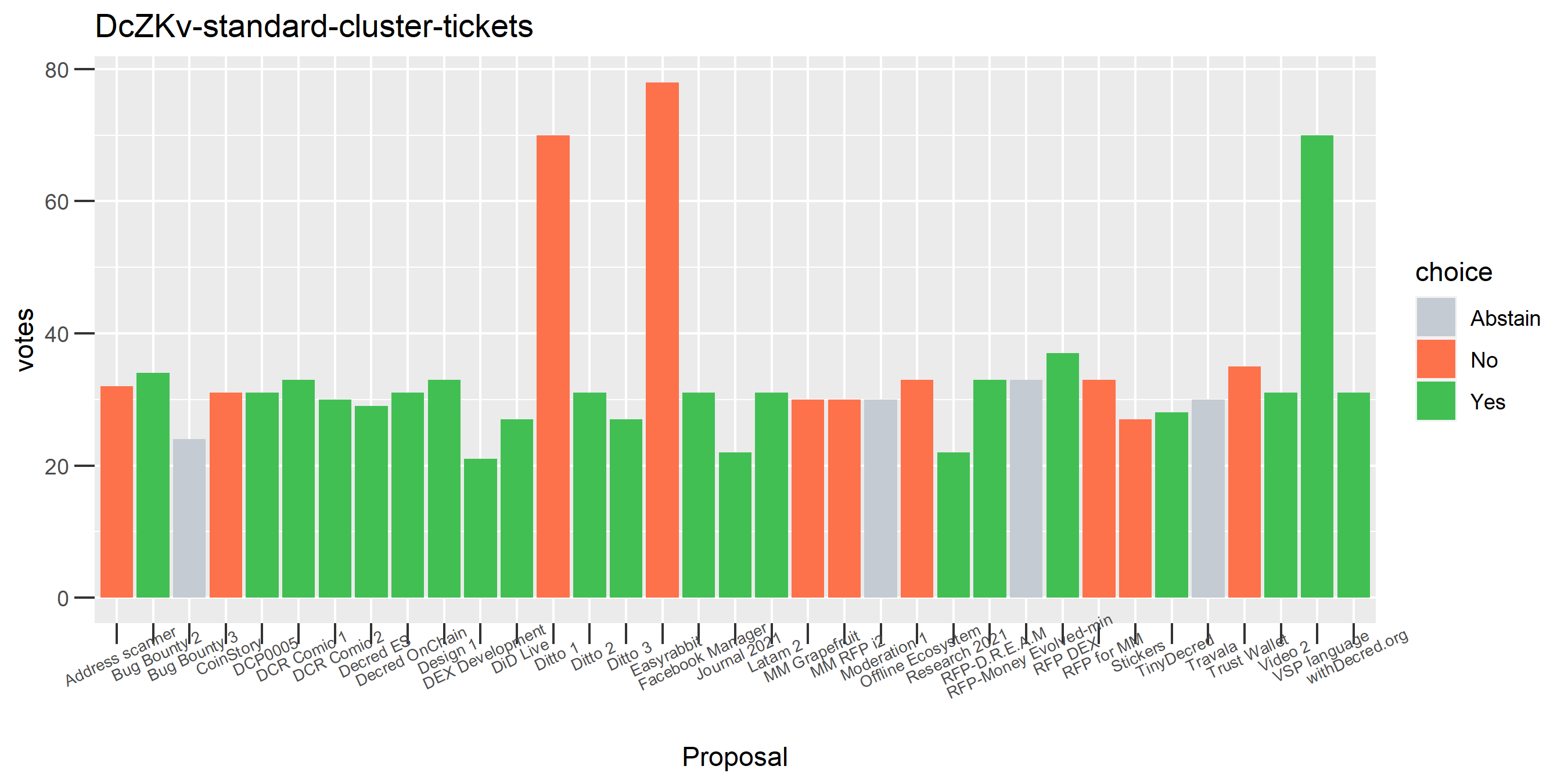
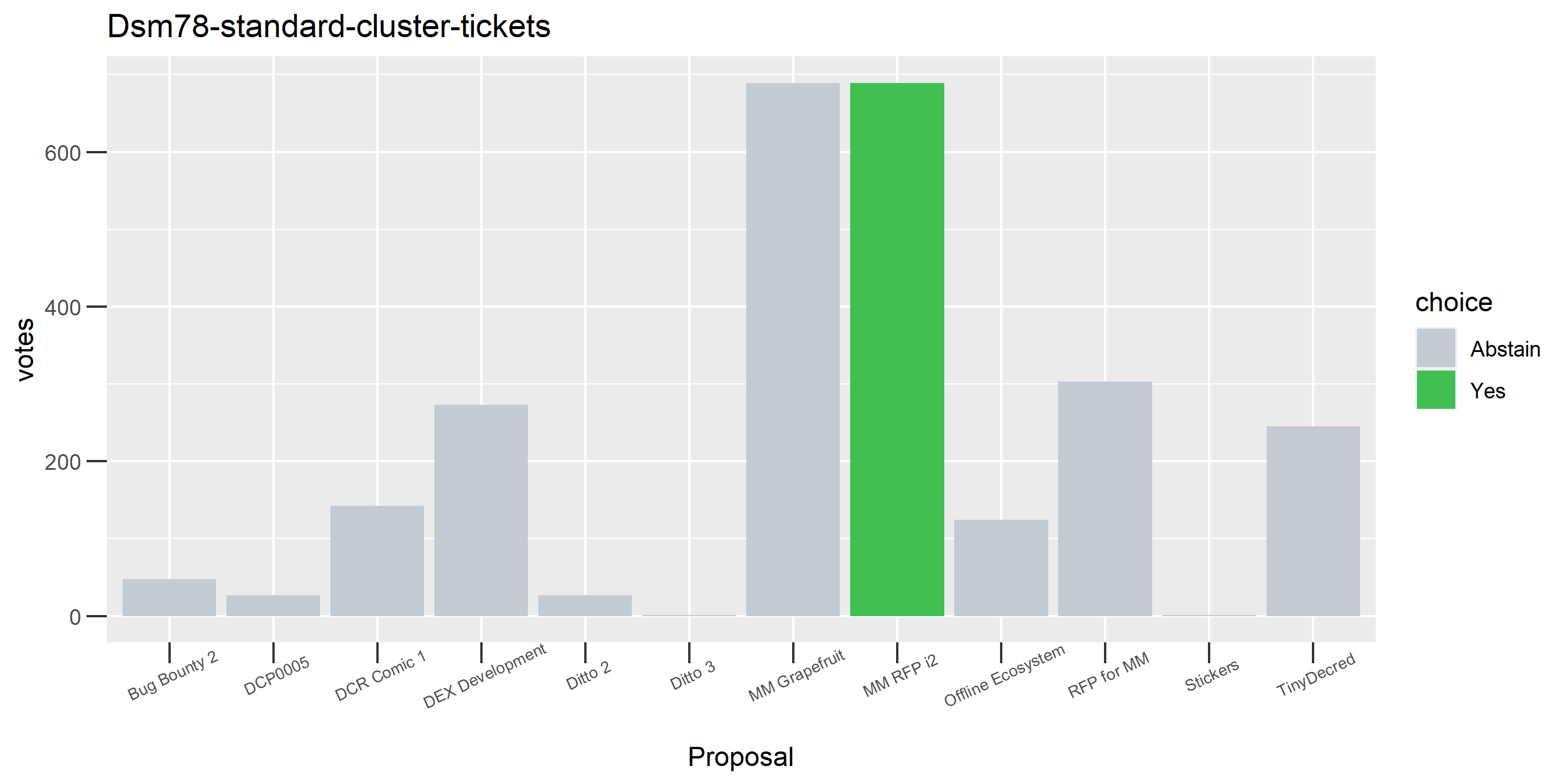
This cluster looks more suspect that something might be going wrong, because it has some contradictory votes and also doesn’t use all of its available votes regularly.
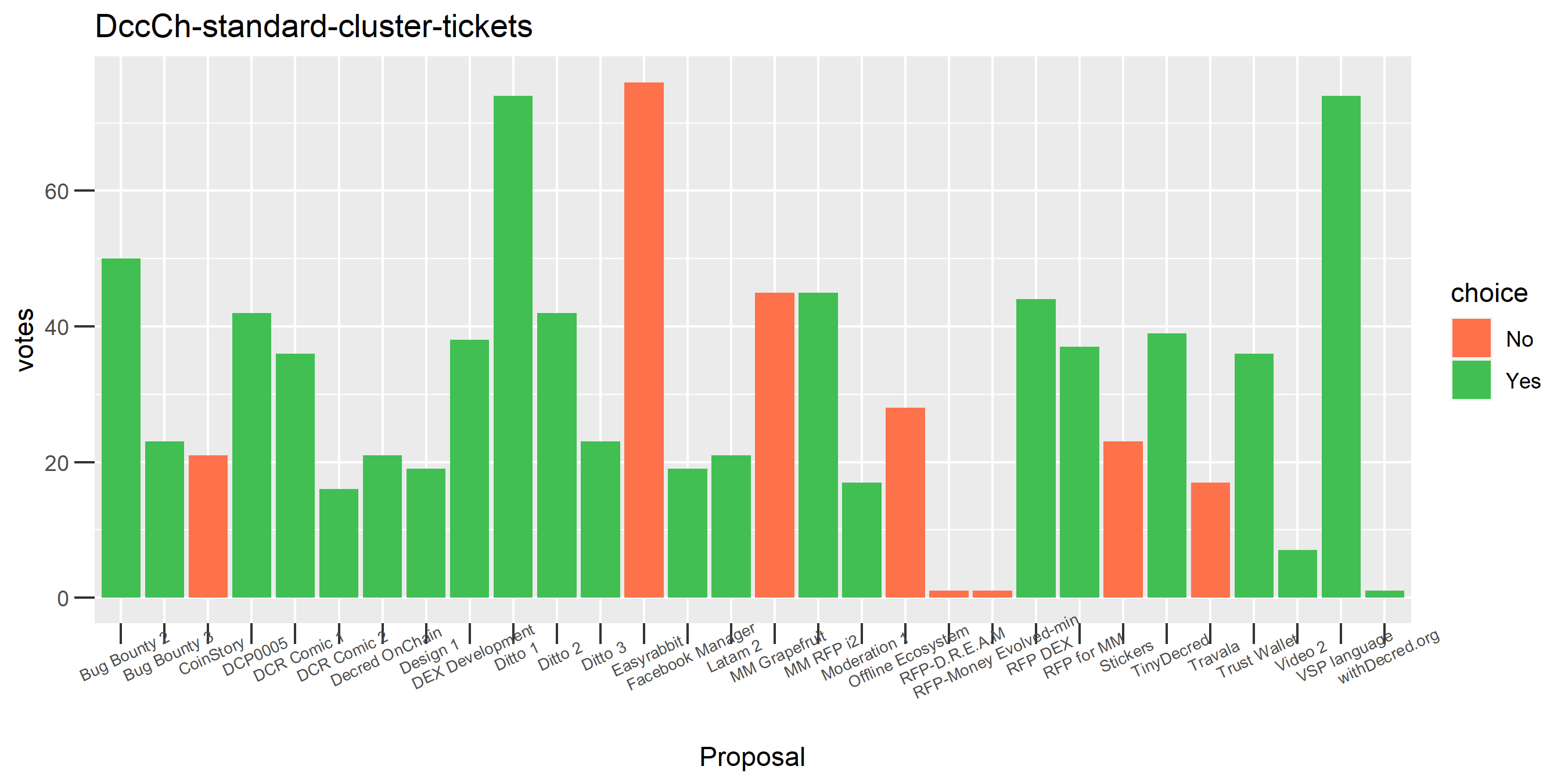
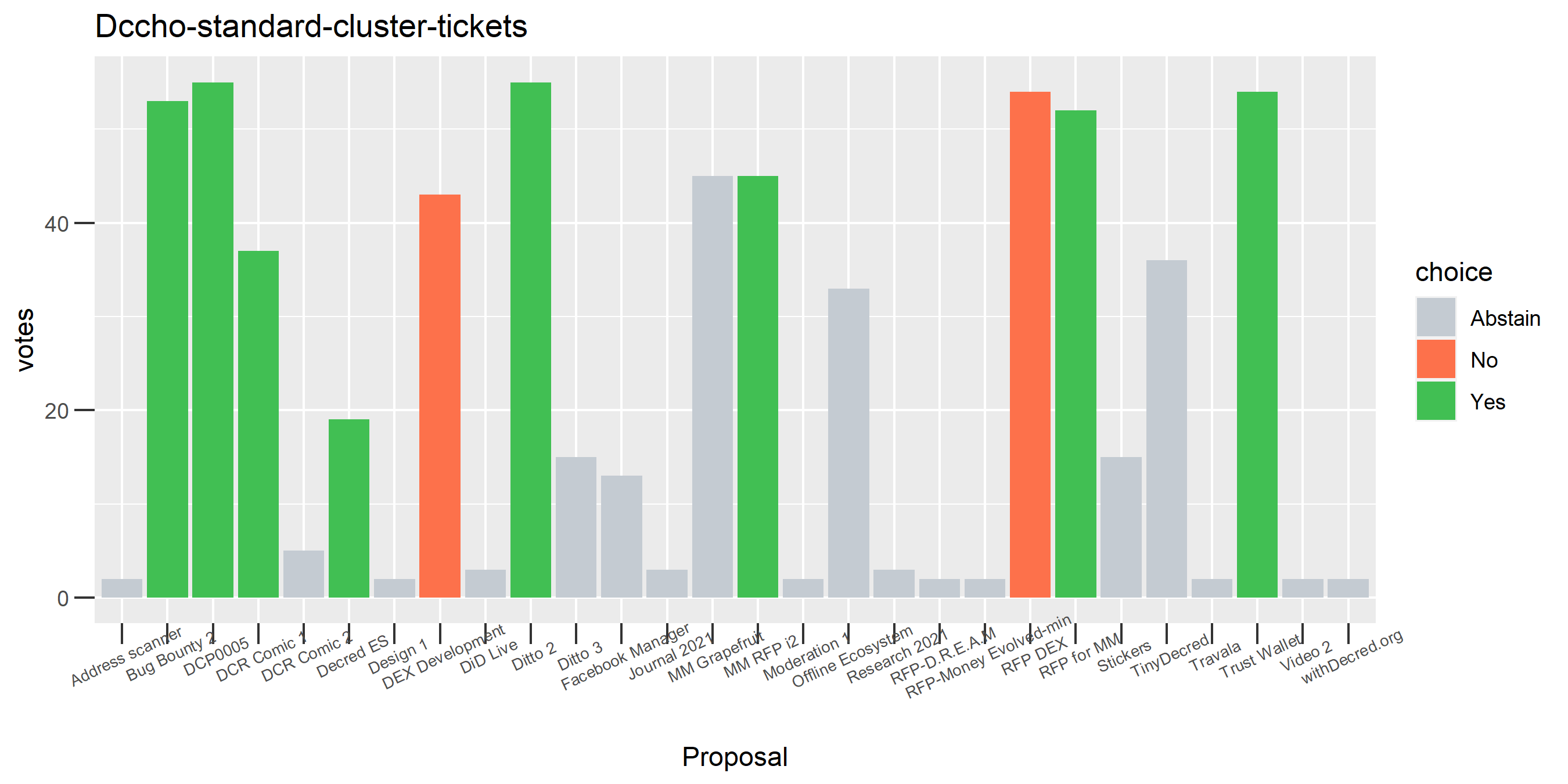
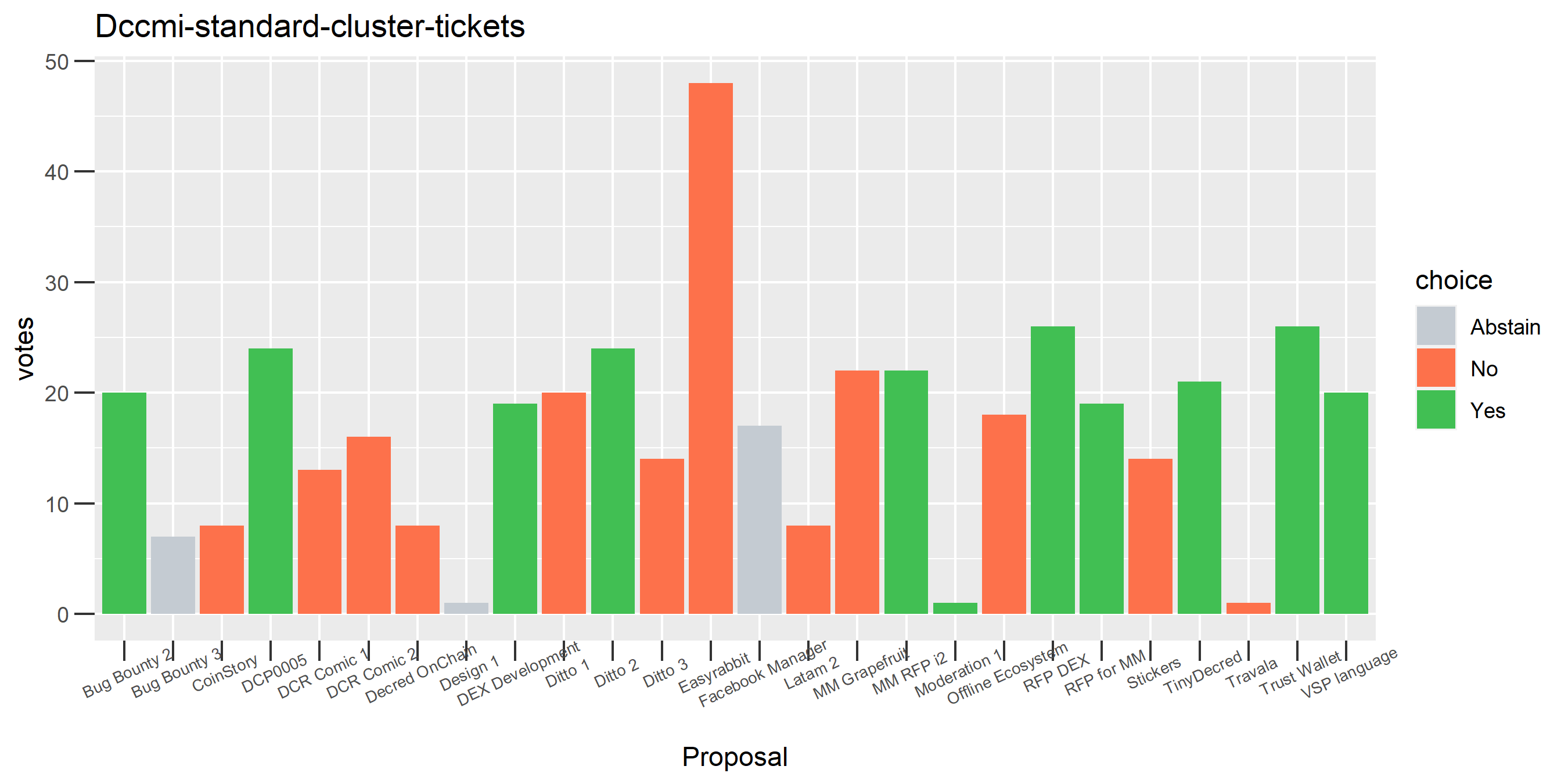
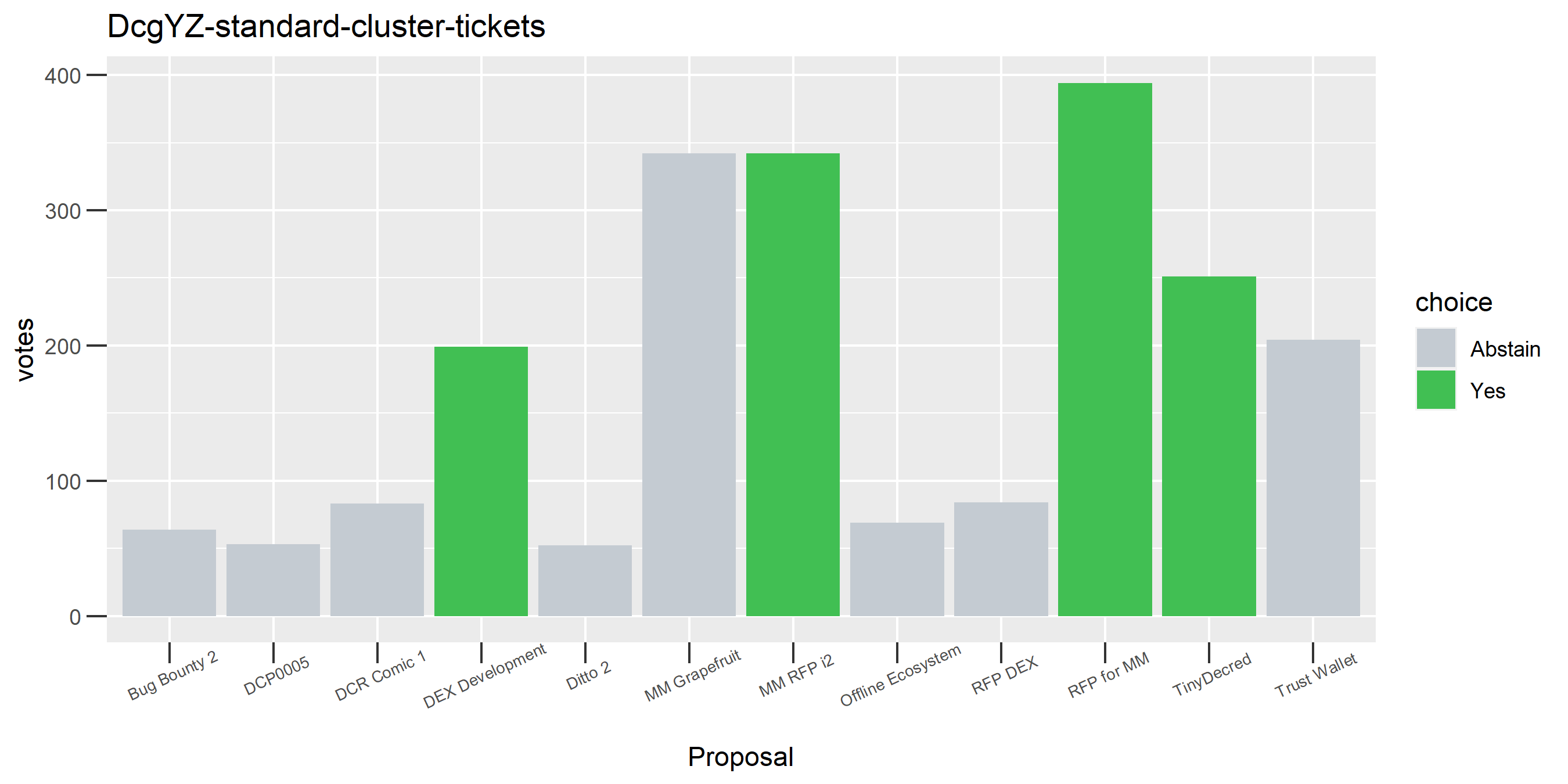
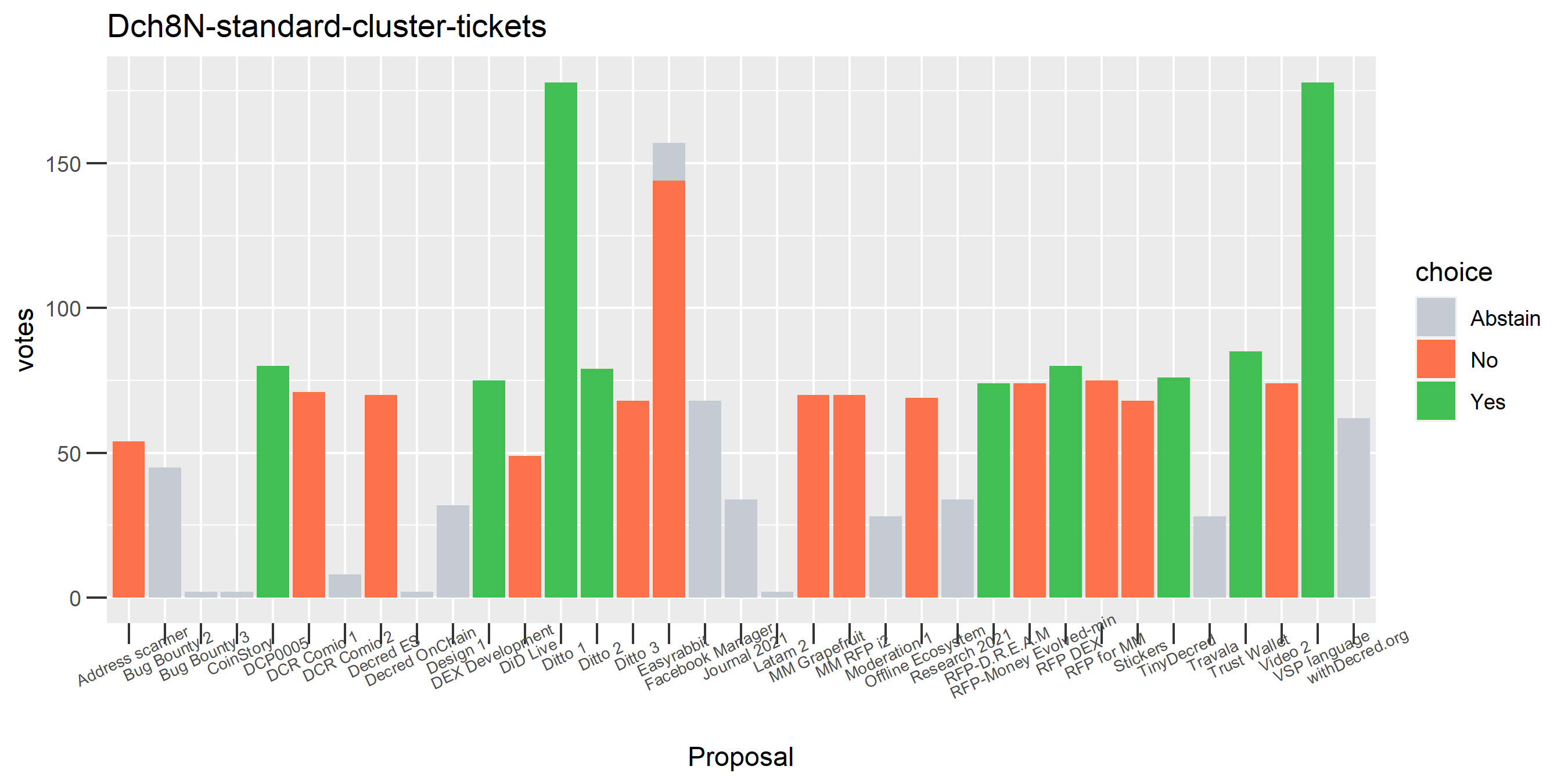
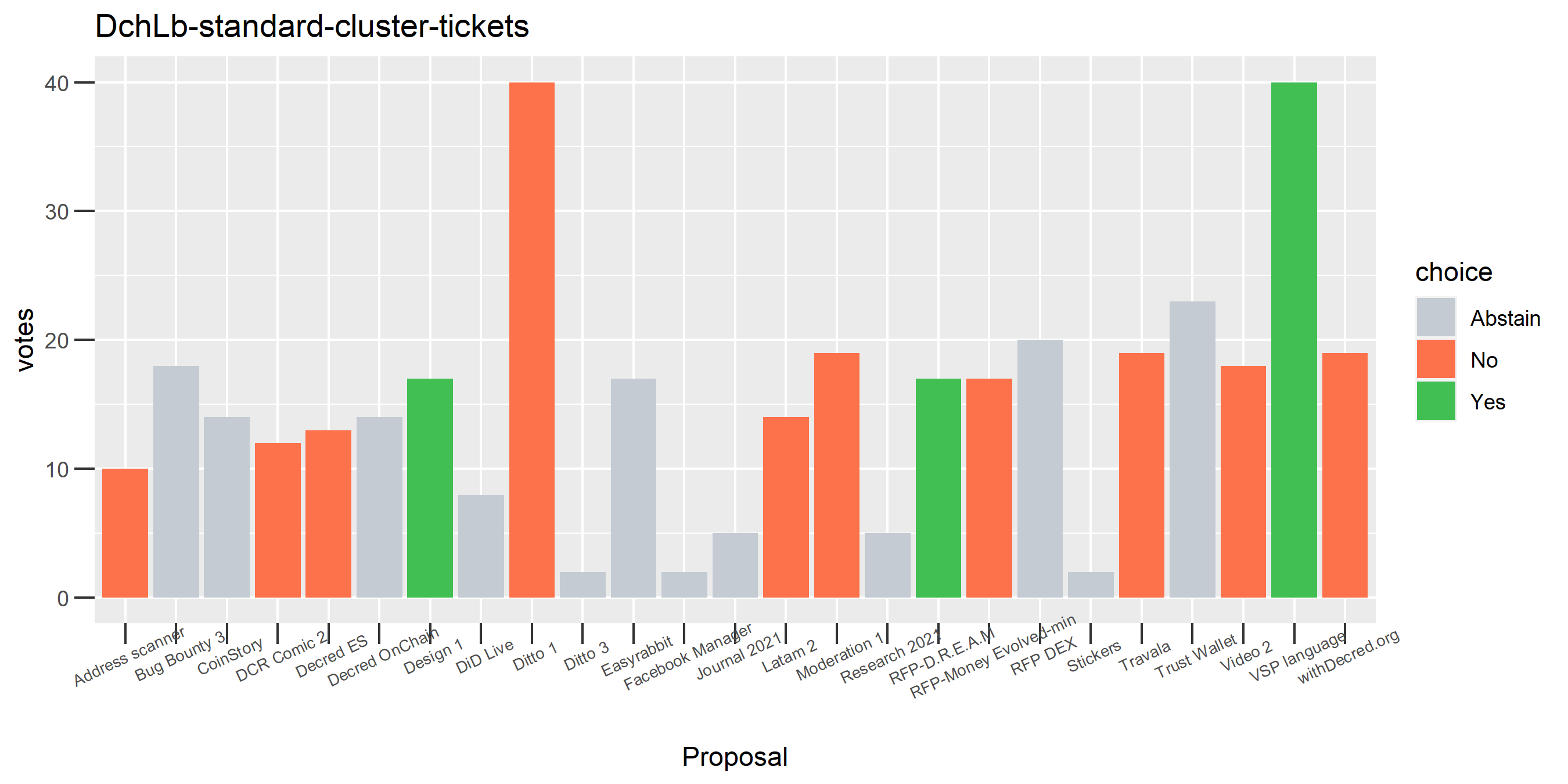
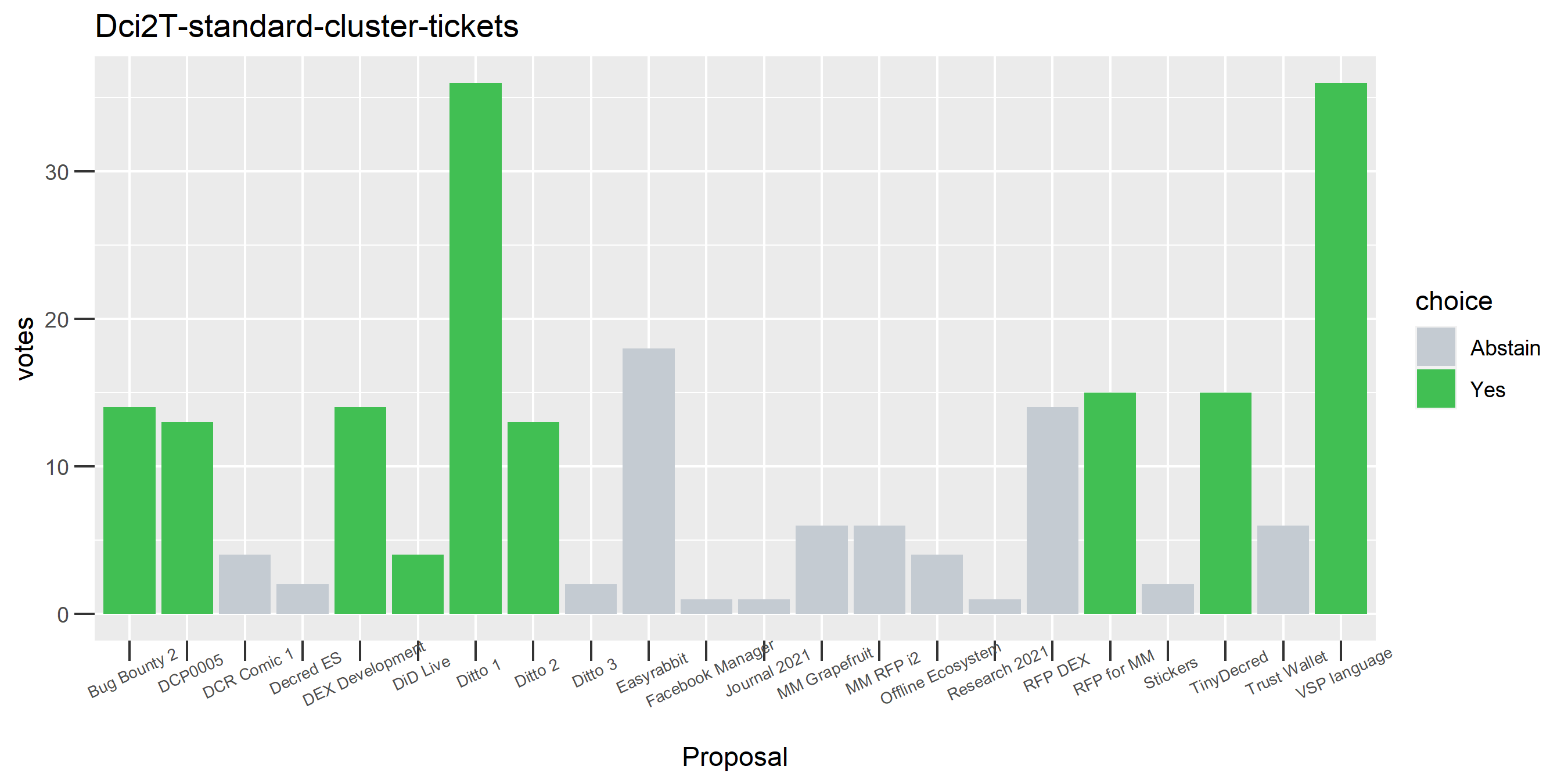
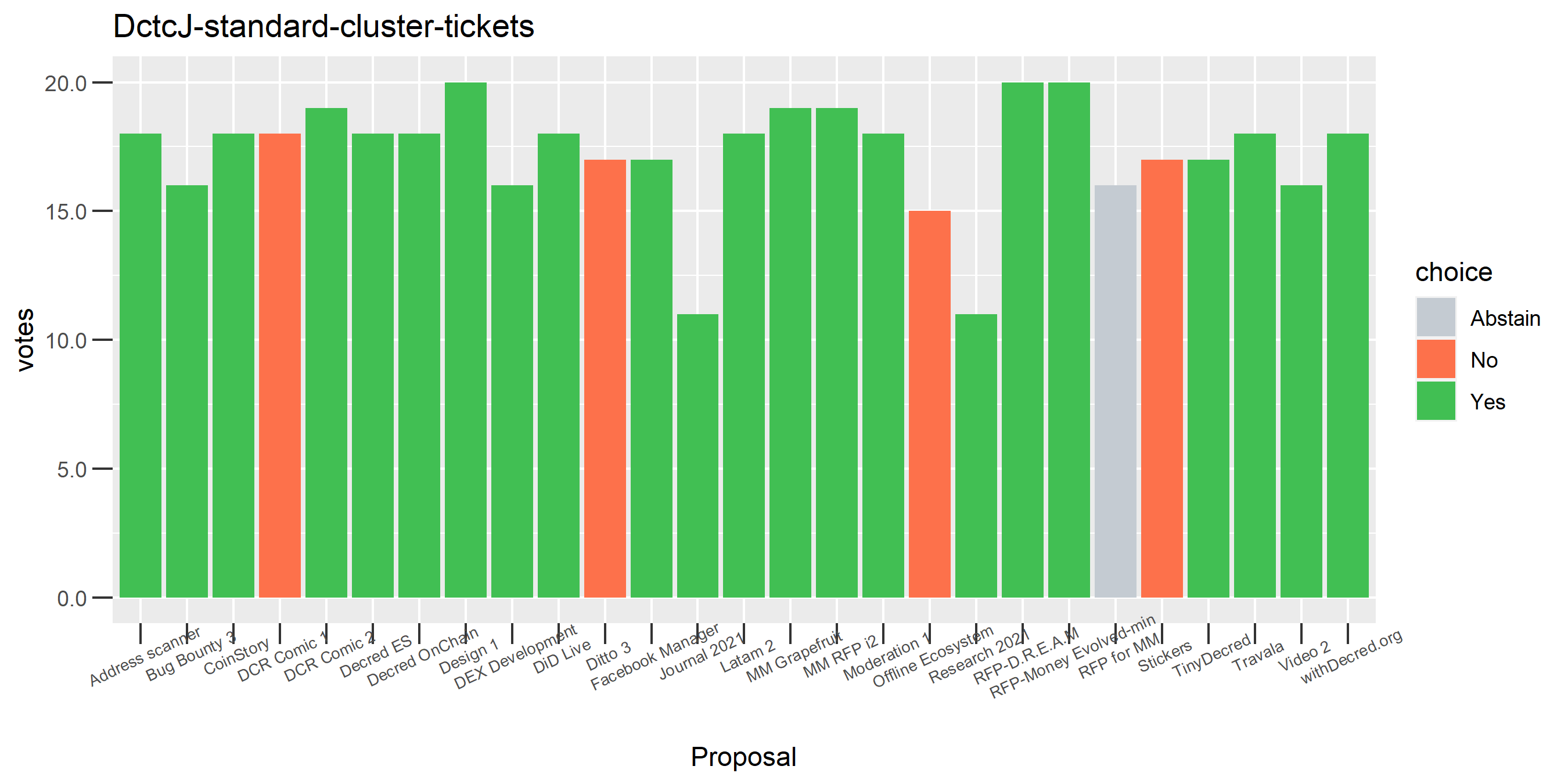
Of the 1,000 clusters with the most addresses, 467 had at least some Politeia proposal eligibility. After inspecting all of those voting charts, only the 6 identified above show any sign of contradictory voting, and in most cases it seems likely to reflect genuine user behavior. The Dsogb cluster remains as a known issue, but I am confident now that most of the voting addresses have been properly assigned to clusters following the heuristics described above.
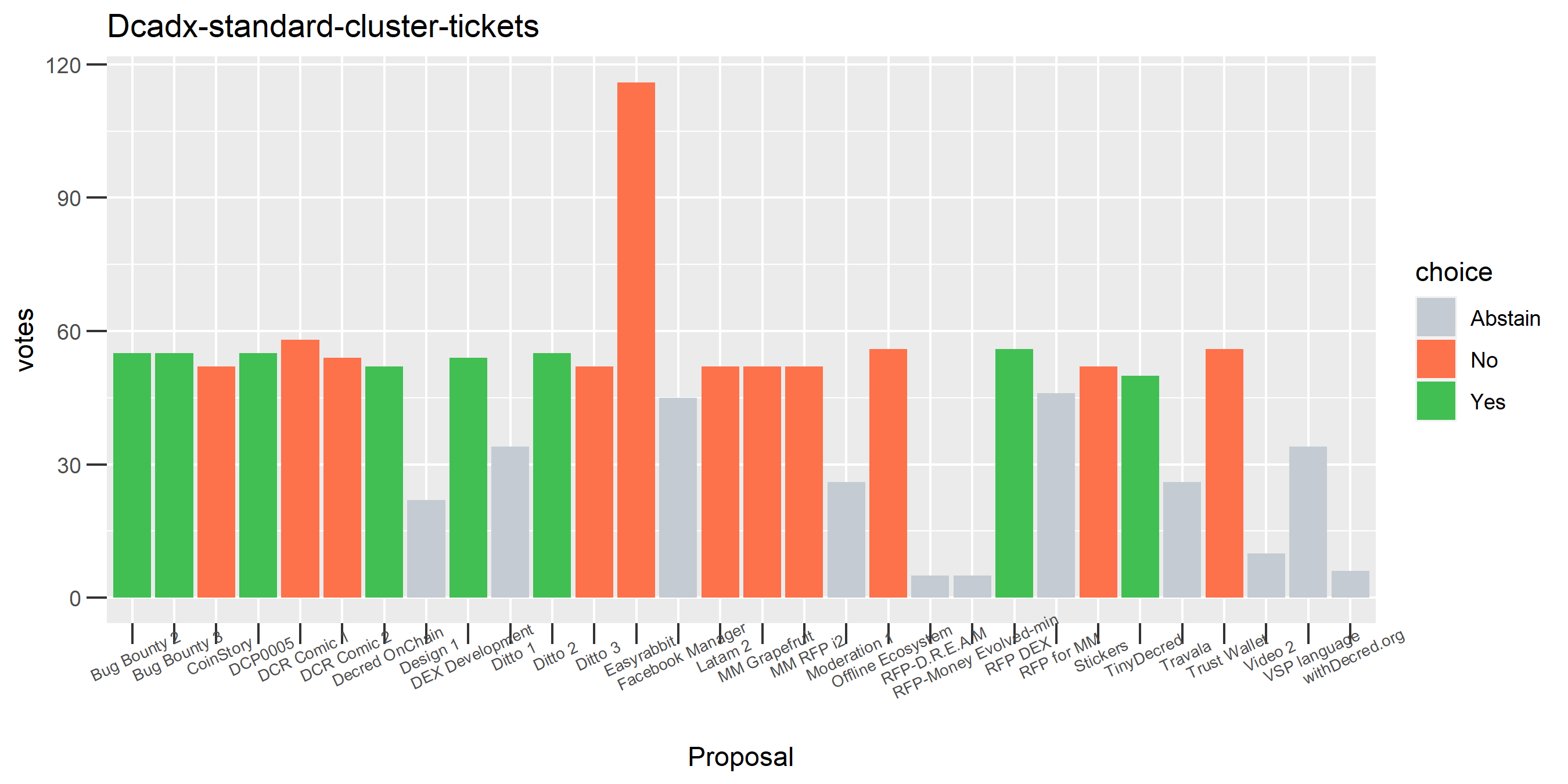
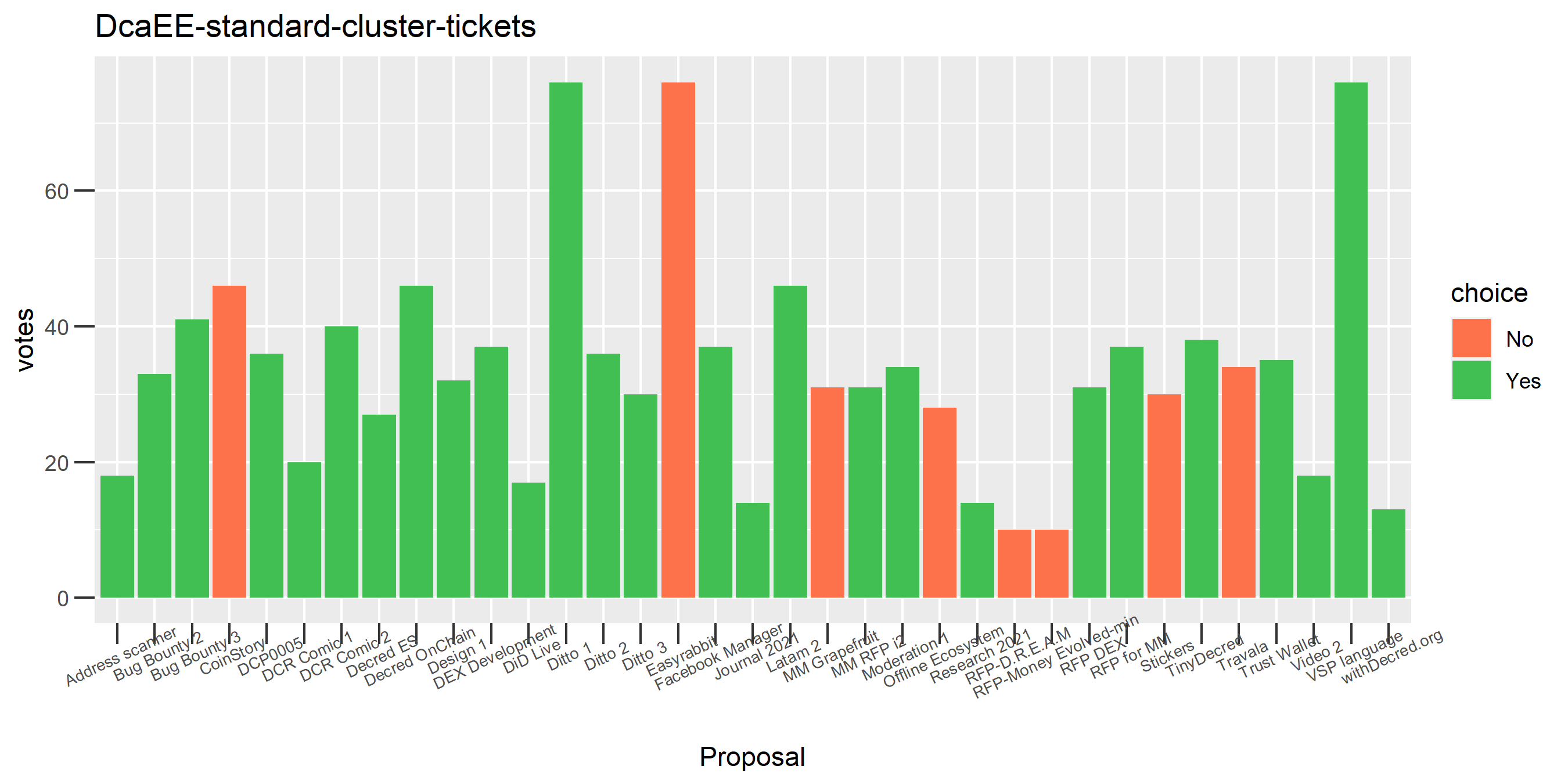
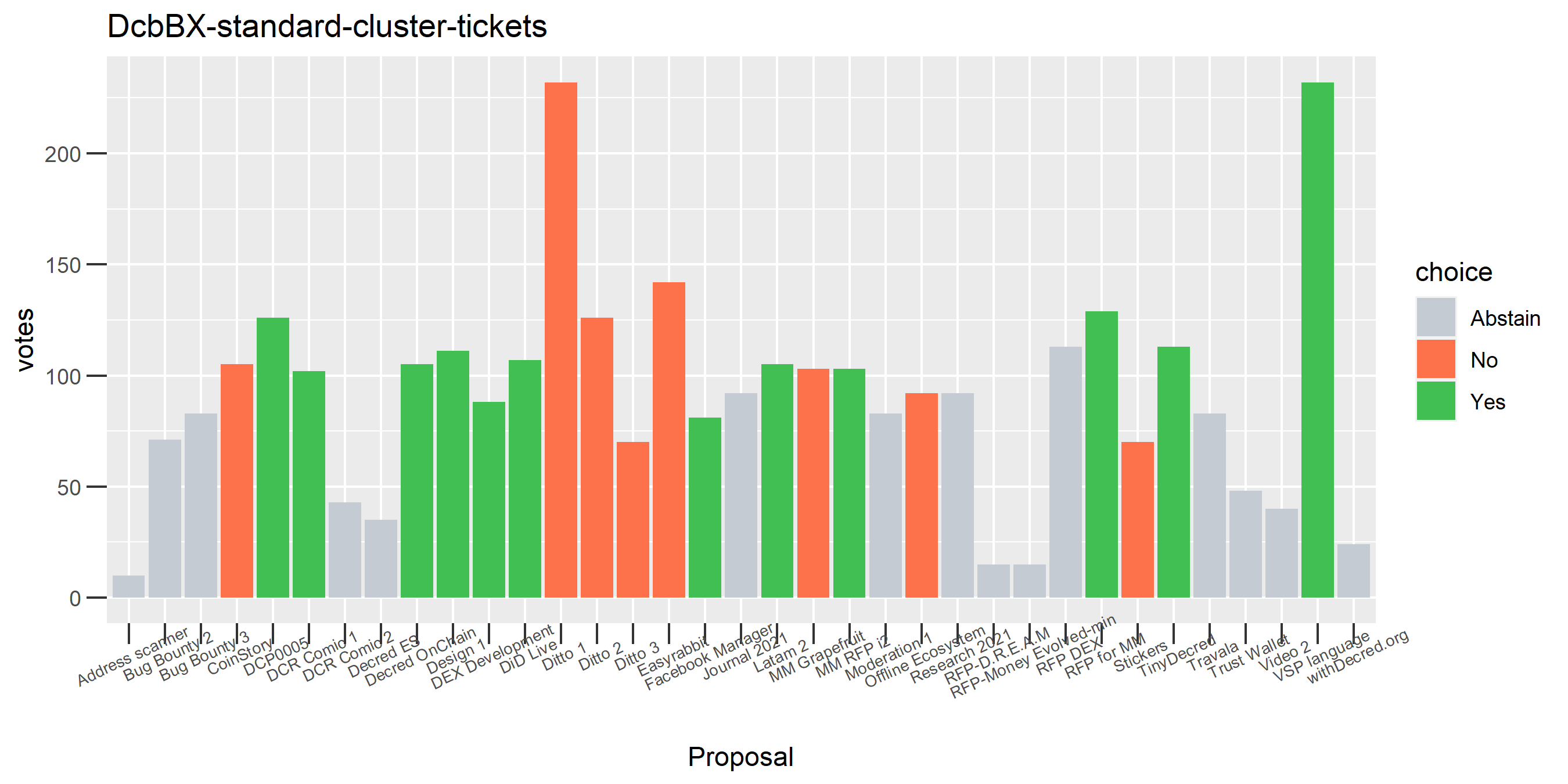
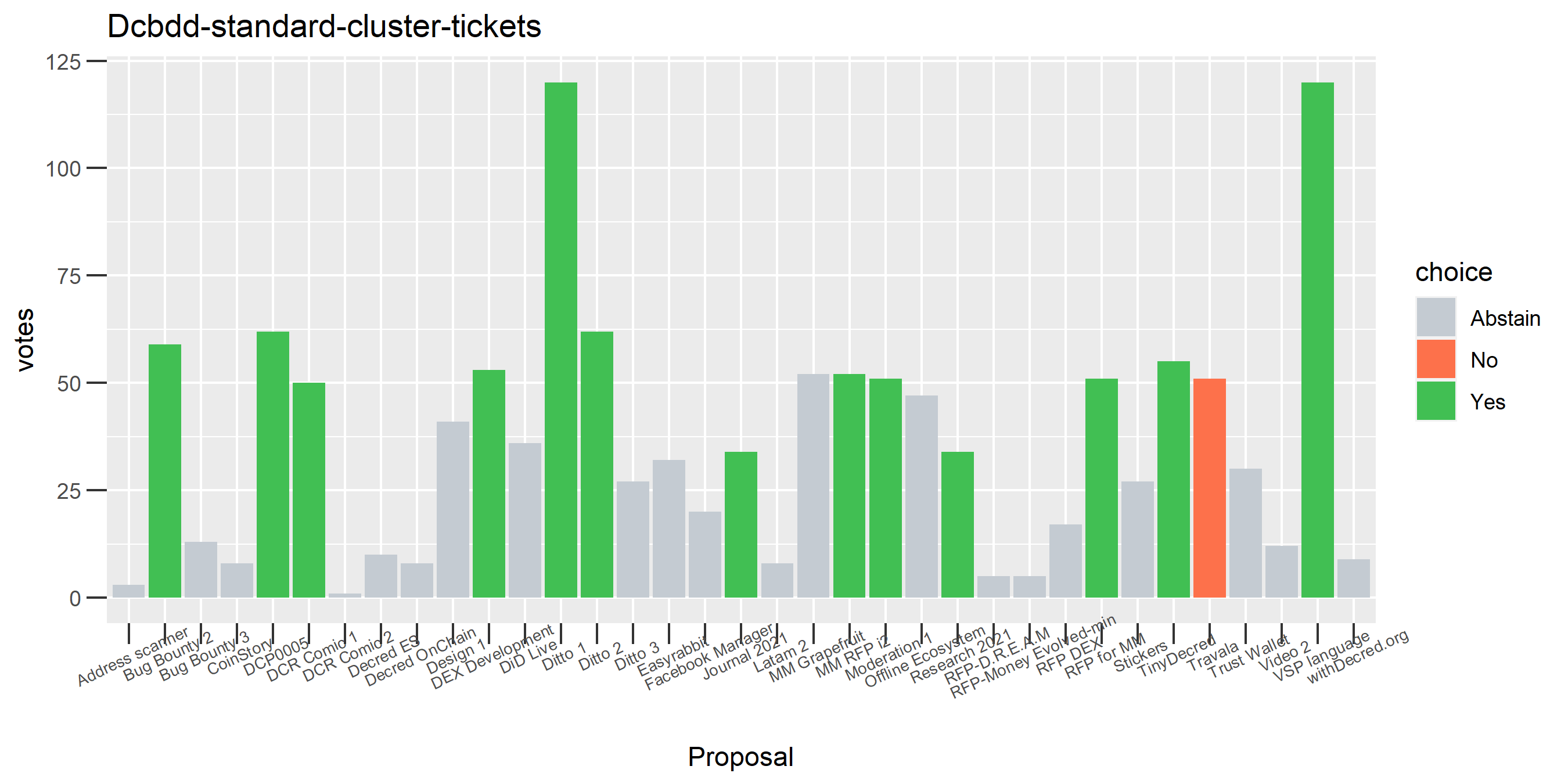
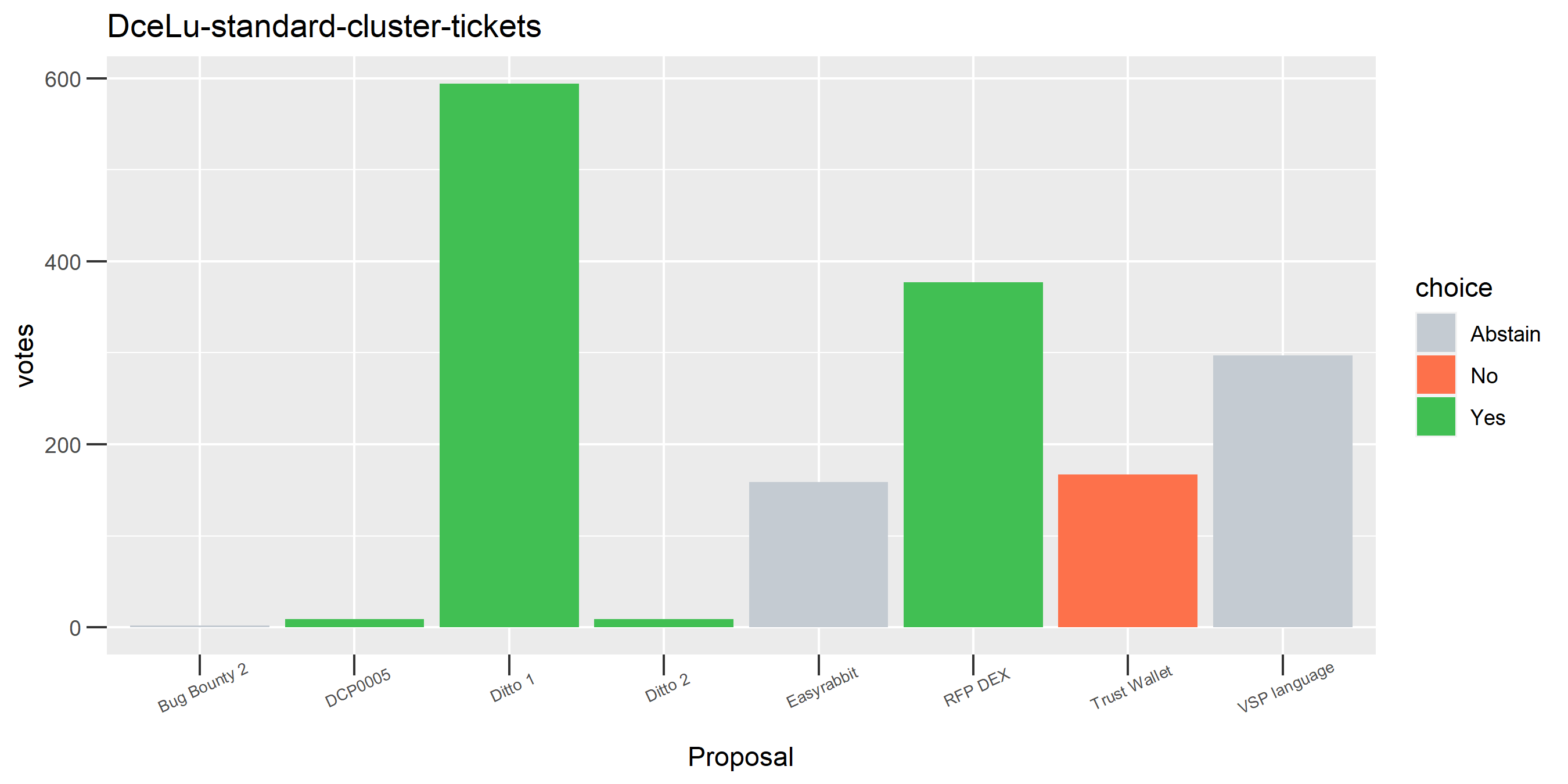
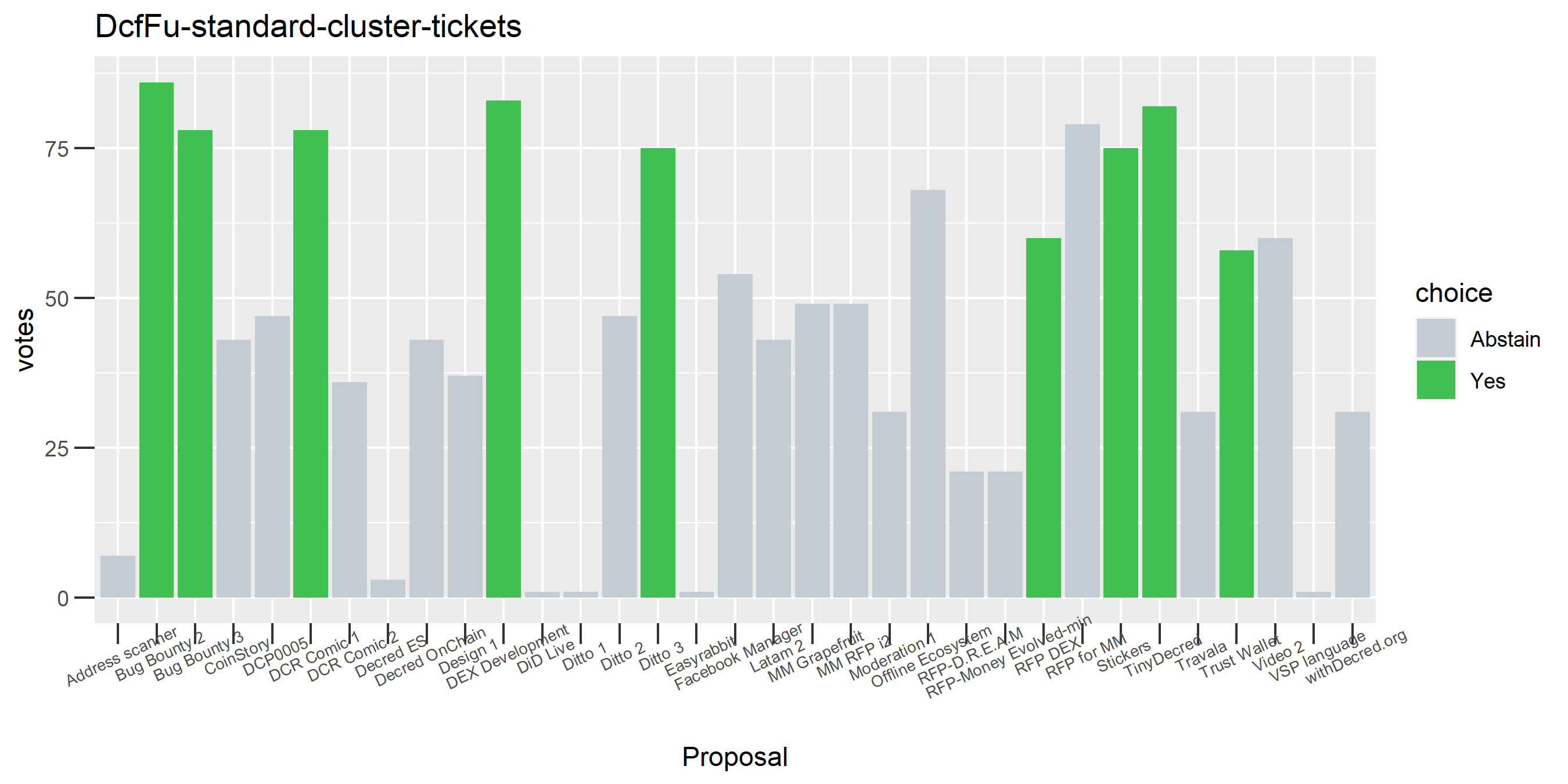
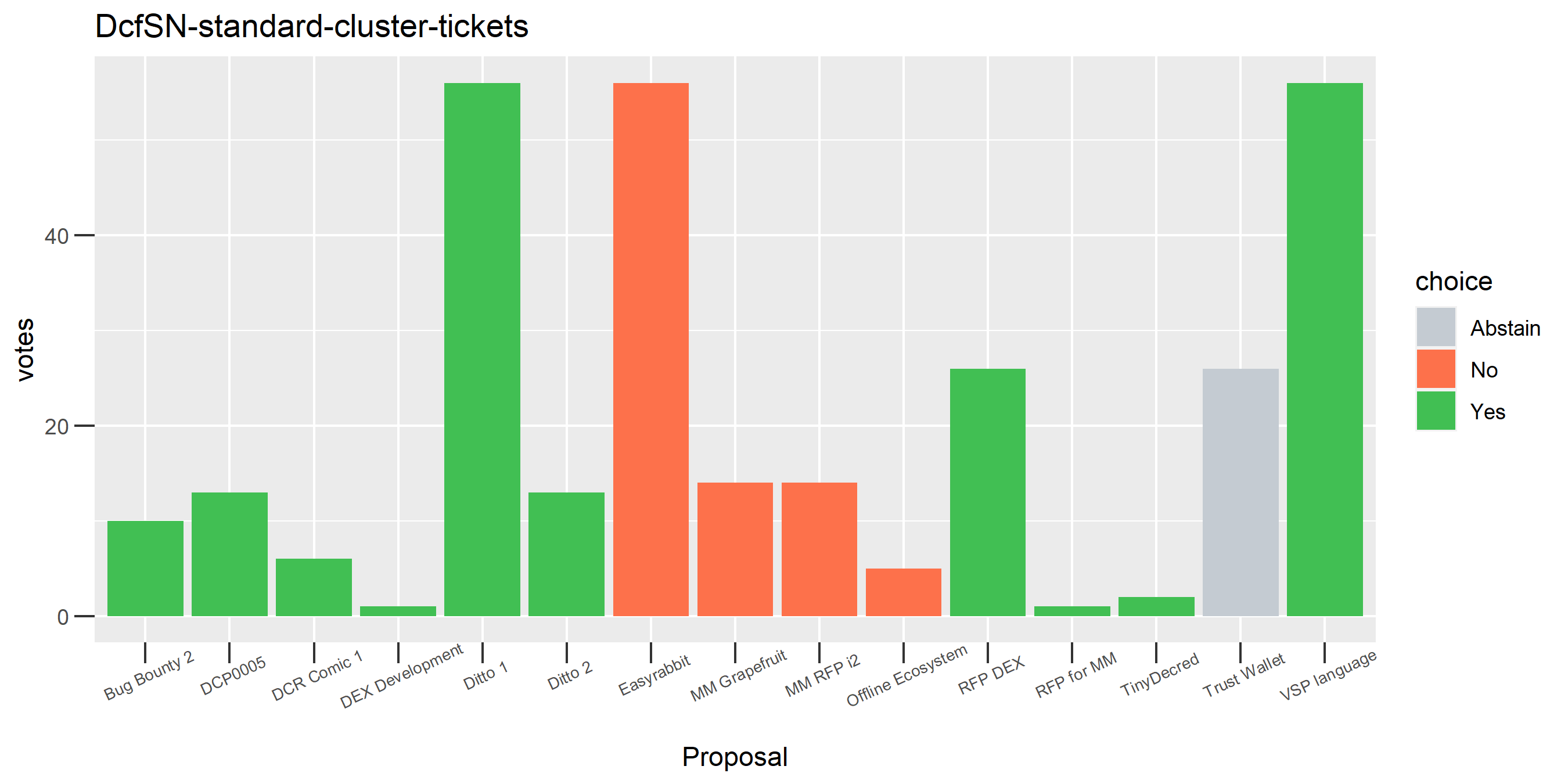
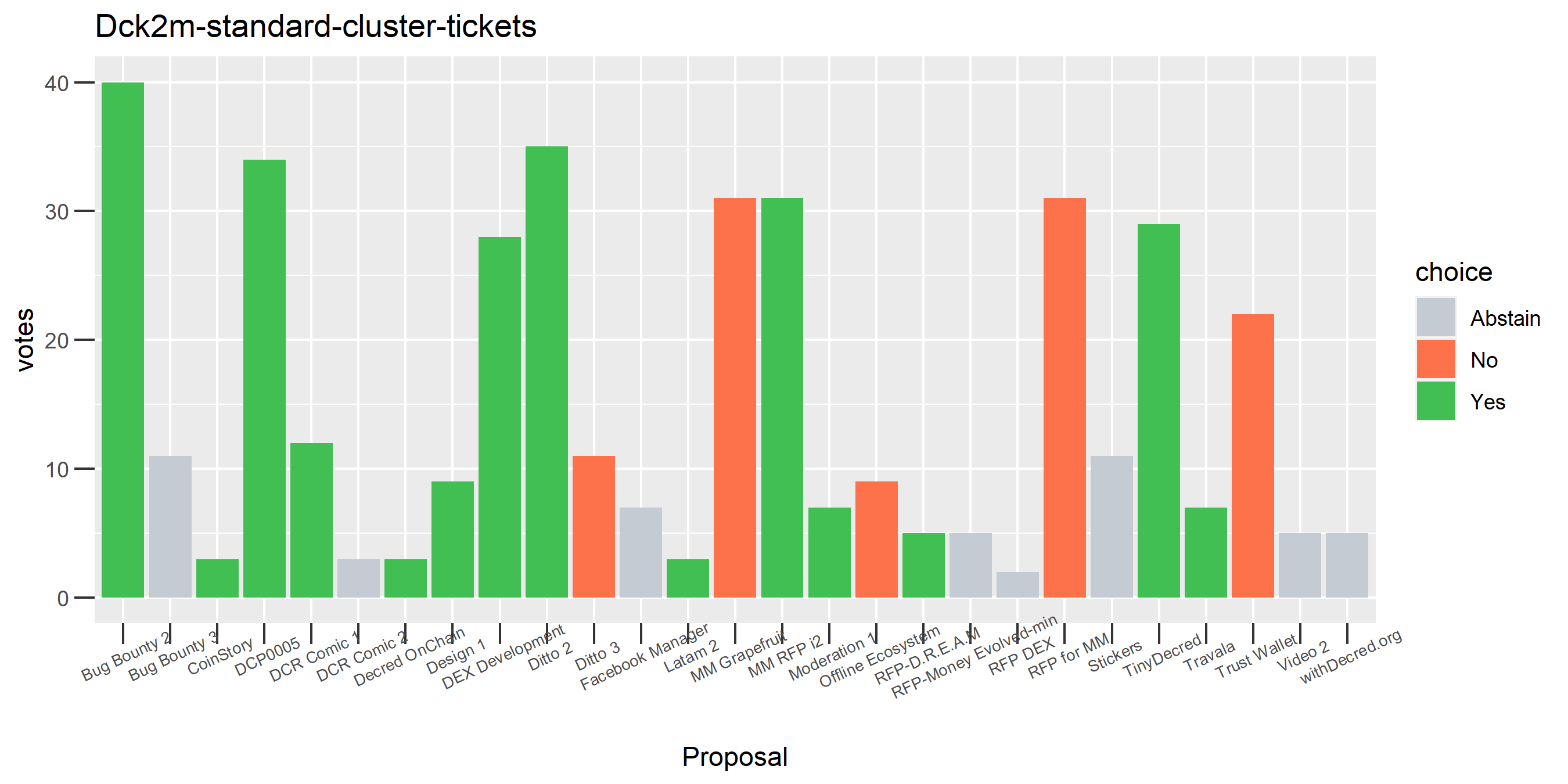
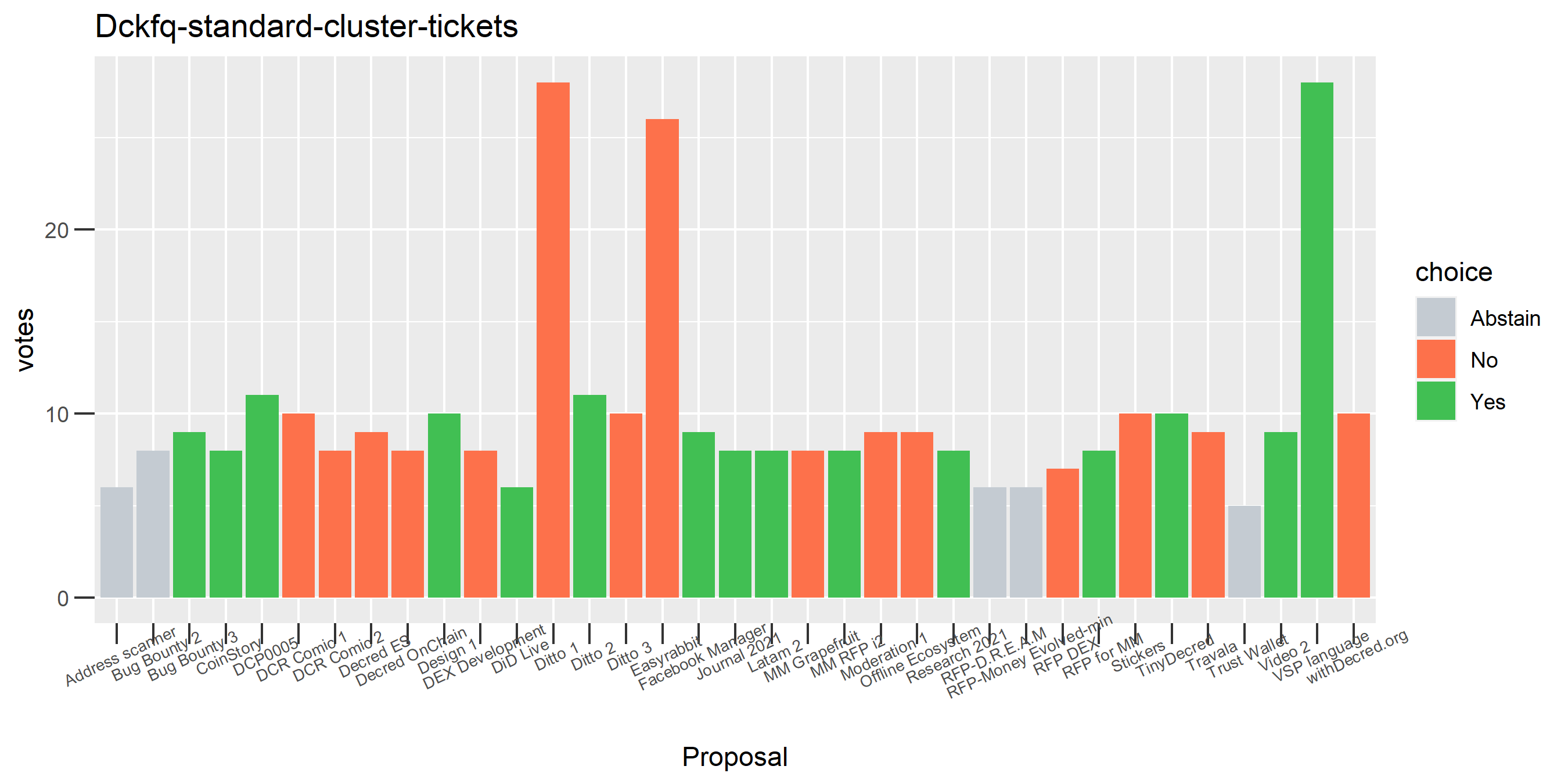
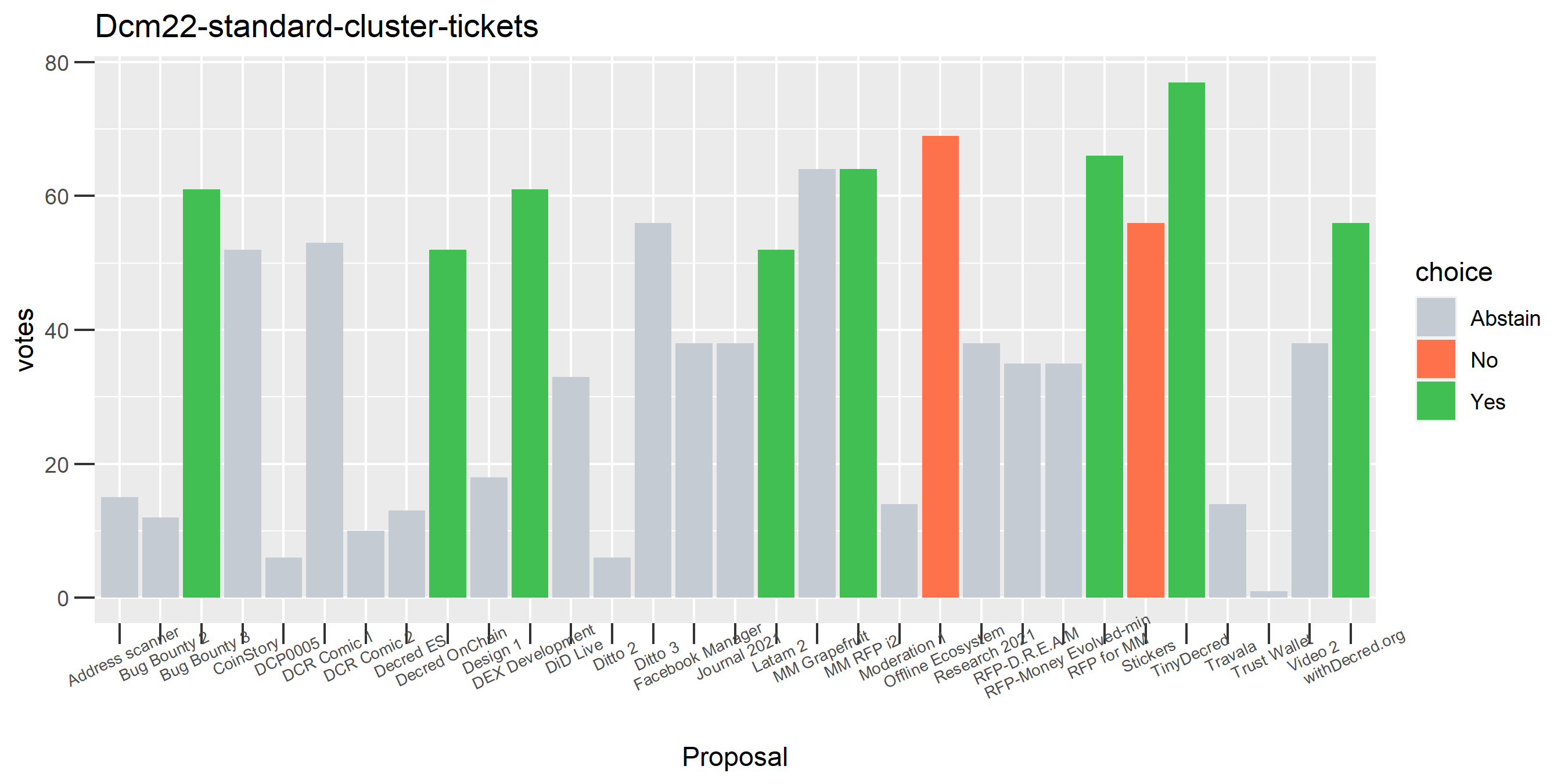
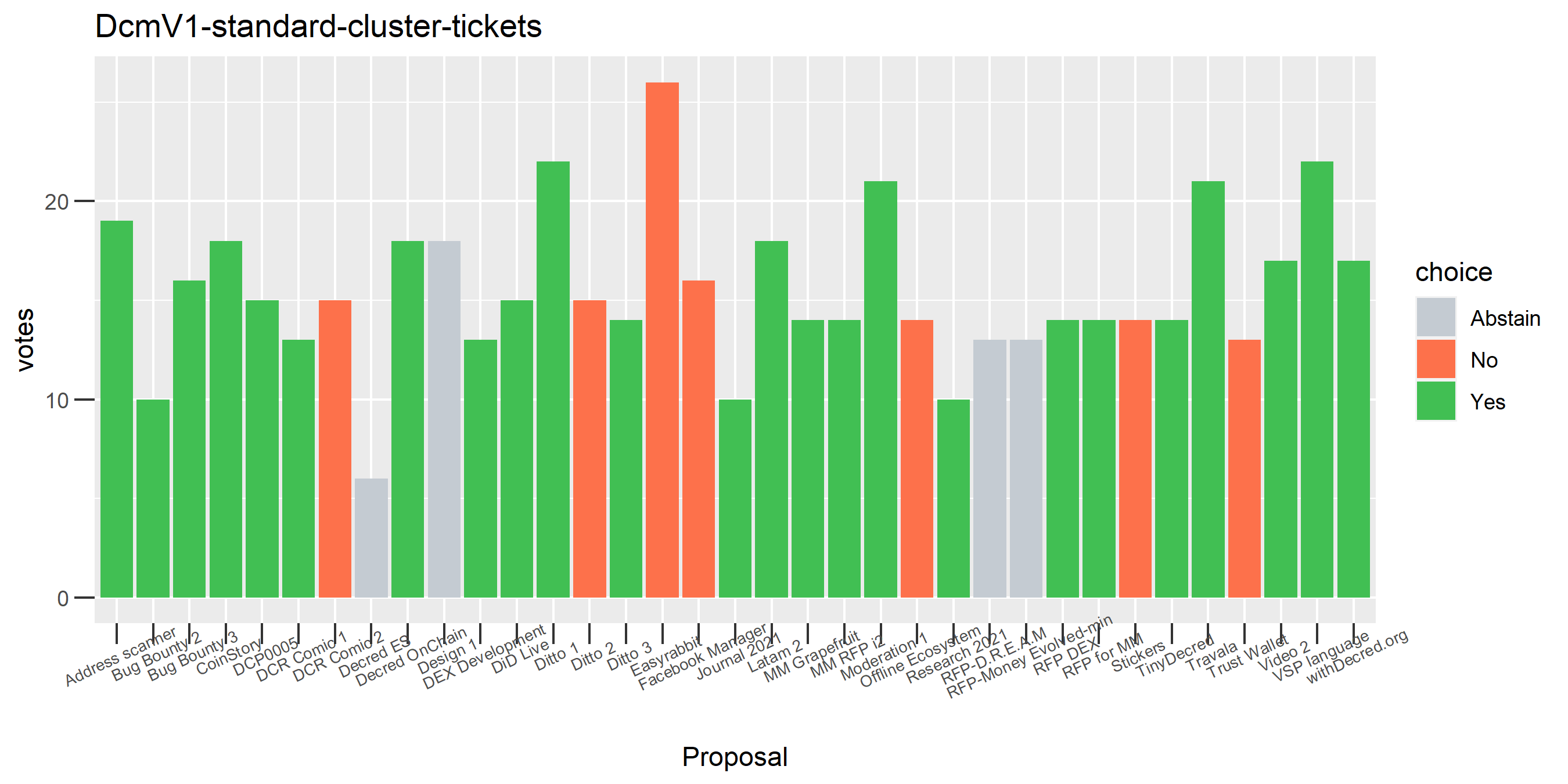
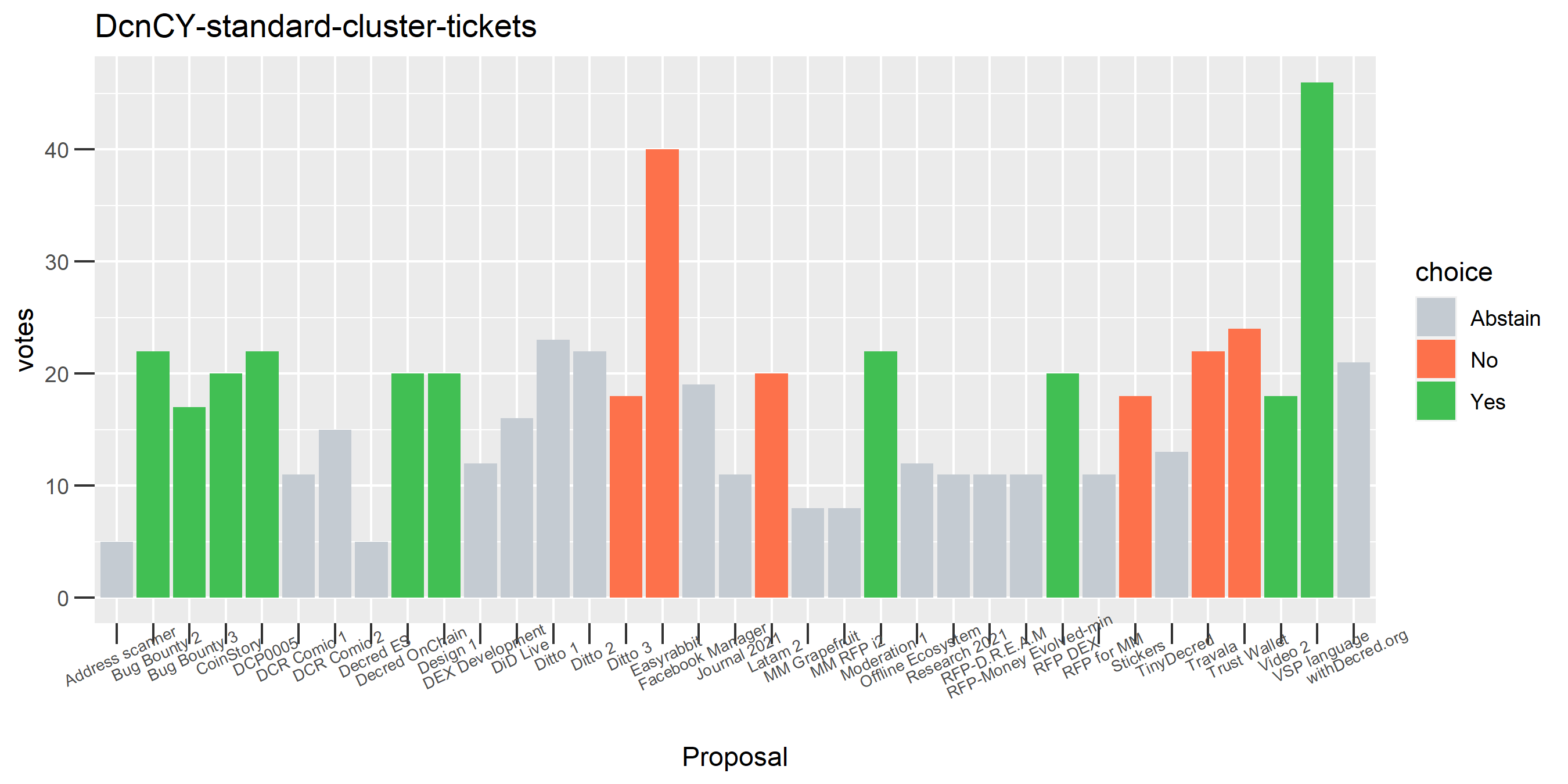
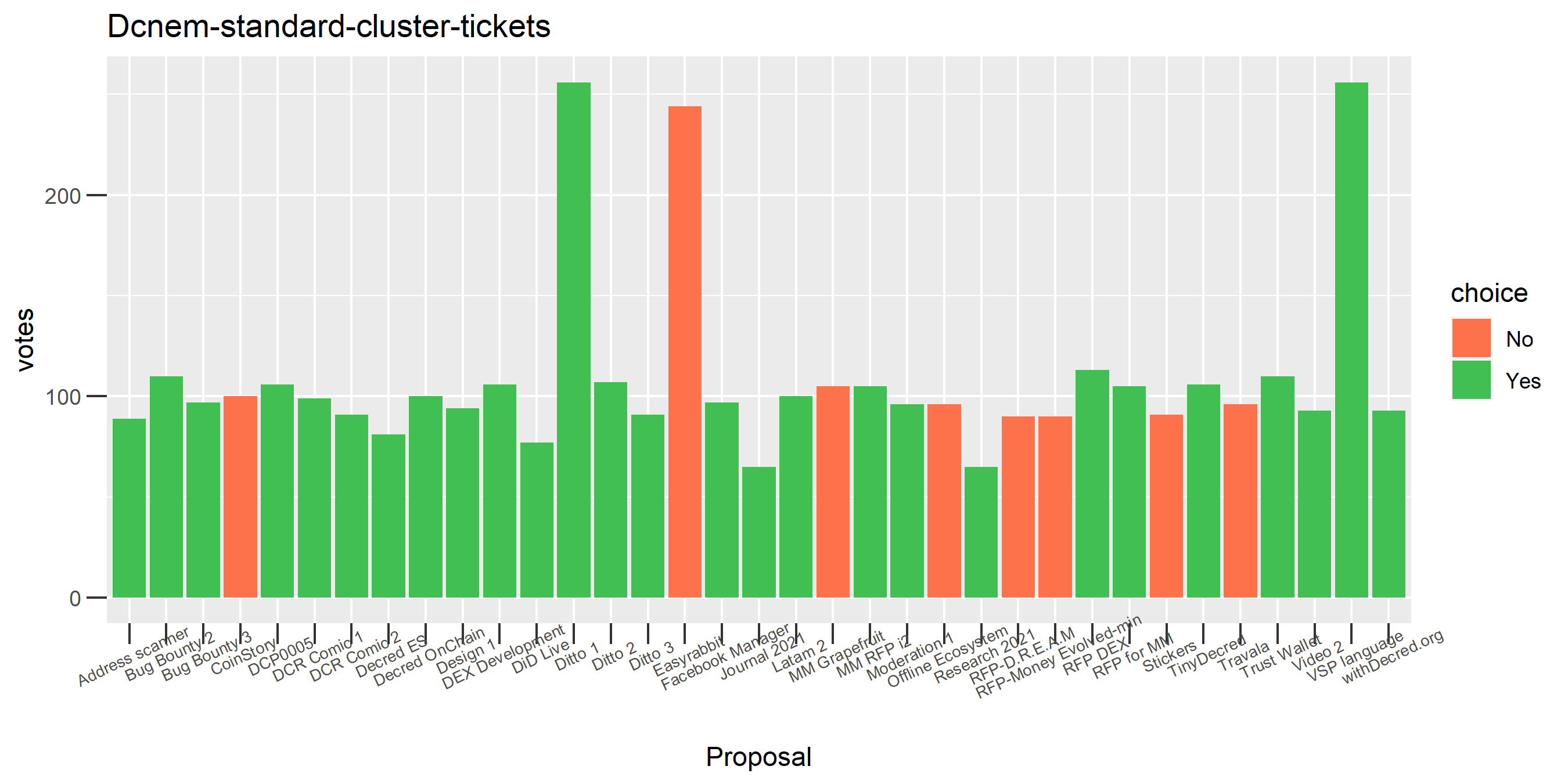
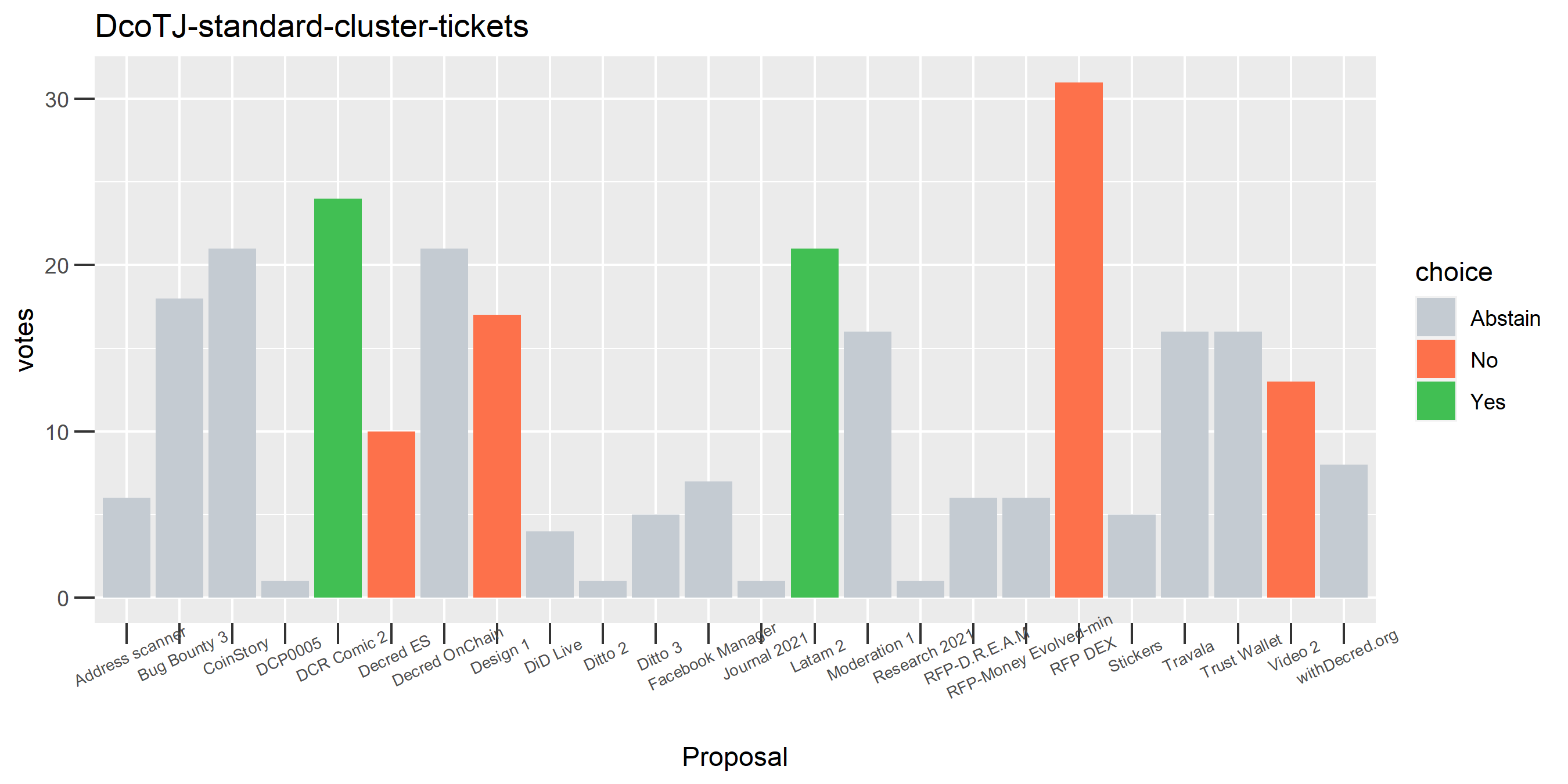
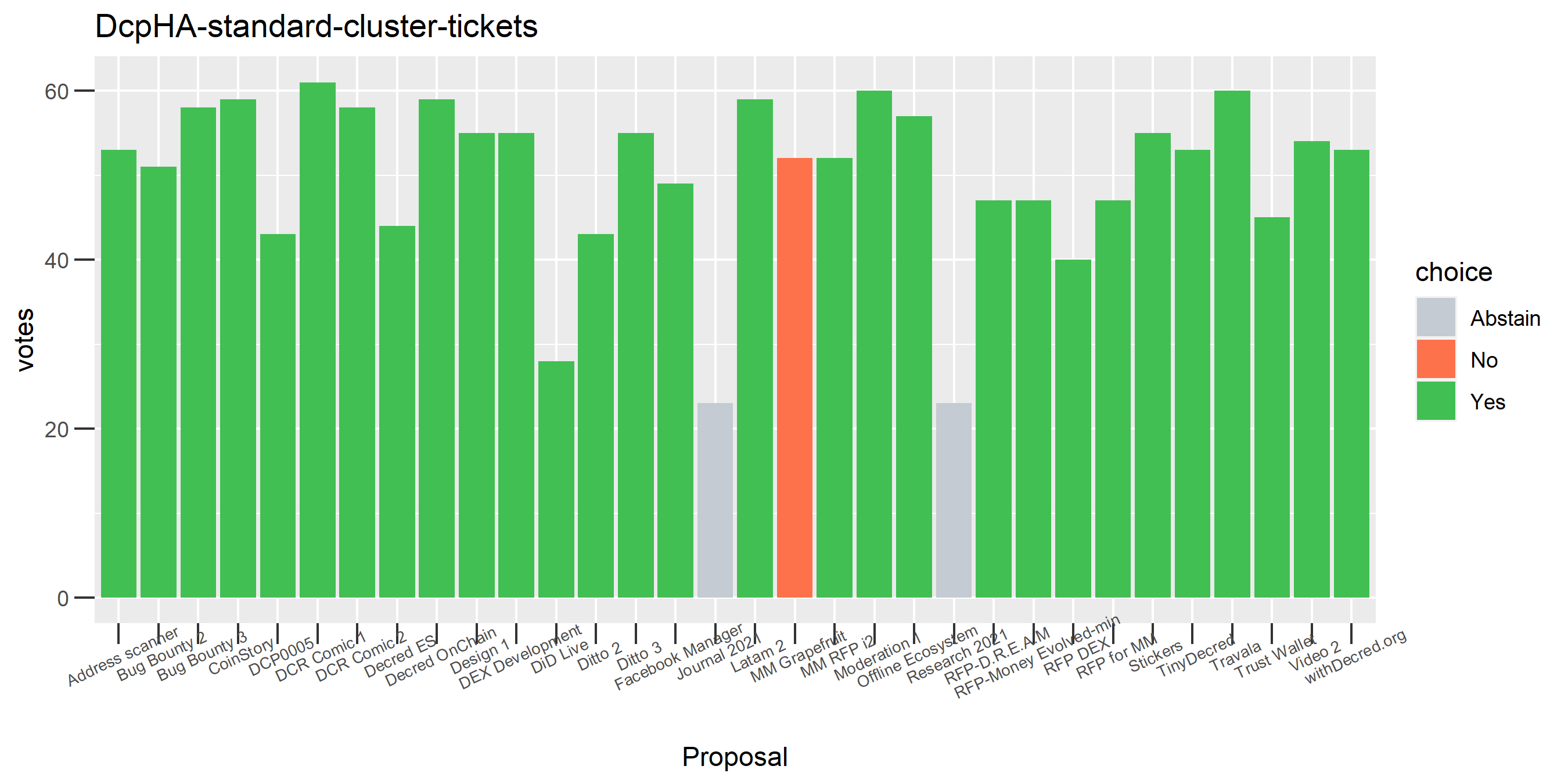
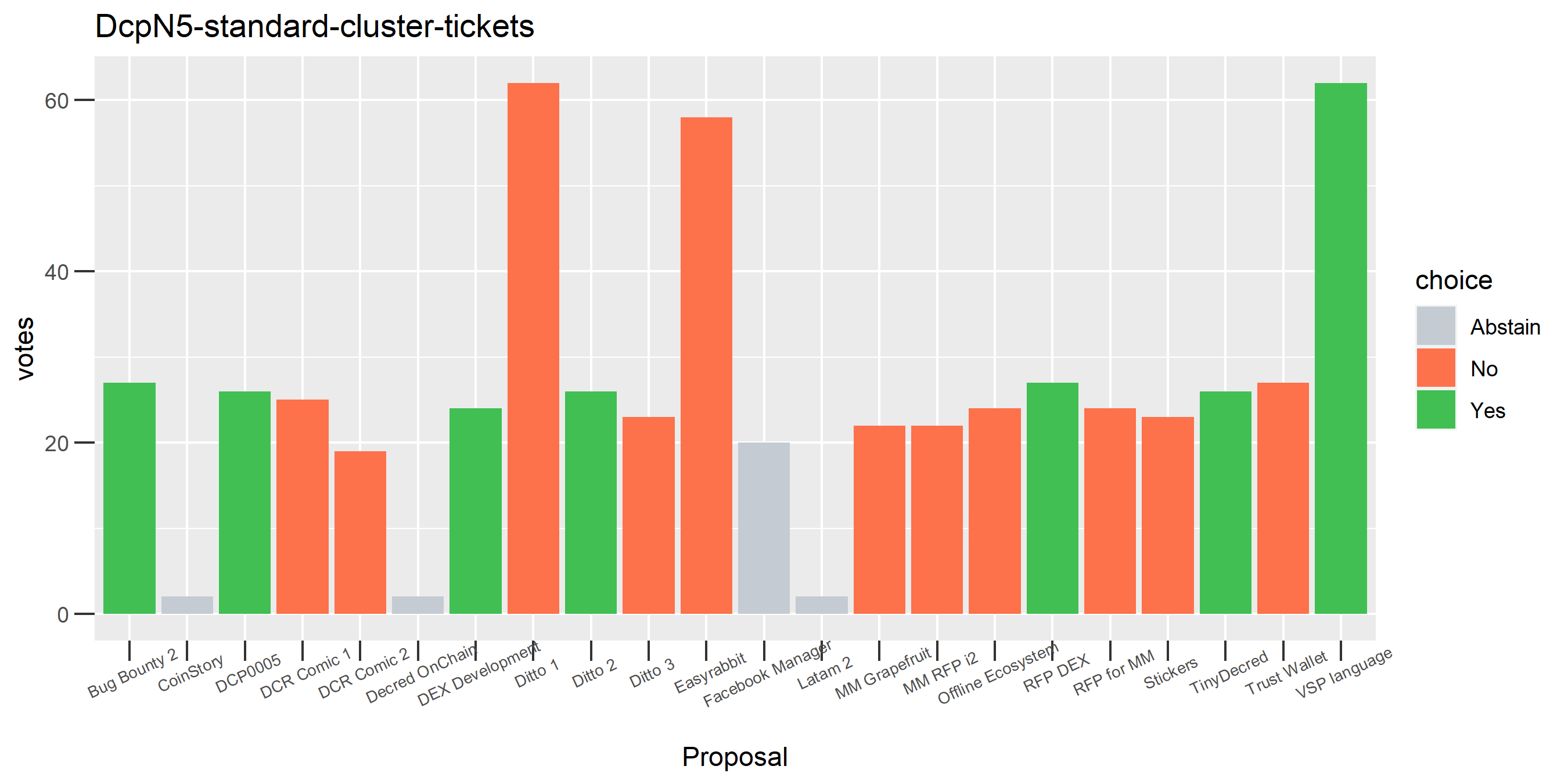
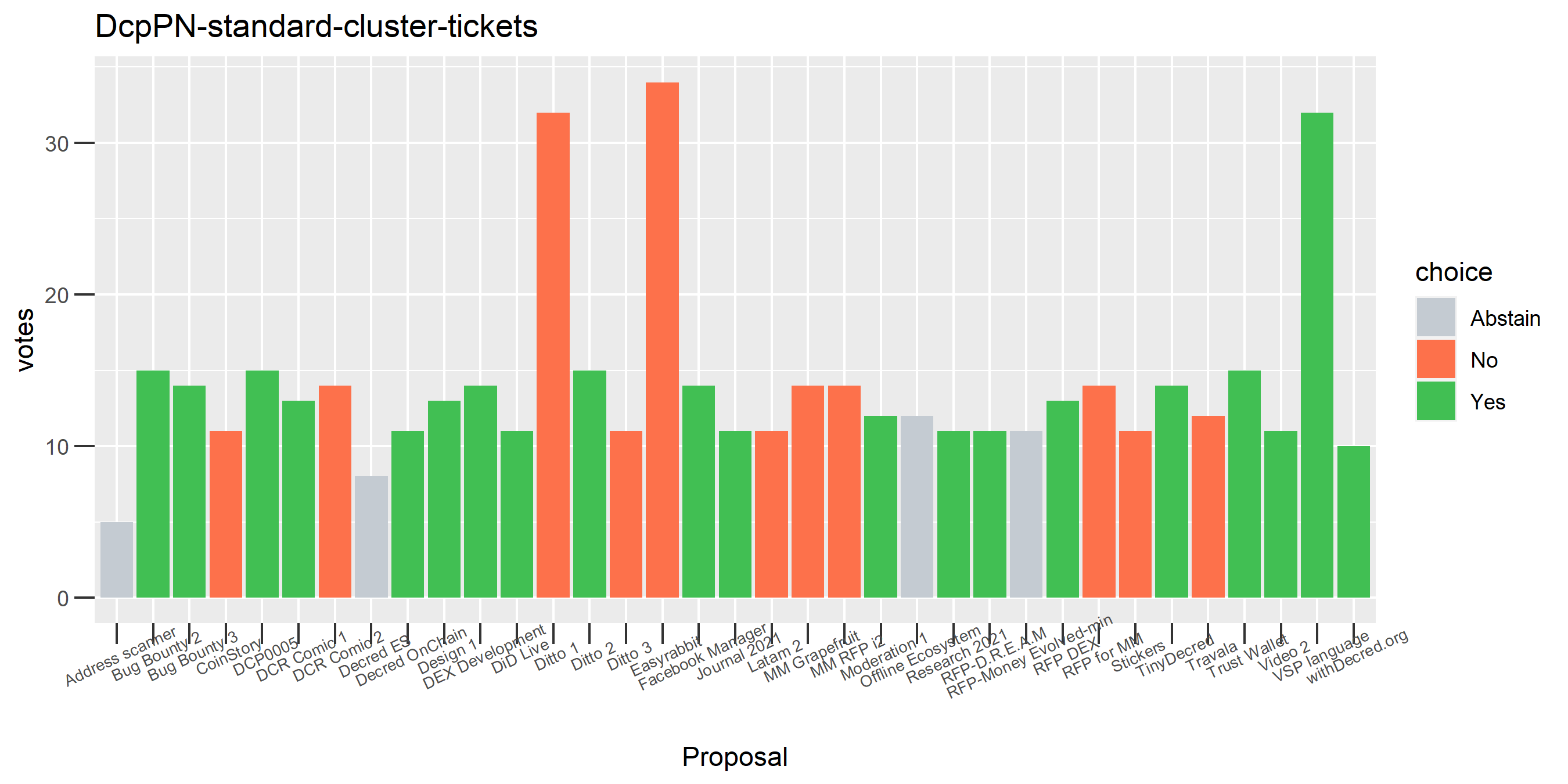
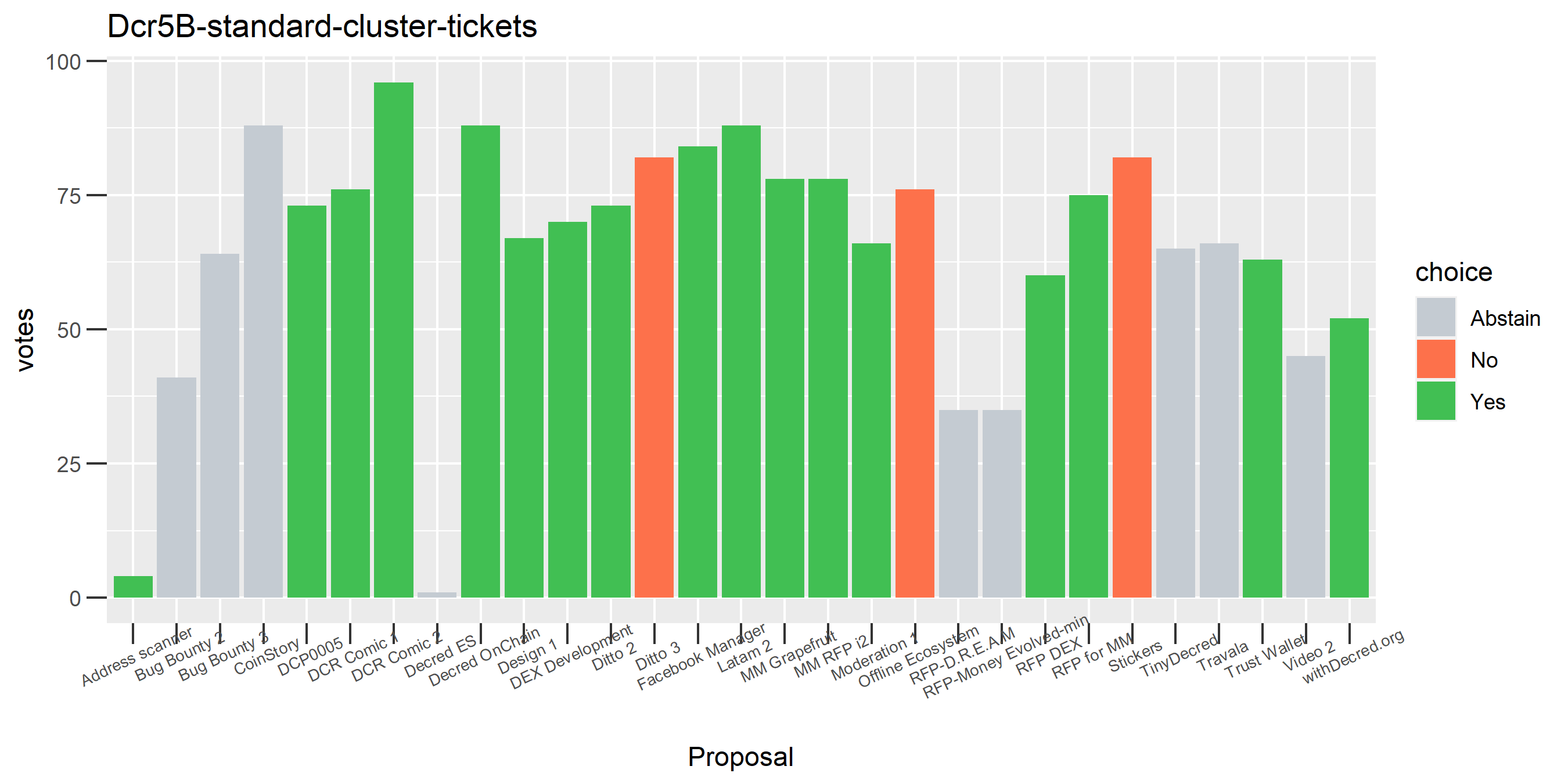
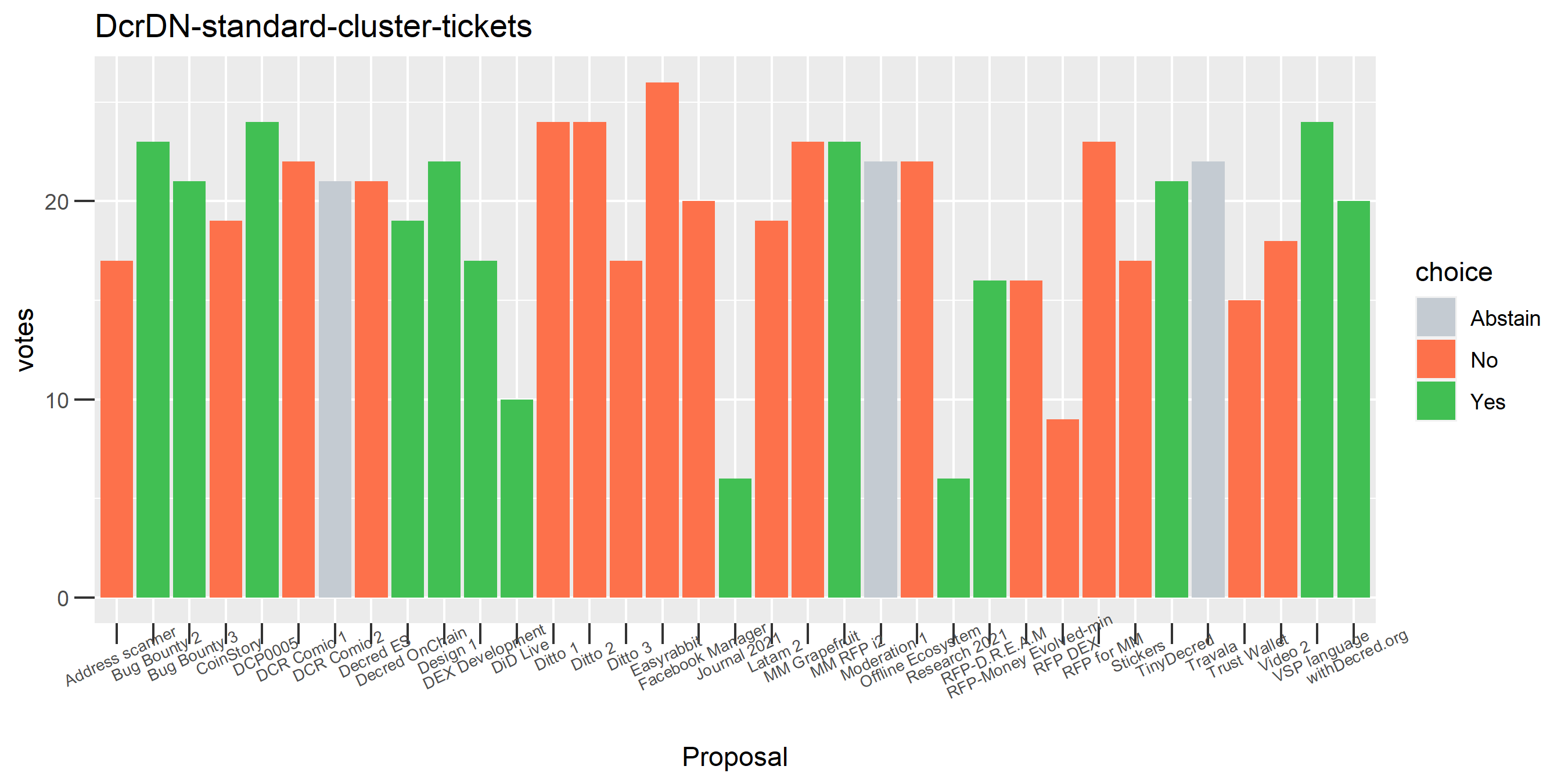
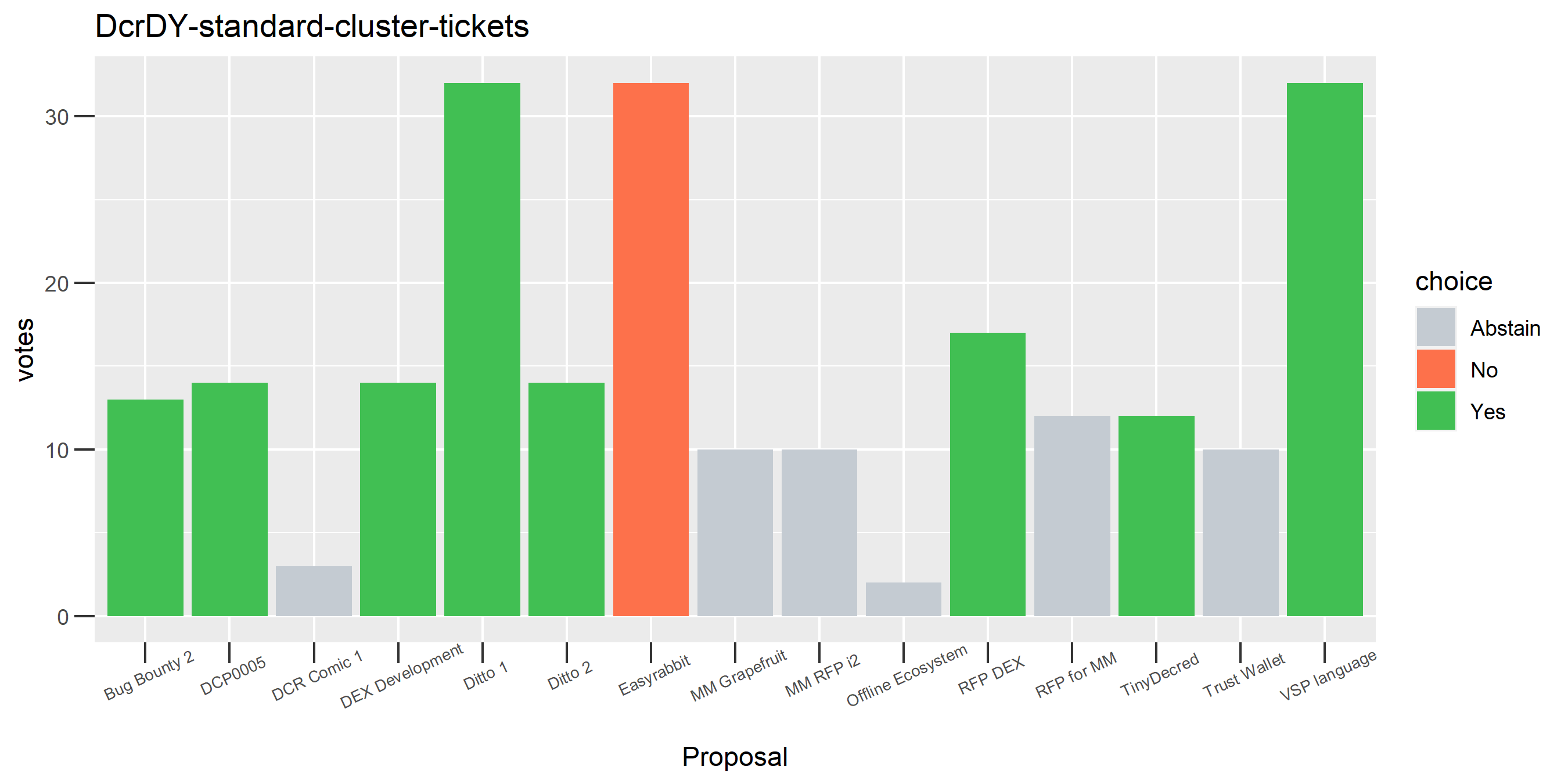
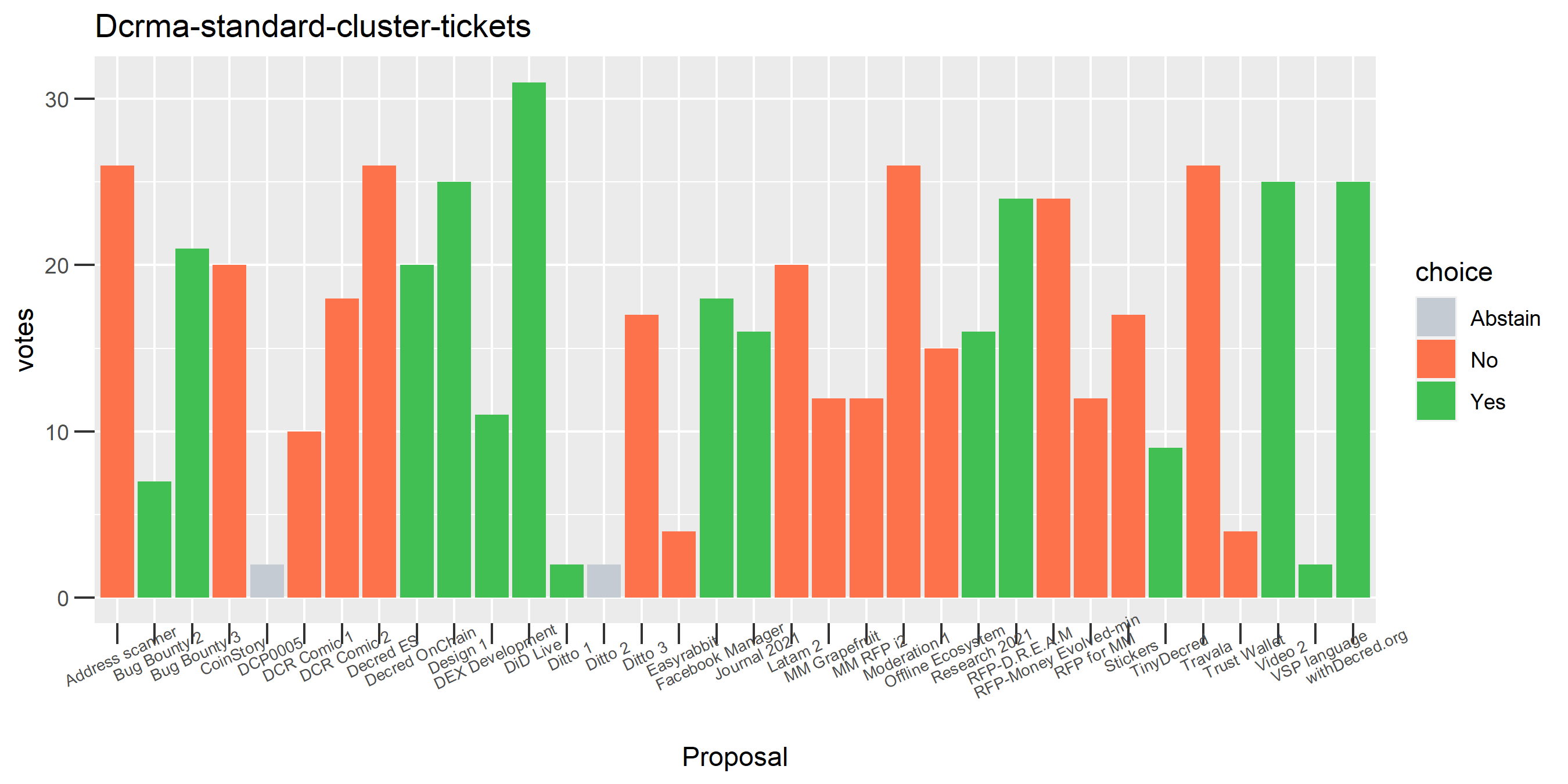
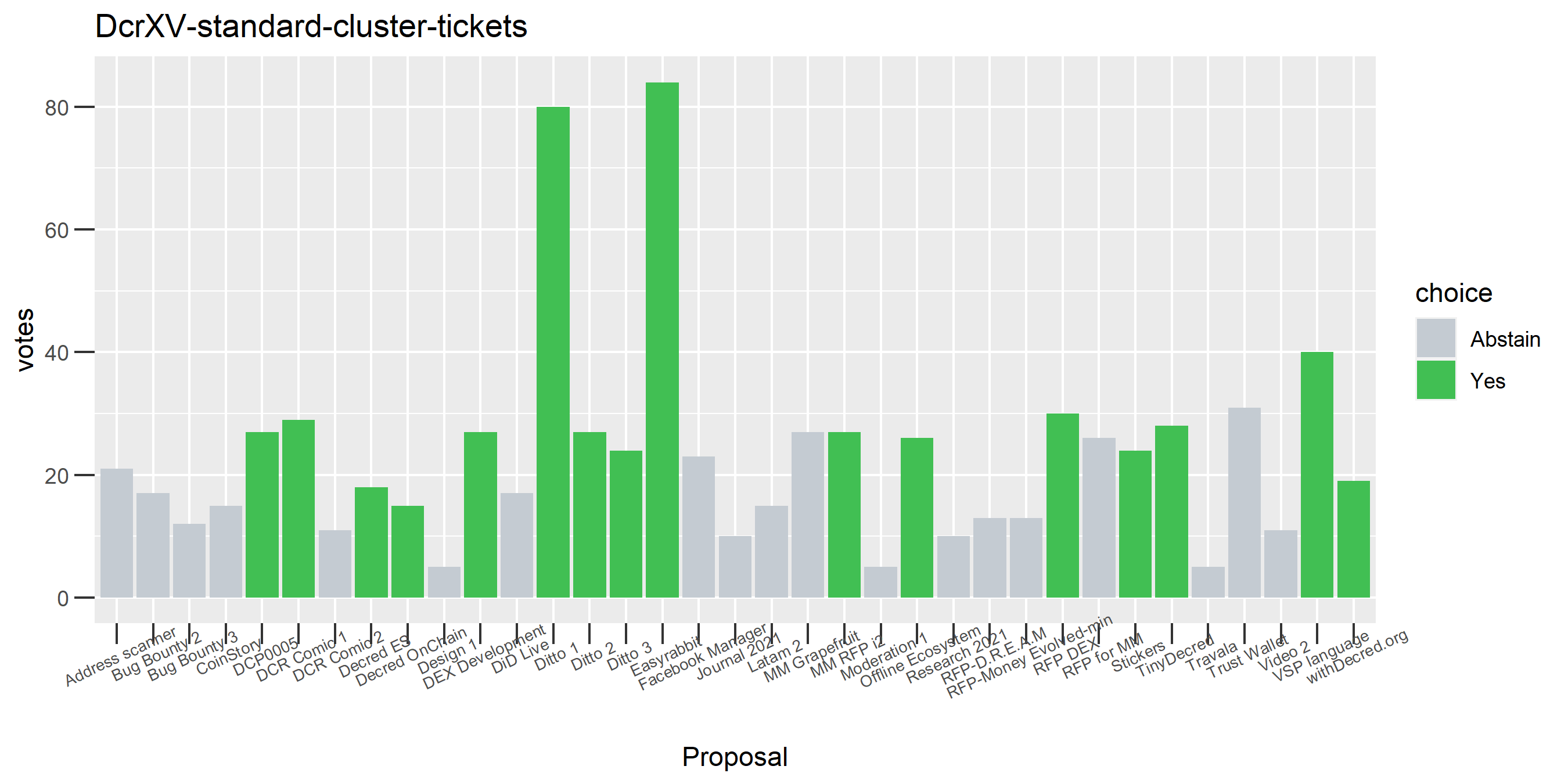
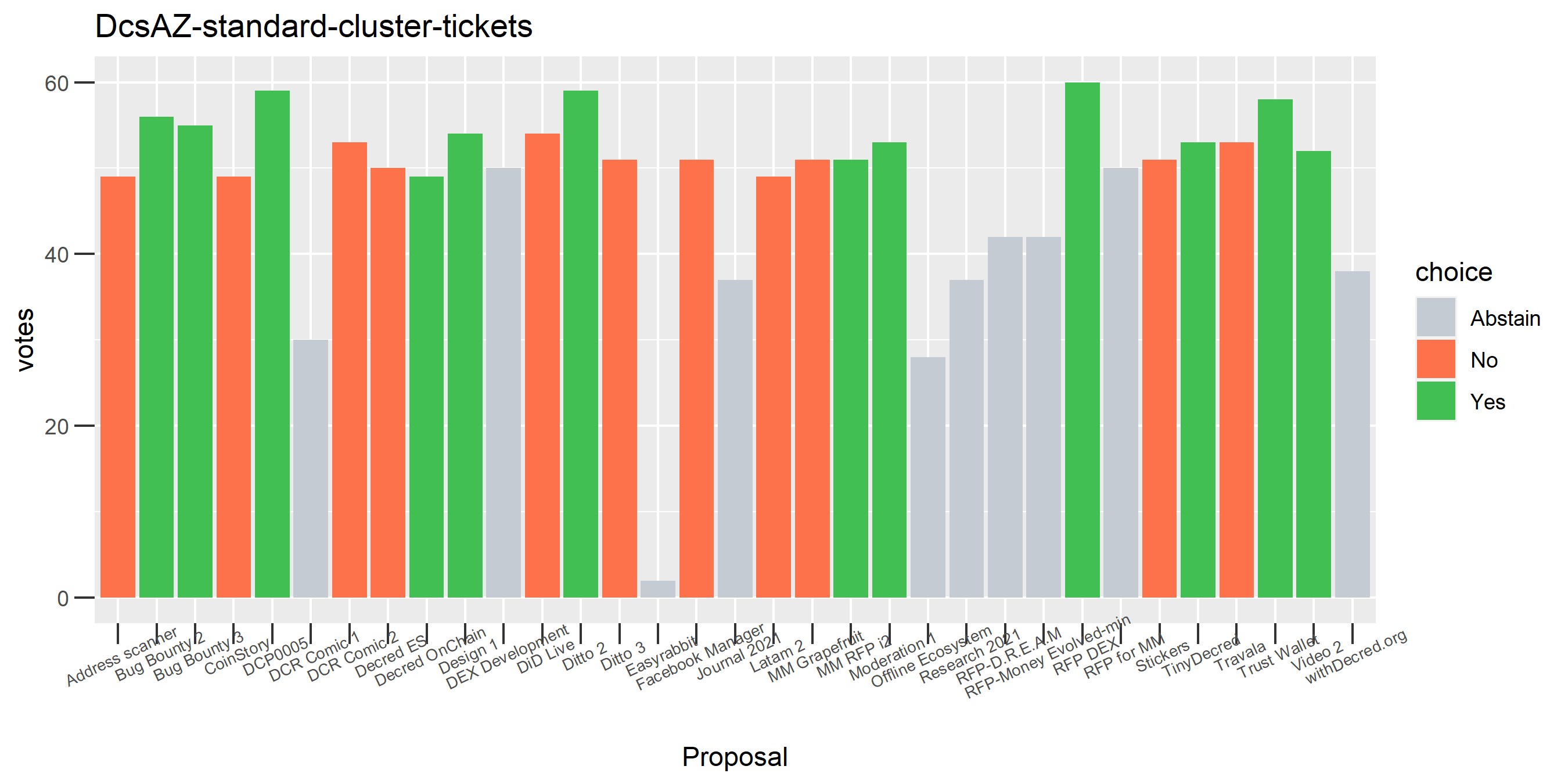
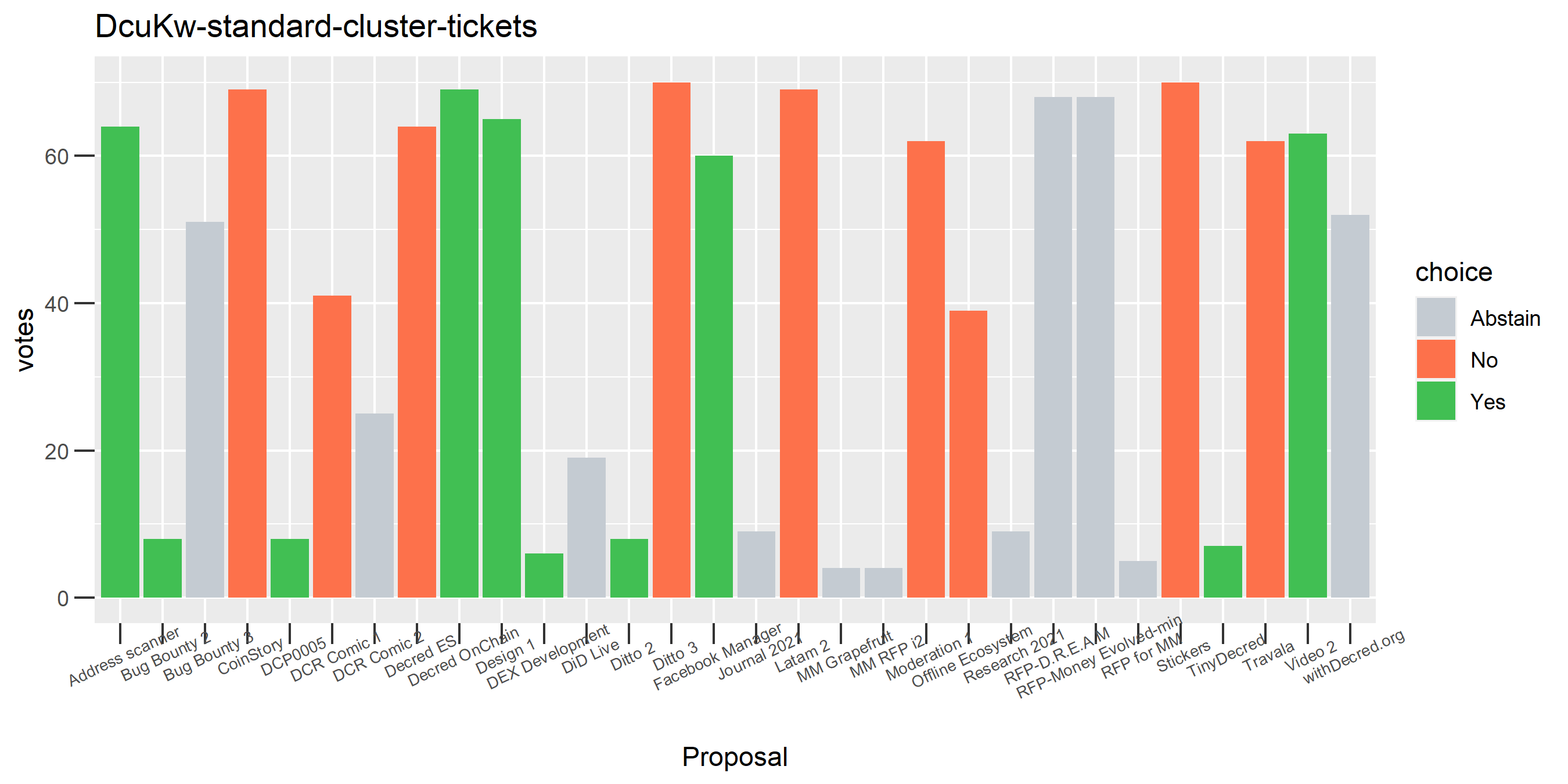
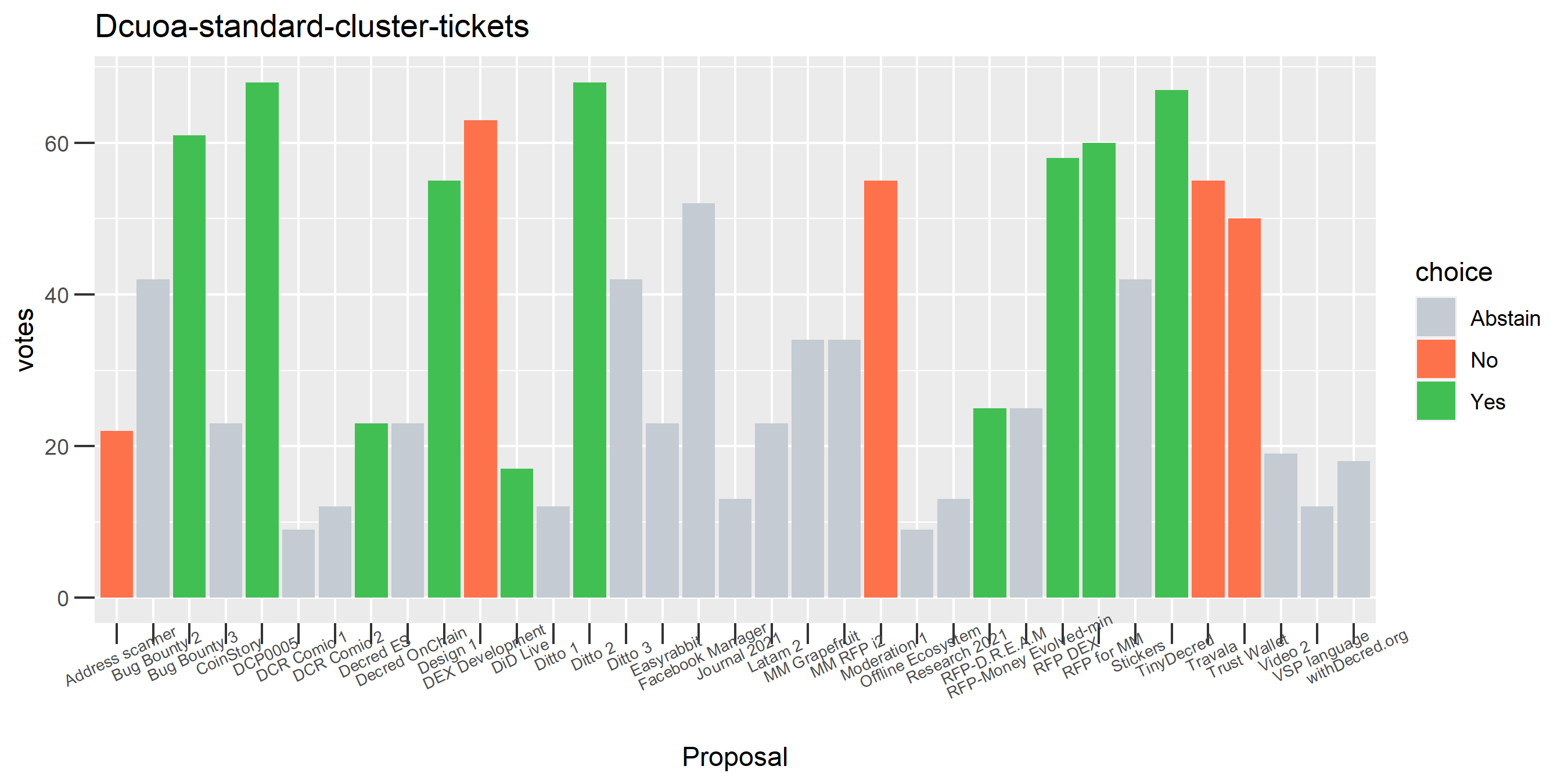
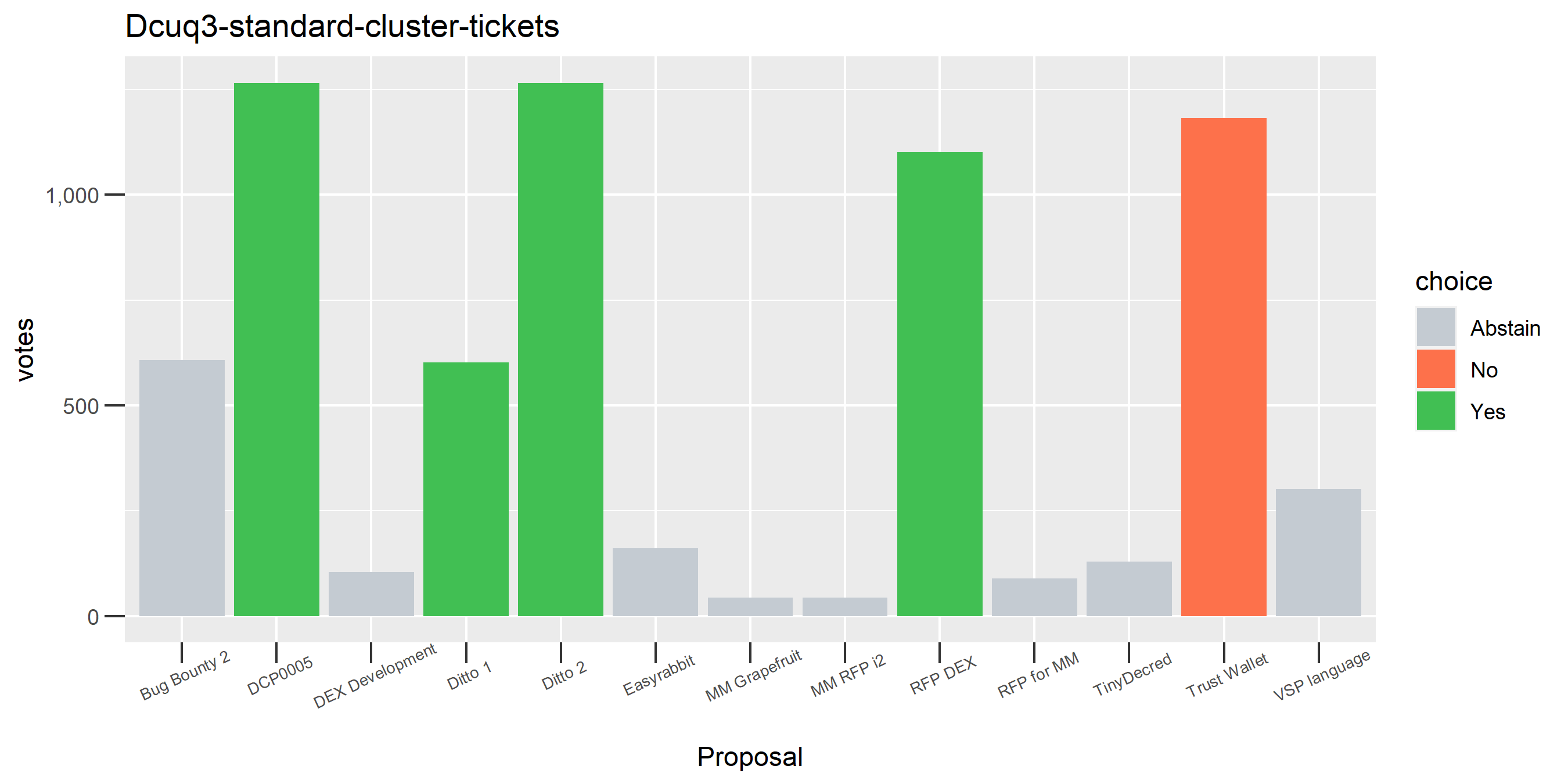
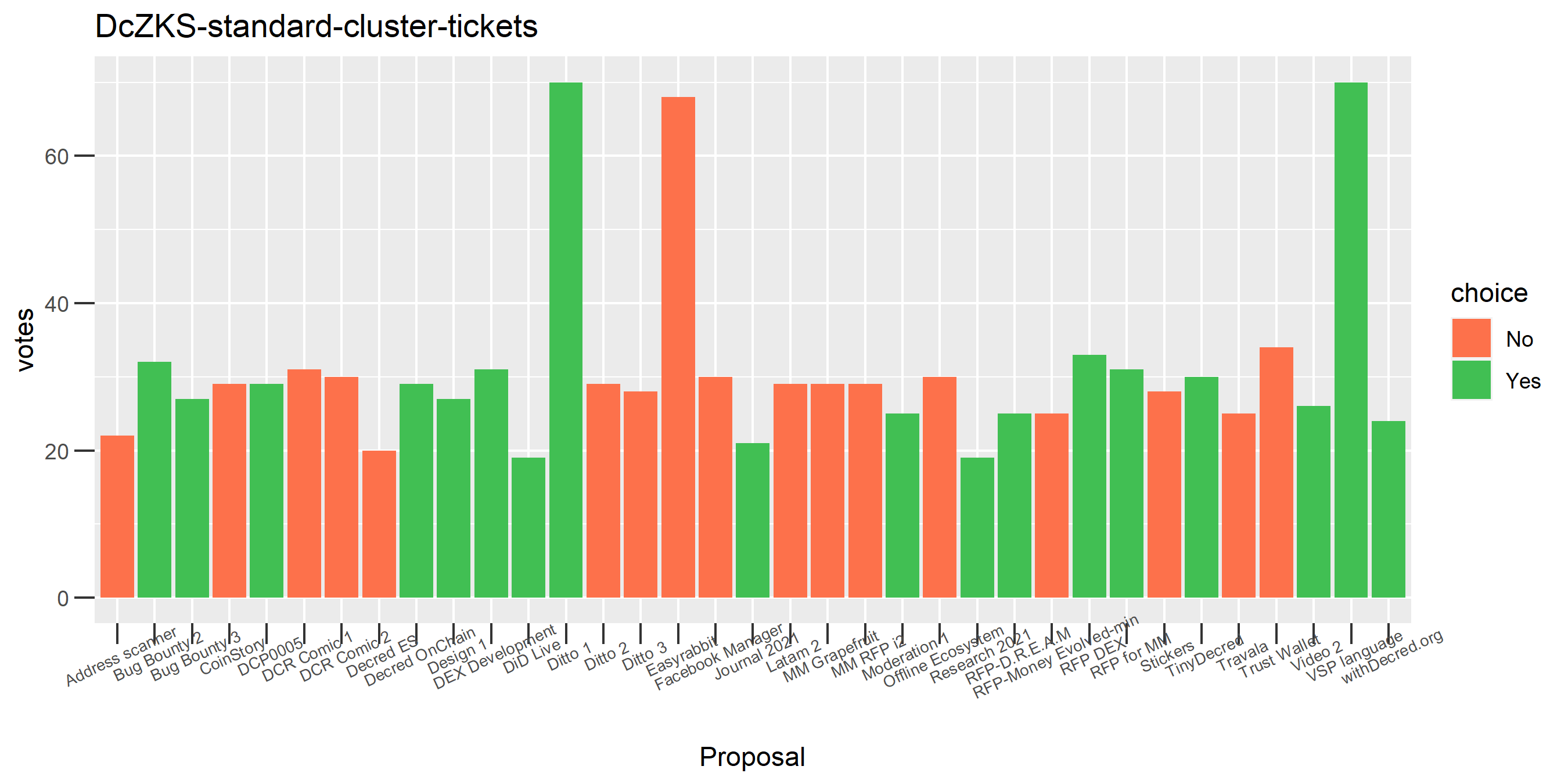
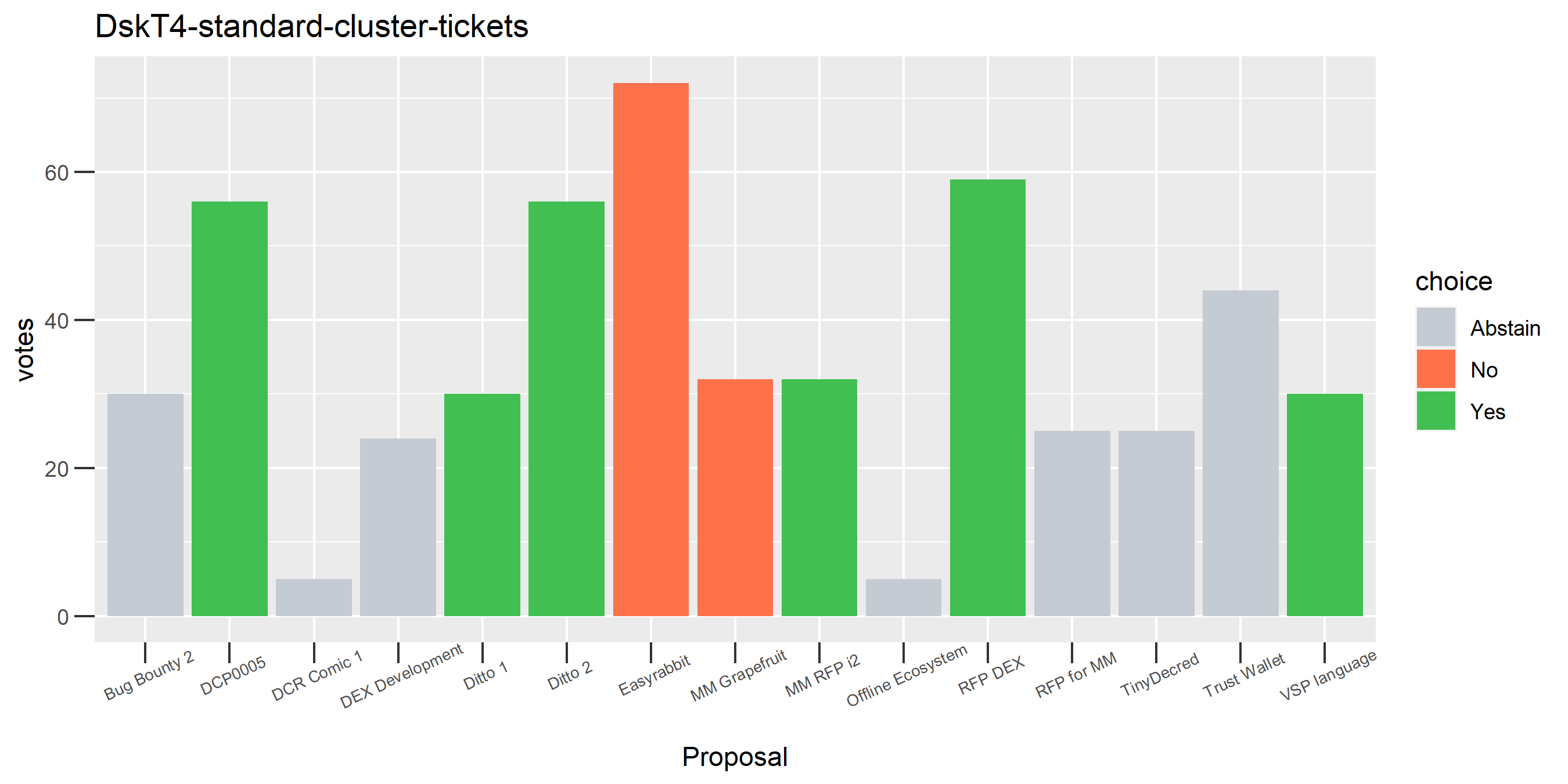
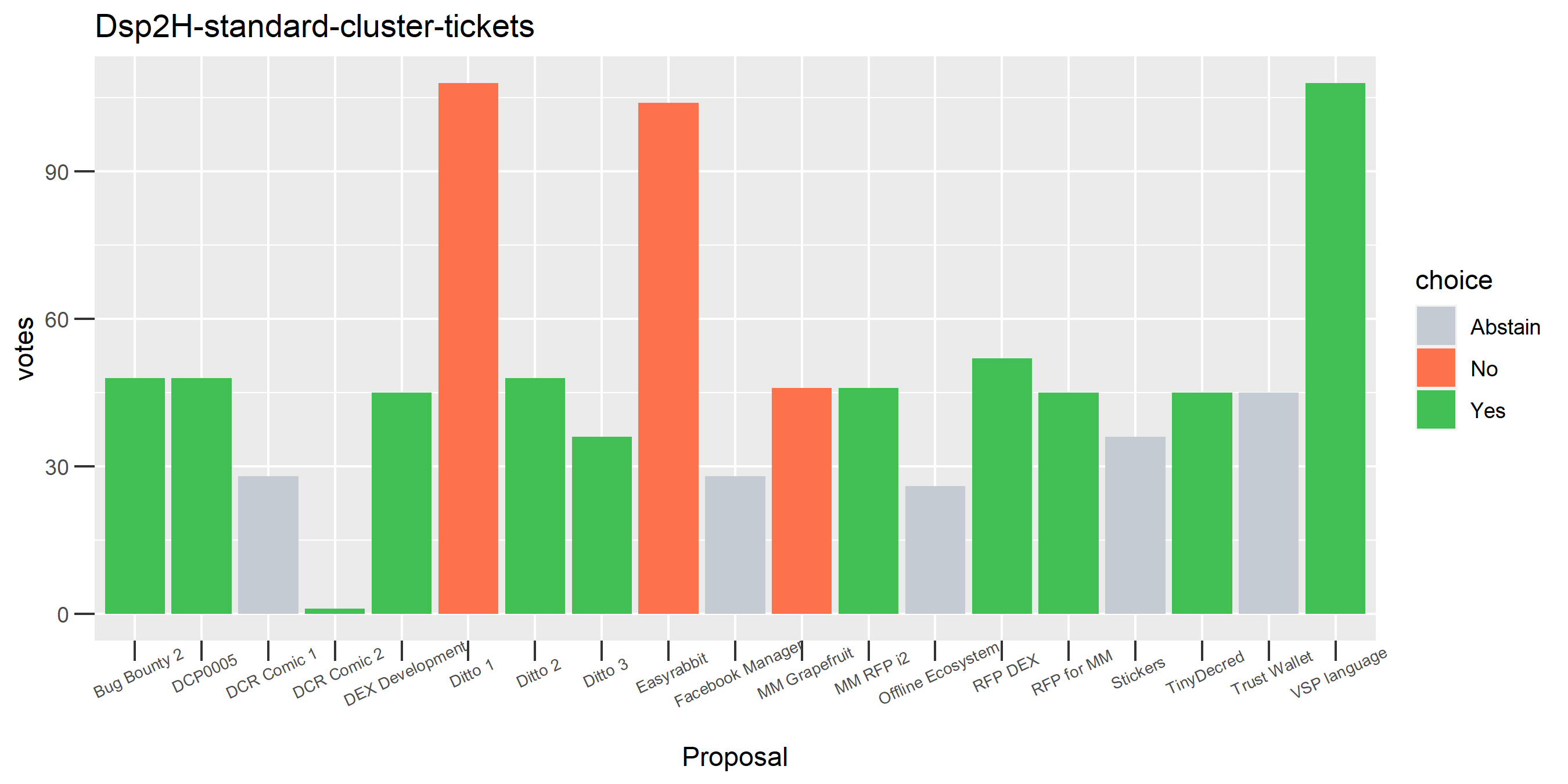
The rest of these voting plots are provided to demonstrate the robustness of the clustering, and some insights into the voting behavior of stakeholders can also be derived. I have selected clusters with a lot of tickets and/or long voting record or some other pattern which caught my eye. They are listed in alphabetical order.